







背景: 4个数据节点有数据倾斜,rebalance后依旧如此,检查分片数量和分布情况也是均衡的。最后发现相同的分片在其中一个节点存储消耗的磁盘资源比其他节点要大很多,导致了这个节点磁盘消耗较快。于是决定更换节点的磁盘
操作计划如下:
1- 将有问题的节点踢出集群 (缩容)
2- 等待数据rebalance达到数据迁移的效果
3- 更换好磁盘后,将节点重新加入到集群 (扩容)
缩容- 数据迁移
1- 设置宕机恢复时间为1分钟后,关闭 问题节点22的kudu
--follower_unavailable_considered_failed_sec :参数的意思是tserver宕机多久后,没有恢复正常,则将该tserver上的数据迁移到其他节点上。
## 范例
sudo -u kudu
kudu tserver set_flag $(hostname) follower_unavailable_considered_failed_sec 60 --force
## 例如:
sudo -u kudu
kudu tserver set_flag calculate22.xxx.xxx:7050 follower_unavailable_considered_failed_sec 60 --force2- 到kudu webUI上确认节点已经移出kudu集群。
CDH, Ambari安装的话可以直接在 CDH和Ambari的kudu实例列表上确认。
也可以使用kudu的webUID查看kudu的集群情况 (master节点,默认port是8051)
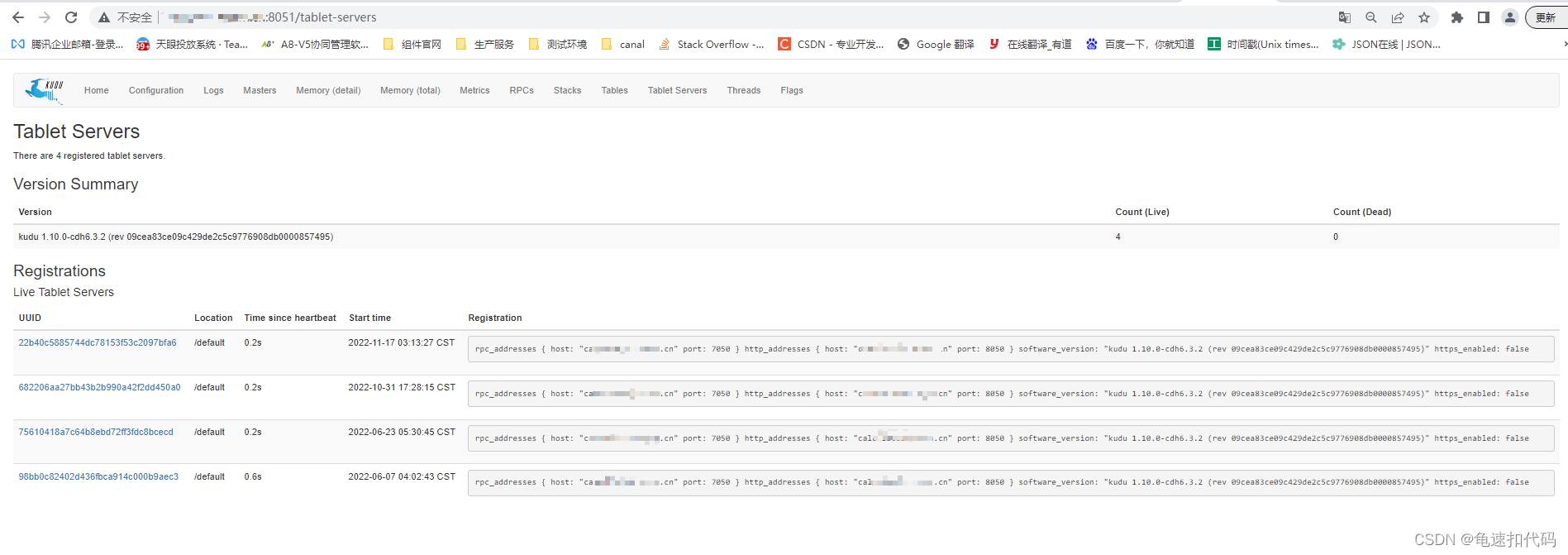
3- 等待数据迁移
数据迁移有两种方法,一种是手动迁移,一种是自动迁移。由于是线上升级,且是凌晨升级,时间充裕,为了保险,采用自动迁移。不需要操作!!!!
2.4T的数据,自动迁移花了2个多小时,将近3小时。
4- 更换磁盘后,重新加入到集群(扩容)
因为集群配置文件并没有更改,所以直接启动kudu,观察节点22的数据是否会。
sudo systemctl start kudu-tserver5- 检查kudu集群,查看是否加入成功。
同步骤2
6- 检查kudu集群的健康情况,也是要等待3小时左右,全部的表才恢复正常。
sudo -u kudu kudu cluster ksck <master地址>
# 例如
sudo -u kudu kudu cluster ksck master_node1:7051,master_node2:7051,master_node3:7051参考文档:
4. Kudu Administration - 数据节点Started with Kudu [Book] 搜索Adding and Removing Tablet Servers
Apache Kudu - Apache Kudu Administration
kudu集群:kudu_master、kudu_tserver服务及数据的迁移(根据官网总结) - 天下熙攘皆为利往 - 博客园















 1379
1379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









