







分类问题
例如对肿瘤的分类问题:
0:良性
1:恶性
二元分类问题(binary classification problem)只需要两个结果:0和1。有时候也用-和+表示,所以y(i) 也被称为标签。
逻辑回归
一些术语:
asymptotes 渐近线
使用sigmoid函数g(z)将线性函数h(x)的值域映射到(0, 1),
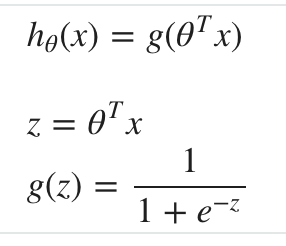
g(z)的函数图:
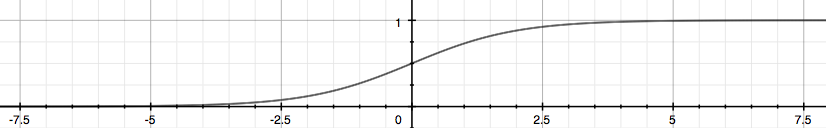
新的h(x)就表示结果为1的概率。
例如肿瘤分类的例子,假如hθ (x) = 0.7,就表示输出结果为1,即肿瘤为恶性的概率为70%。
相应的,输出结果为0,即肿瘤为良性的概率为30%:
决策边界(Decision Boundary)
使用了sigmoid函数,其实目标就转化为,找出一个线性函数hθ(x):
- 当h > 0时,判断为1
- 当h < 0时,判断为0
当只有一维特征时,可以画一条竖线;
当有两维特征时,可以画一条斜线:

或者更复杂的,画一个曲线范围:

h(x)就是决策边界。
代价函数
sigmoid函数的均方差代价函数非凸的(下面左图),所以无法保证到达全局最优。
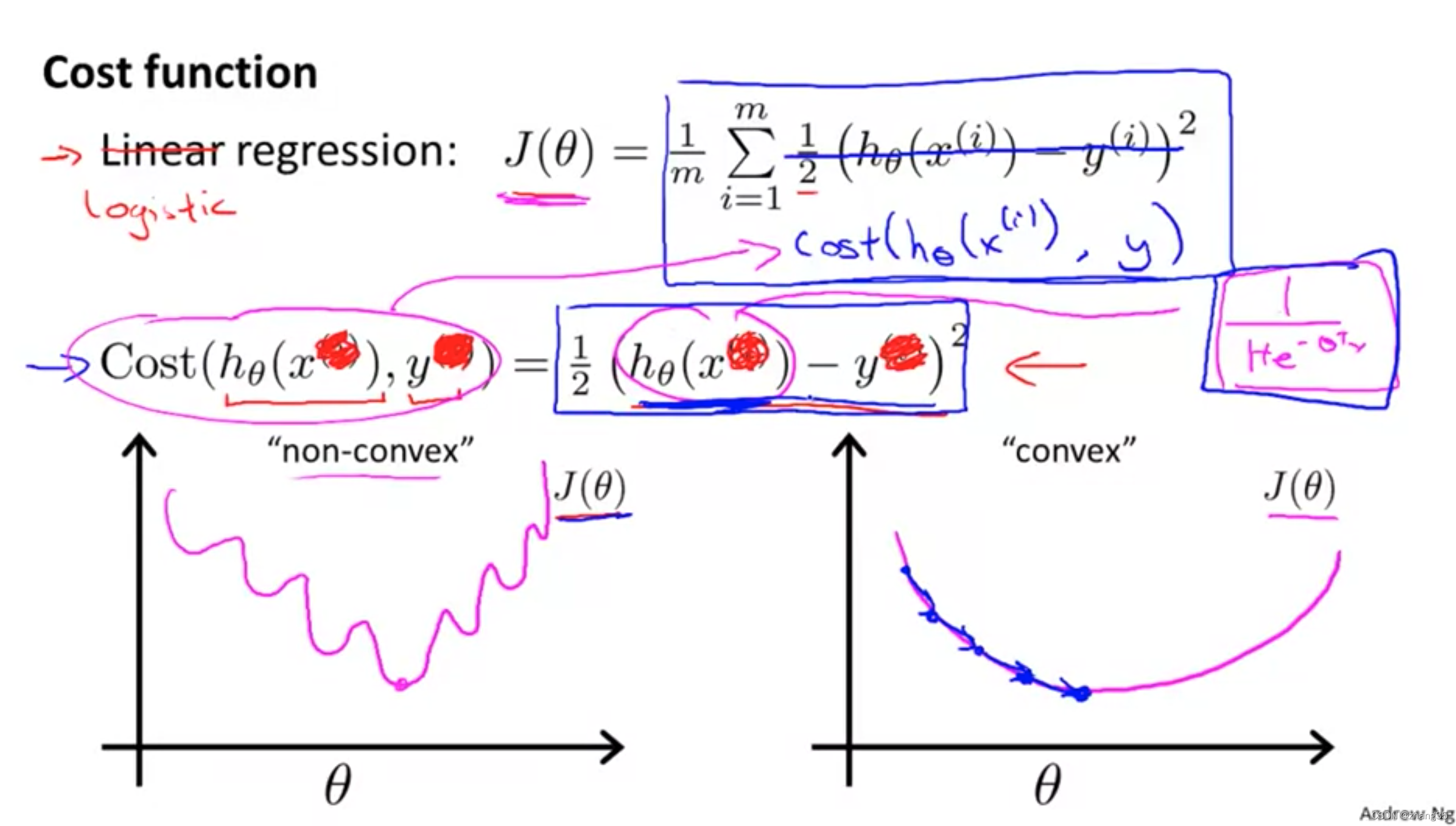
所以,应该给它专门设计一个代价函数:
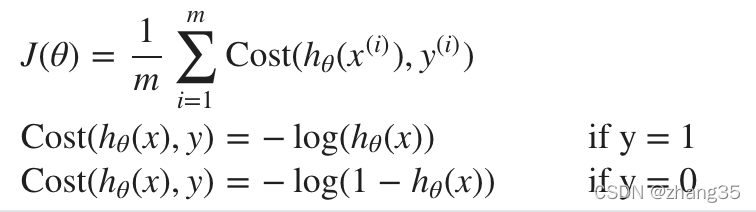
当y=1时,代价函数如下图。
h=1时,代价为0; (命中了)
h->0时,代价->∞;(错的越远,惩罚越大)
