







 本文详细介绍了使用Java实现基于Raft算法的分布式KV存储项目,涵盖选举、日志复制、动态成员变更、自定义RPC等方面,确保在复杂分布式环境中数据强一致性。项目通过实现一致性模块、日志模块、状态机接口等,遵循Raft算法的核心思想,以保证集群节点间的数据同步和一致性。
本文详细介绍了使用Java实现基于Raft算法的分布式KV存储项目,涵盖选举、日志复制、动态成员变更、自定义RPC等方面,确保在复杂分布式环境中数据强一致性。项目通过实现一致性模块、日志模块、状态机接口等,遵循Raft算法的核心思想,以保证集群节点间的数据同步和一致性。
本文讲的是使用 Java 语言实现基于 Raft 算法的,分布式的,KV 结构的存储项目。该项目的目标是:在复杂的分布式环境中,多个存储节点能够保证数据强一致性
目录
项目链接(新增了自己实现的RPC框架)
GitHub - zhangqingqing24630/raft-kv: 功能:领导者选举,日志同步,成员变更,自定义RPC
why要做这个项目?
学习了raft协议,相当于可以自己在项目中实现分布式功能,而不是仅仅为了实现分布式这一功能而引入Zookeepr或redis集群等现成的中间件,反而增加复杂性。
项目介绍
Raft 为了算法的可理解性,将算法分成了 4 个部分。
- leader 选举
- 日志复制
- 动态成员变更
- 底层使用RPC框架通信(法一:蚂蚁金服 SOFA-Bolt,法二:自己实现的RPC框架)
技术选型
Raft 核心组件包括:一致性模块,RPC 通信,日志模块,状态机。
- 一致性模块,是 Raft 算法的核心实现,通过一致性模块,保证 Raft 集群节点数据的一致性。这里我们需要自己根据论文描述去实现。
- RPC 通信,可以使用 HTTP 短连接,也可以直接使用 TCP 长连接,考虑到集群各个节点频繁通信,同时节点通常都在一个局域网内,因此我们选用 TCP 长连接。而 Java 社区长连接框架首选 Netty,这里我们选用蚂蚁金服网络通信框架 SOFA-Bolt(基于 Netty),后面也新增了自定义的RPC框架。
- 日志模块,Raft 算法中,日志实现是基础,我们选用 RocksDB 作为日志存储。 这个日志你可以理解成 mysql 的 binlog模块。为啥底层 KV 存储使用的是 RocksDB,相比Mysql适合写少读多的环境, RocksDB利用了追加写而非随机写的特性,它达到了写与读的平衡。
- 状态机,可以是任何实现,其实质就是将日志中的内容进行处理。可以理解为 Mysql binlog 中的具体数据。由于我们是要实现一个 KV 存储,那么可以直接使用日志模块的 RocksDB 组件。
接口设计
上面我们说了 Raft 的几个核心功能,事实上,就可以理解为接口。所以我们定义以下几个接口:
1 Consensus, 一致性模块接口
该接口实现请求投票 & 附加日志。也就是Raft 节点的核心功能,leader 选举和 日志复制。
//请求投票 RPC
RvoteResult requestVote(RvoteParam param);
//附加日志(多个日志,为了提高效率) RPC
AentryResult appendEntries(AentryParam param);2 LogModule,日志模块接口
该接口实现日志的写,读,删,最后是两个关于 Last 的接口
//写日志
void write(LogEntry logEntry);
//读日志
LogEntry read(Long index);
//移出从offset开始的日志
void removeOnStartIndex(Long startIndex);
//获取最后的日志
LogEntry getLast();
//获取最后的日志索引
Long getLastIndex();3 StateMachine, 状态机接口
该接口实现将已成功提交的日志应用到状态机中
//将数据应用到状态机.
void apply(LogEntry logEntry);
LogEntry get(String key);
String getString(String key);
void setString(String key, String value);
void delString(String... key);4 RpcServer & RpcClient, RPC 接口
RpcClient 和 RPCServer 没什么好讲的,其实就是 send 和 receive
5 Node,同时,为了聚合上面的几个接口,我们需要定义一个 Node 接口,即节点
//设置节点信息
void setConfig(NodeConfig config);
//处理请求投票 RPC.
RvoteResult handlerRequestVote(RvoteParam param);
//处理附加日志请求.
AentryResult handlerAppendEntries(AentryParam param);
//处理客户端请求.
ClientKVAck handlerClientRequest(ClientKVReq request) throws ExecutionException, InterruptedException, TimeoutException;
//重定向转发给 leader 节点.