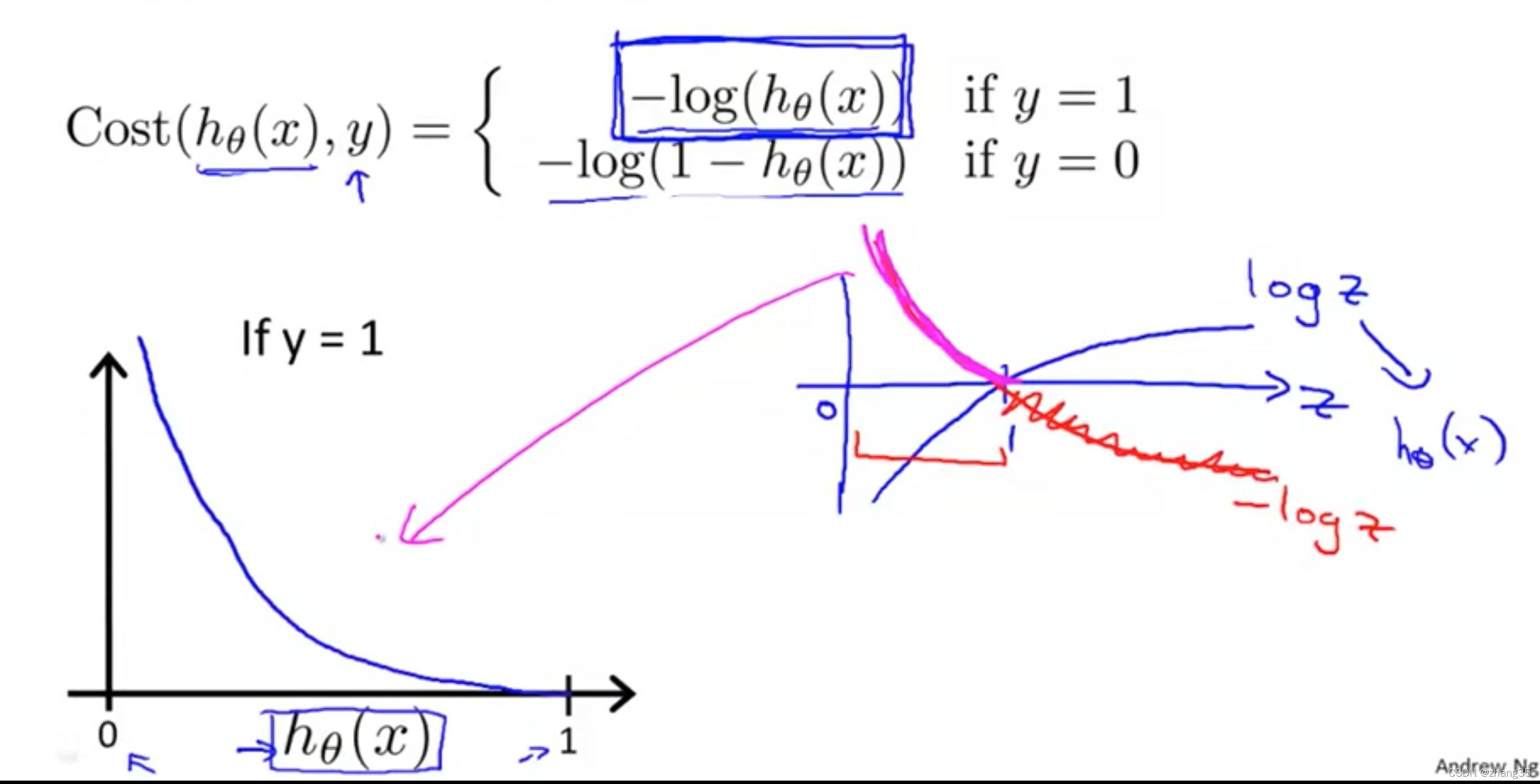
当y=0时,代价函数如下图。
h=0时,代价为0; (命中了)
h->1时,代价->∞;(错的越远,惩罚越大)
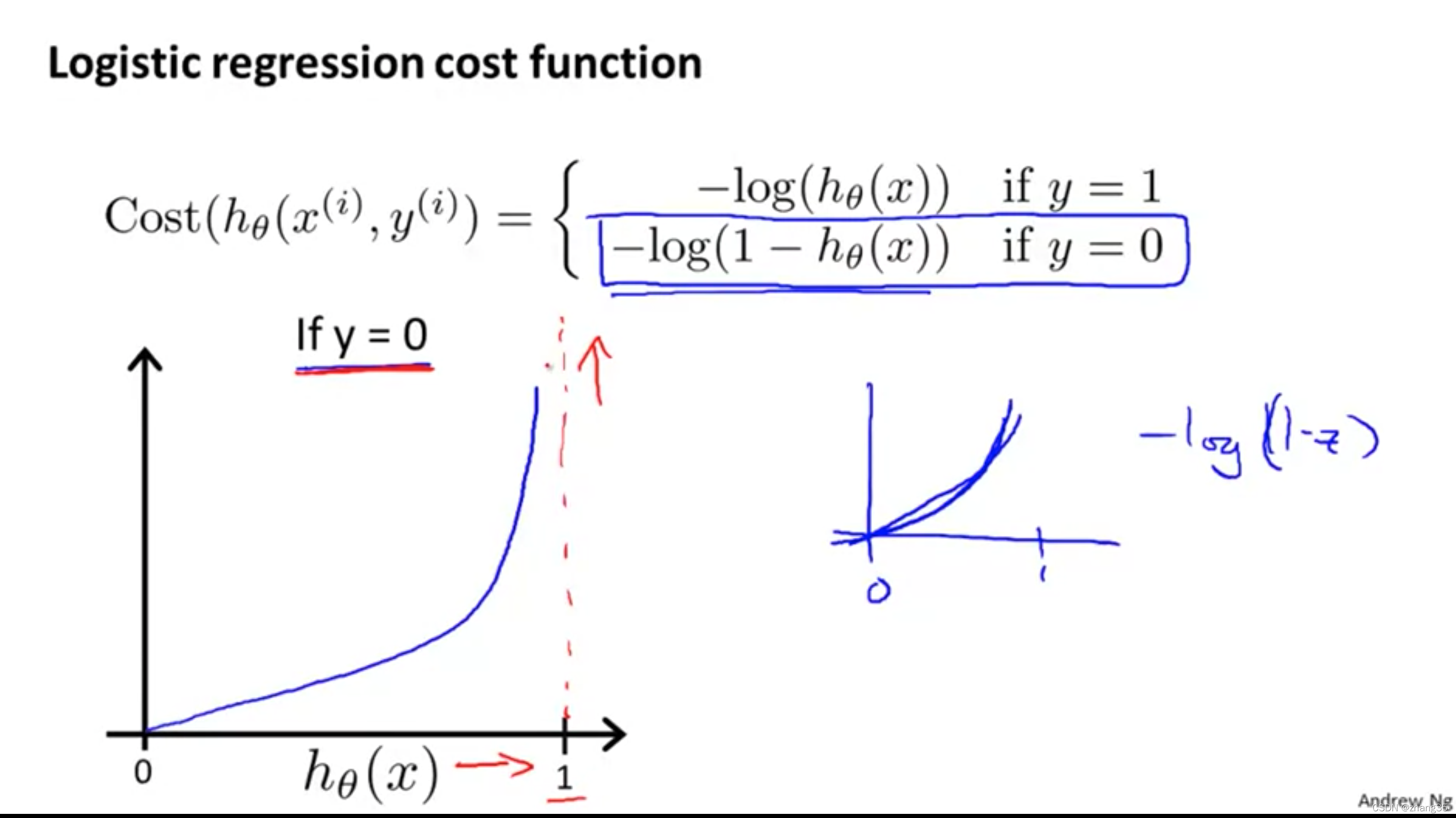
代价函数简化
上面的两个代价函数,可以合并为以下蓝色字体的函数:

此时的代价函数如下图中的J。
此时的梯度下降,根据 principal of maximum likelihood estimation: 最大似然估计定理(此处不深究),求得每次迭代过程如下。

尽管每次迭代的delta看起来和线性回归很像,但其实由于h(x)不同,它们也不相同:

向量化计算
向量化的代价函数计算:
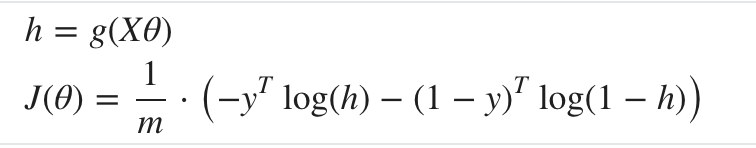
向量化的梯度下降计算方法是:
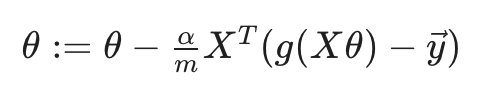
优化算法
为了找到假设函数最优的θ值,除了梯度下降,还有一些优化算法,效率更高,无需选择α,缺点就是比较复杂,比如:
- Conjugate gradient
- BFGS
- L-BFGS
和梯度下降一样,它们的输入是下面两个函数:
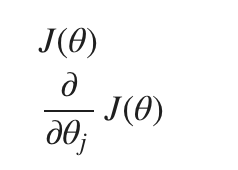
一般写个函数来返回上面两个函数:
function [jVal, gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end
然后用fminunc()方法,结合参数配置方法optimset(),就能输出最优的θ:
options = optimset('GradObj', 'on', 'MaxIter', 100);
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
吴恩达大佬说了,不用非得搞懂这些算法,会用就行。
多类别分类
one-vs-all
将n分类问题,转化为n个2分类问题,训练出n个h(x)
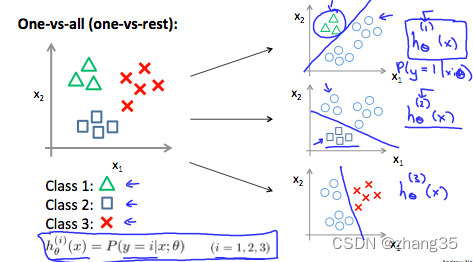
此时给定一个x,求出所有的h(x),取其中最大的作为它的分类。
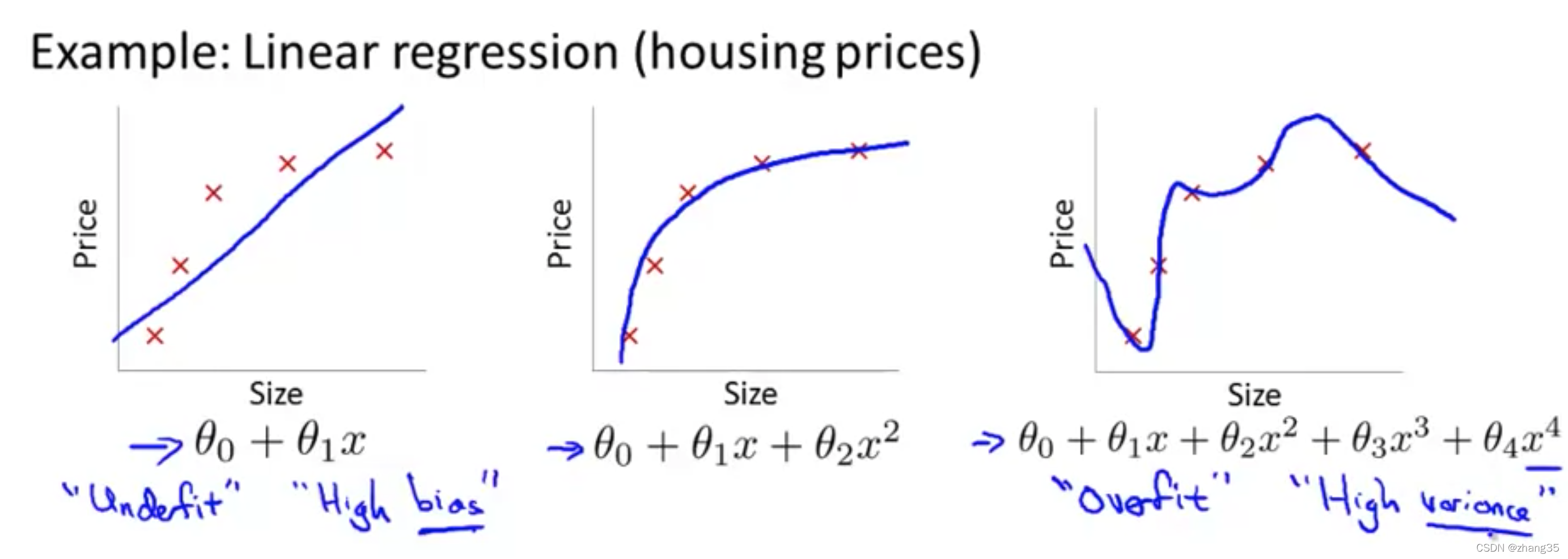
过拟合和正则化
欠拟合(图一):假设函数不够合适,结果误差较大,high bias。J比较大。