ClientKVAck redirect(ClientKVReq request) throws ExecutionException, InterruptedException, TimeoutException;
6 LifeCycle, 最后,我们需要管理以上组件的生命周期,因此需要一个 LifeCycle 接口。
//节点的生命周期初始化
void init() throws Throwable;
//节点的销毁
void destroy() throws Throwable;算法设计
Leader选举的实现篇
选举,其实就是一个定时器,根据 Raft 论文描述,如果超时了就需要重新选举,我们使用 Java 的定时任务线程池进行实现。
发起者在发起“请求投票” RPC 后,需要做以下事情:
- 选举者必须不是 leader。
- 必须超时了才能选举,具体超时时间根据你的设计而定,注意,每个节点的超时时间不能相同,应当使用随机算法错开(Raft 关键实现),避免无谓的死锁。
- 选举者优先选举自己,将自己变成 candidate。
- 选举的第一步就是把自己的 term 加一。
- 然后像其他节点发送请求投票 RPC,请求参数参照论文,包括自身的 term,自身的 lastIndex,以及日志的 lastTerm。同时,请求投票 RPC 应该是并行请求的。
- 等待投票结果应该有超时控制,如果超时了,就不等待了。
- 最后,如果有超过半数的响应为 success,那么就需要立即变成 leader ,并发送心跳阻止其他选举。
- 如果失败了,就需要重新选举。注意,这个期间,如果有其他节点发送心跳,也需要立刻变成 follower,否则,将死循环
具体代码,可参见 DefaultNode.java
![]()
接收者在收到“请求投票” RPC 后,需要做以下事情:
- 注意,选举操作应该是串行的,因为涉及到状态修改,并发操作将导致数据错乱。也就是说,如果抢锁失败,应当立即返回错误。
- 首先判断对方的 term 是否小于自己,如果小于自己,直接返回失败。
- 如果当前节点没有投票给任何人,或者投的正好是对方,那么就可以比较日志的大小,反之,返回失败。
- 如果对方日志没有自己大,返回失败。反之,投票给对方,并变成 follower。变成 follower 的同时,异步的选举任务在最后从 condidate 变成 leader 之前,会判断是否是 follower,如果是 follower,就放弃成为 leader。这是一个兜底的措施。
到这里,基本就能够实现 Raft Leader 选举的逻辑。
具体代码,可参见 DefaultConsensus.java

如何避免脑裂现象?
1 一个节点在一个任期只能投一票
2 选举和同步日志时的过半机制,即,即使有两个leader,集群少的leader所接收的请求也无法得到大多数节点的同意,无法同步日志。
保证了不可能出现两个候选者同时获胜的情况
举个例子。发生了网络分区或者心跳包延时到达,使得Leader不能访问大多数Follwer了,那么Leader只能正常更新它能访问的那些Follower,而大多数的Follower因为没有了Leader,他们重新选出一个Leader,然后这个 Leader来接受客户端的请求,如果客户端要求其添加新的日志,这个新的Leader会通知大多数Follower。如果这时网络故障修复 了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新(递减查询匹配日志)。
总结
接收者 -->成功投票给发起者(接收者的任期号更新为为发起者的任期号)
--> 不投票给发起者(发起者的任期号更新为接收者节点最大的任期号)
发起者--> 收到的票过半(升级为leader,集群中其他节点的任期号更新为和我一样)
--> 不过半 --> 达到超时时间,重新发起投票
--> 接收到心跳 --> 发起心跳的节点任期号<我,我不更新超时时间
--> 发起心跳的节点任期号>=我,我更新超时时间,变为follower
投票条件
candiate最后一条日志的任期>我,且candiate的票还没有投出去
或candiate最后一条日志的任期=我,但是candiate最后一条日志的索引>我
只有这样,我才把票投给candiate
这种竞选操作,保证了只有消息最新最全的才能成为leader
心跳篇
当有candiate晋升为leader时,会立即向其他Node节点发送心跳。
再总结总结心跳的步骤
接收者接收心跳
follower接收心跳后会向leader返回自己的任期号-->对方的term>我,我变为follower,更新超时时间,无限延长自己的发起投票时间,更新follower的任期号为leader任期号
-->对方的term<我,我不会延长自己的投票时间,到期我发起投票
具体代码,可参见 DefaultConsensus.java
发送方处理返回心跳信息
发送方发送心跳后会接收follower返回的任期号-->对方的term>我,我降级为follower,把我的term号更新为follower任期号一样。
-->对方的term<=我,无操作
你应该只在以下情况下重启你的选举AppendEntries计时器:a) 您正在开始选举;或 b) 您将投票权授予另一个同行。c)收到日志(心跳),且日志传来的term大于我自身的term
具体代码,可参见 DefaultNode.java
![]()
日志同步篇
简单来说,客户端将命令发送给领导者,领导者首先将命令写入它自己的日志中,然后向所有其他的跟随者发送 AppendEntries 的远程调用。一旦领导者收到足够多的响应,可以它认为该条命令已经在多数服务器上处于已提交状态时,那么该条命令就可以被执行。领导者这时会将命令发送给状态机,当执行结束后,它会将结果返回给客户端。
不仅如此,一旦服务器知道某个记录已经处于提交状态,它就会通过后续的 AppendEntries 远程调用告知其他的服务器。所以最终,每个跟随者都会知道该记录已提交,并且将该命令发送至自己本地的状态机执行。如果跟随者崩溃了或处于慢响应状态,领导者会反复重试这个调用,直到跟随者恢复后,领导者就能重试成功。但是领导者并不需要等待每个跟随者的响应,它只需要等到足够数量的响应,保证记录已被大多数服务器存储即可。所以这样就能在一般情况下获得很好的性能提升。也就是说,如果某个服务器很慢,这并不能影响客户端获得响应的速度,因为领导者并不需要一直等待该台服务器。
因此,Leader 节点会有一个 ClientKVAck handlerClientRequest(ClientKVReq request) 接口,用于接收用户的 KV 数据,同时,会并行向其他节点复制数据,具体步骤如下:
- 每个节点都可能会接收到客户端的请求,但只有 leader 能处理,所以如果自身不是 leader,则需要转发给 leader。
- 然后将用户的 KV 数据封装成日志结构,包括 term,index,command,预提交到本地。
- 并行的向其他节点发送数据,也就是日志复制。
- 如果在指定的时间内,过半节点返回成功,那么就提交这条日志,并返回给客户端,如果没有follower宕机,leader会不断重试,直到所有follower复制了所有日志条目,限定时间内如果没有得到过半节点的ack,leader会撤销这条日志。
- 最后,更新自己的 commitIndex,lastApplied 等信息。
注意,复制不仅仅是简单的将这条日志发送到其他节点,为了保证复杂网络环境下的一致性,Raft 保存了每个节点的成功复制过的日志的 index,即 nextIndex ,因此,如果对方之前一段时间宕机了,那么,从宕机那一刻开始,到当前这段时间的所有日志,都要发送给对方。
甚至于,如果对方觉得你发送的日志还是太大,那么就要递减的减小 nextIndex,复制更多的日志给对方,这就是一致性检查。注意:这里是 Raft 实现分布式一致性的关键所在。
一致性检查:当 leader 和 follower 日志冲突的时候,leader 将校验 follower 最后一条日志是否和 leader 匹配,如果不匹配,将递减查询,直到匹配,匹配后,删除冲突的日志。这样就实现了主从日志的一致性。
再来看看日志接收者的实现步骤:
- 和心跳一样,要先检查对方 term,如果 term 都不对,那么就没什么好说的了。
- 如果日志不匹配,那么返回 leader,告诉他,减小 nextIndex 重试。
- 如果本地存在的日志和 leader 的日志冲突了,以 leader 的为准,删除自身的。
- 最后,将日志应用到状态机,更新本地的 commitIndex,返回 leader 成功。
总结
Leader选出后,就开始接收客户端的请求。Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他服务器发起 AppendEntries RPC 复制日志条目。当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机并向客户端返回执行结果。
同步日志时,会比较follower和leader的任期,会用上一条日志做一致性检查(这里涉及到日志的两条规定见下),删除followe从一致性点之后的所有日志条目,把leader节点之后的所有日志条目发送给follower,如果当前要添加的日志存在冲突,截断,会同步follower没有的日志,最终如果同步日志成功,follower会更新commitindex,为leadercommit和followercommit的最小值,失败,因为一致性检查失败的,退回nextindex,其他原因还有任期大于leader任期失败的。当选出一个新 leader 时,该 leader 将所有 nextIndex 的值都初始化为自己最后一个日志条目的 index 加1,commit index设置为0.然后如果一致性失败,leader会不断较少next index,并不断重试追加日志请求即,即nextIndex是不断回退的,commitIndex是增加的
Leader给每一个Follower维护了一个nextIndex,它表示Leader将要发送给该追随者的下一条日志条目的索引。当一个Leader开始掌权时,它会将nextIndex初始化为它的最新的日志条目索引数+1。如果一个Follower的日志和Leader的不一致,AppendEntries一致性检查会在下一次AppendEntries RPC时返回失败。在失败之后,Leader会将nextIndex递减然后重试AppendEntries RPC。最终nextIndex会达到一个Leader和Follower日志一致的地方。这时,AppendEntries会返回成功,Follower中冲突的日志条目都被移除了,并且添加所缺少的上了Leader的日志条目。一旦AppendEntries返回成功,Follower和Leader的日志就一致了,这样的状态会保持到该任期结束
Raft日志同步保证如下两点:
如果不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
如果不同日志中的两个条目有着相同的索引和任期号,则它们之前的所有条目都是完全一样的。
第一条特性源于Leader在一个term内在给定的一个log index最多创建一条日志条目,同时该条目在日志中的位置也从来不会改变。
第二条特性源于 AppendEntries 的一致性检查。跟随者只会接受与它日志匹配的远程调用,如果跟随者的日志没有相应的记录,那么它会拒绝这个远程调用
总结起来一句话:领导者 从来不会覆盖或者删除自己的日志!