过拟合(图三):过度契合训练集,预测结果也不好,high variance。J能约等于0,但泛化能力差。
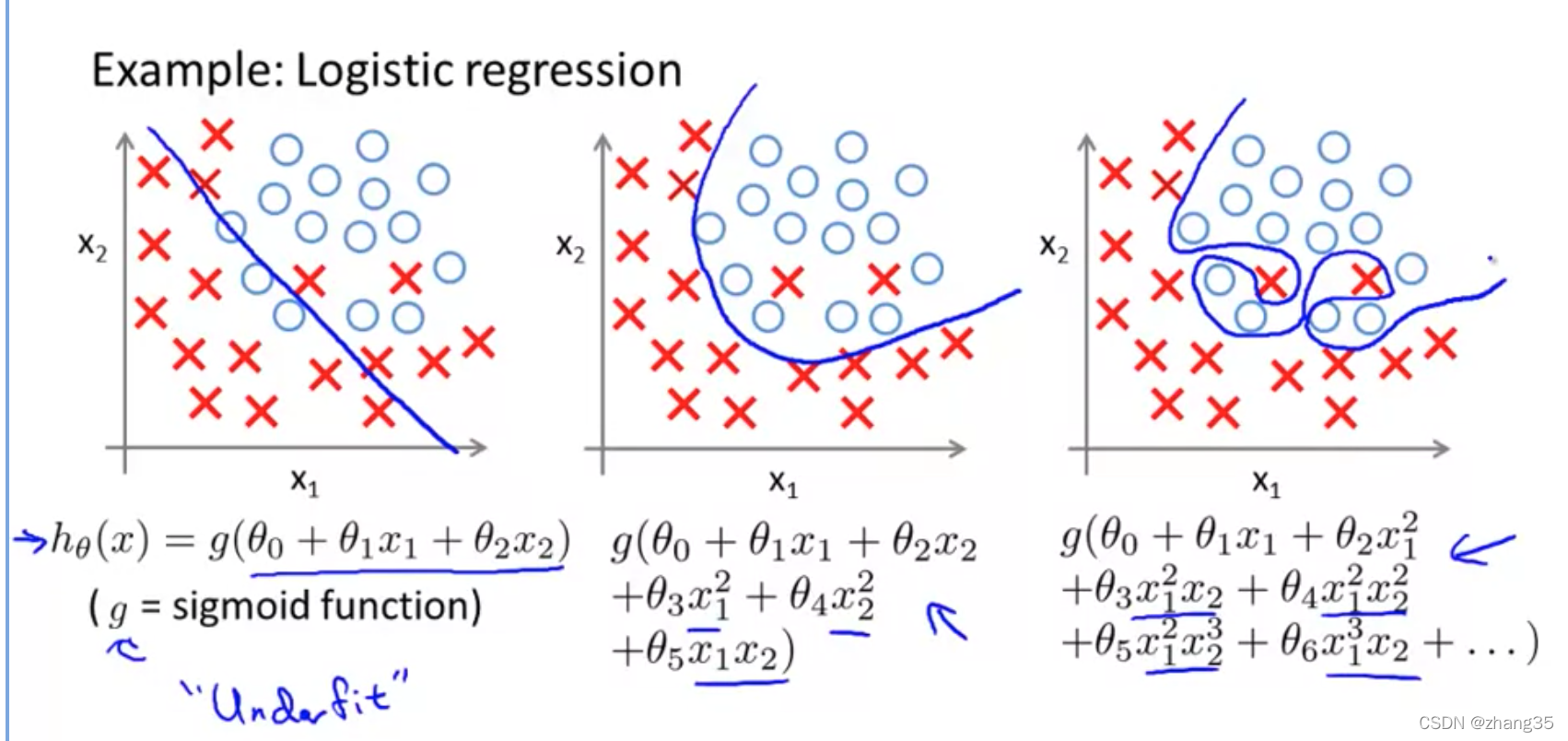
为解决过拟合,有两个选择:
- 减少特征数量:手工减少,或用模型选择算法
- 正则化(regularization):保留所有特征,但减少θ的量级,在特征数量较多时表现良好
对于相关性较小的特征,可以把它们加入代价函数,以便惩罚它们,让它们尽可能接近0:
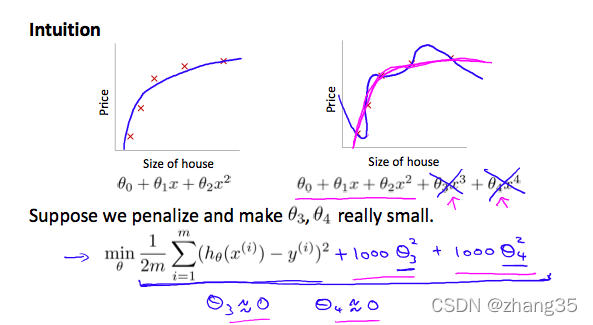
但我们怎么知道哪些特征需要惩罚呢?干脆一起加入代价函数(除了θ0):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