如何避免日志覆盖现象?
一般情况下,Leader和Followers的日志保持一致,因此 AppendEntries 一致性检查通常不会失败。然而,Leader崩溃可能会导致日志不一致:旧的Leader可能没有完全复制完日志中的所有条目。
具体的操作是:Leader会从后往前试,每次AppendEntries失败后尝试前一个日志条目,直到成功找到每个Follower的日志一致位置点(基于上述的两条保证),然后向后逐条覆盖Followers在该位置之后的条目。
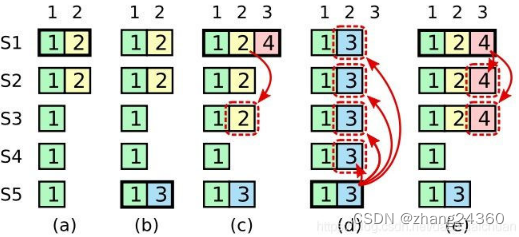
Raft增加了如下两条限制以保证安全性:
-
拥有最新的已提交的log entry的Follower才有资格成为leader。
-
Leader只能推进commit index来提交当前term的已经复制到大多数服务器上的日志,旧term日志的提交要等到提交当前term的日志来间接提交(log index 小于 commit index的日志被间接提交)。
动态成员变更篇
我认为,动态成员变更的难点在于既要让旧集群的所有节点感知新成员变更,又要让未来要加入的节点能够识别到新节点。
我的设计思路是
1 新节点A向旧集群的任一节点B发送加入集群请求。如果节点B不是leader节点,则转发至leader节点。
2 leader节点将新节点IP保存到列表中,并将列表通过RPC同步到旧集群中,这是最关键的一步,保证集群中所有的节点都能维持一个相同的集群信息副本。
3 新节点A加入集群,leader向新节点A同步日志。
节点增加
新节点发送加入集群的请求
public void add() {//把要增加的节点同步给所有的peerset
for (Peer ignore : peerSet.getPeersWithOutSelf()) {
// TODO 同步到其他节点.
Request request = Request.builder()
.cmd(Request.CHANGE_CONFIG_ADD)
.url(ignore.getAddr())
.obj(peerSet.getSelf())
.build();
Response result1 = getRpcClient().send(request);
Result result = (Result) result1.getResult();
if (result != null && result.getStatus() == Result.Status.SUCCESS.getCode()) {
log.info("增加节点" + peerSet.getSelf() + "成功");
} else {
log.info("增加节点" + peerSet.getSelf() + "失败");
}
}leader处理加入集群请求
public synchronized Result addPeer(Peer newPeer) {
//leader向新节点同步日志
System.out.println(node.status);
System.out.println(node.peerSet.getList());
System.out.println(newPeer.getAddr());
if(node.peerSet.getList().contains(newPeer)){
return new Result();
}else{
node.peerSet.getList().add(newPeer);
}
if (node.status == NodeStatus.LEADER) {
// node.peerSet.getList().add(newPeer);
node.nextIndexs.put(newPeer, 0L);
node.matchIndexs.put(newPeer, 0L);
for (long i = 0; i < node.logModule.getLastIndex(); i++) {
LogEntry entry = node.logModule.read(i);
if (entry != null) {
node.replication(newPeer, entry);
}
}
try {
Thread.sleep(1000);//给同步日志的时间
} catch (InterruptedException e) {
}
log.info("从leader节点向新节点"+newPeer+"同步日志完成");
//从leader节点把最完整的peerSet同步到其他节点(包括新节点)
for (Peer ignore : node.peerSet.getPeersWithOutSelf()) {
// TODO 同步到其他节点.
Request request = Request.builder()
.cmd(Request.CHANGE_PEERSET_ADD)
.url(ignore.getAddr())
.obj(node.peerSet)
.build();
Response result1 = rpcClient.send(request);
Result result = (Result) result1.getResult();
if (result != null && result.getStatus() == Result.Status.SUCCESS.getCode()) {
log.info("从leader节点向"+ignore+"同步peerSet成功");
} else {
log.info("从leader节点向"+ignore+"同步peerSet失败");
}
}
}else{
Request request = Request.builder()
.cmd(Request.CHANGE_CONFIG_ADD)
.url(node.getPeerSet().getLeader().getAddr())
.obj(newPeer)
.build();
rpcClient.send(request);
}
Result result=new Result();
result.setStatus(Result.SUCCESS);
return result;
}节点下线
把节点下线放在JVM销毁前执行的一个线程里进行处理。
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
synchronized (node) {
node.notifyAll();
try {
node.destroy();
} catch (Throwable e) {
throw new RuntimeException(e);
}
}
}));public void destroy() throws Throwable {
for (Peer ignore : peerSet.getPeersWithOutSelf()) {
// TODO 同步到其他节点.
Request request = Request.builder()
.cmd(Request.CHANGE_CONFIG_REMOVE)
.url(ignore.getAddr())
.obj(peerSet.getSelf())
.build();
Response result1 = getRpcClient().send(request);
Result result=(Result)result1.getResult();
if (result != null && result.getStatus()== Result.Status.SUCCESS.getCode()) {
log.info("成功从"+ignore+"删除节点"+peerSet.getSelf()+"成功");
} else {
log.info("成功从"+ignore+"删除节点"+peerSet.getSelf()+"失败");
}
}
rpcServer.destroy();
stateMachine.destroy();
rpcClient.destroy();
running = false;
log.info("destroy success");
}自定义RPC篇
相比前几节,这个就普通了,就是几个节点能够进行通信的桥梁,具体的可见另一个专栏。
测试方法
正常状态下
- 在 idea 中配置 5 个 application 启动项,配置 main 类为 RaftNodeBootStrap 类, 加入 -DserverPort=8775 -DserverPort=8776 -DserverPort=8777 -DserverPort=8778 -DserverPort=8779
- 依次启动 5 个 RaftNodeBootStrap 节点, 端口分别是 8775,8776, 8777, 8778, 8779.
- 使用客户端写入 kv 数据.
- 杀掉所有节点, 使用 junit test 读取每个 rocksDB 的值, 验证每个节点的数据是否一致.
非正常状态下
- 在 idea 中配置 5 个 application 启动项,配置 main 类为 RaftNodeBootStrap 类, 加入 -DserverPort=8775 -DserverPort=8776 -DserverPort=8777 -DserverPort=8778 -DserverPort=8779
- 依次启动 5 个 RaftNodeBootStrap 节点, 端口分别是 8775,8776, 8777, 8778, 8779.
- 使用客户端写入 kv 数据.
- 杀掉 leader (假设是 8775).
- 再次写入数据.
- 重启 8775.
- 关闭所有节点, 读取 RocksDB 验证数据一致性.
一些参数说明
代码很多参数表达的意思很相近,这里总结一下


matchIndex就是已知的从节点的log和leader的log一致的index位置。
这个作用nextIndex可以代替?其实不然。nextIndex的位置是初始为leader的最新logIndex+1,如果从节点没有跟上leader的log,那么这个nextIndex会回溯到从节点跟leader一致的位置。所以nextIndex无法代替matchIndex的功能。
那么知道这个matchIndex用来做啥呢?
用来计算commitIndex! leader的的commitIndex是大部分follower的matchIndex的中位数
Follower的commitIndex是min(local log index,leaderCommitIndex)。
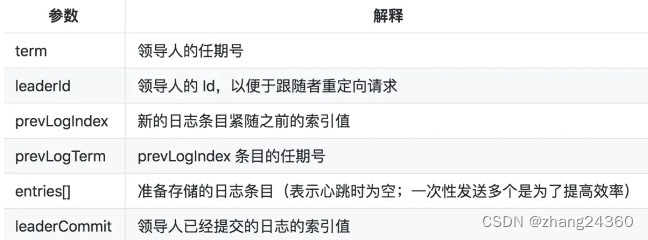
参考

















 2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









