







python中有多种数据结构,数据结构之间也可以相互转化,概念一多就容易使人混淆,对于初学者来说本来很容的概念,最终却变成了噩梦,很难区分不同数据结构之间的用法,这样就会造成乱用数据结构,致使运行效率低下。对于较简单的程序来说乱用数据结构不会有太大的问题,但涉及到大数据运算,可能一个数据类型就会导致内存吃满,这时善用数据结构就会变的尤为重要。
标准的python库中一般使用list来保存一组数值,并且可以使用自带的各种函数对数值进行各种运算。由于list中的元素可以是各种对象,list中保存的是对象的指针,这样为了保存['q','w','r'],需要生成3个指针和三个字符串对象,对于大数据量的运算来说这种显然很耗费内存和cpu。
此外python还提供了array模块,array对象和list不同,它直接保存数值,但是由于不支持多维数组,也没有各种运算函数,因此不适合做数值运算。
numpy弥补了上面的不足,提供了两种基本的对象,ndarray(N-dimensional array object)和ufunc(universal function object)。ndarray用来存储单一数据类型的多为数组,ufunc则提供能够对数组进行处理的函数。
可以使用array的shape属性来获取维度信息
note:从(4,3)转换为(3,4)并不是转置,只是改变了每个轴的大小,数组的元素在内存中的位置并没有改变。
当某个轴的元素为-1时,将根据元素的个数自己推算此轴的长度,如下面的c.shape=2,-1将元素转换为(2,6):
使用数组的reshape方法可以创建一个改变了尺寸的新数组,原数组的shape保持不变。这种方法创建的新数组和原数组其实是共享数据存储内存区域,因此修改其中任意一个数组的元素都会修改另一个数组的内容。
上面的方法都是先创建一个python序列,然后通过array函数将其转换为数组,这样做效率并不高。numpy还提供了很多专门用来创建数组的函数。
arange函数,类似于python中的range函数,通过给定开始值,结束值和步长来创建一维数组,数组中的值不包括终值:
另外可以使用frombuffer,fromstring,fromfile等函数从字节序列创建数组。如下面以fromstring为例:
下面创建了一个九九乘法表,输出的数组a中的每个元素a[i,j]都等于func1(i,j):
S32 : 32个字节的字符串类型,由于结构中的每个元素的大小必须固定,因此需要指定字符串的长度
i : 32bit的整数类型,相当于int32
f : 32bit的单精度浮点数类型,相当于float32
然后我们调用array函数创建数组,通过关键字参数 dtype=persontype, 指定所创建的数组的元素类型为结构persontype。运行上面程序之后,我们可以在IPython中执行如下的语句查看数组a的元素类型:
| : 忽视字节顺序
< : 低位字节在前
> : 高位字节在前
结构数组的存取方法和一般数组相同,通过下标能够取得其中的元素,注意元素的值看上去像是组元,实际上它是一个结构:
因为a是一个结构数组,所以a[0]是和a共享内存数据的,因此可以通过修改a[0]来修改他的字段,改变元素数组中的对应字段:
先用linspace产生一个从0到2*pi的等距离的10个函数,然后使用numpy的sin函数计算数组x中每个元素的正弦值,然后将结果返回给y。计算之后x的值并没有改变,而是新创建了一个数组保存结果。如果我们希望将sin函数计算的结果直接覆盖到数组x中的话,可以将被覆盖的数组作为第二个参数传递给sin, 如:
sin的第二个参数也是x,那么它做的事情是对x中的每个值求正弦值,并把结果放到x中对应的位置中。此时函数的返回值仍然是整个计算的结果,只不过它就是x,因此两个变量的id是相同的(t和x指向同一块内存区域)。
我们使用下面一个小程序,比较下numpy.math和python标准库的math.sin的计算速度:
同样计算100万次np.sin要比math.sin快10倍多,这主要是np.sin在c语言级别的循环计算。np.sin同样也支持单个数值运算,但是在执行单词求正弦运算时它的效率就比math.sin低很多,如下:
请注意在计算单个值的时候math.sin效率要比np.sin高差不多10倍,这主要是由于np.sin同时支持数组和单个值的计算,c语言内部的实现要比math.sin复杂的多,所以在使用的时候如果是单个数值尽量使用math.sin,大量的数组或矩阵使用np.sin。另外np.sin返回的数据类型是float64,而math.sin返回的是floatl类型:
通过上面的例子我们了解了如何最有效率地使用math库和numpy库中的数学函数。因为它们各有长短,因此在导入时不建议使用*号全部载入,而是应该使用import numpy as np的方式载入,这样我们可以根据需要选择合适的函数调用。
(1)让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐
(2)输出数组的shape是输入数组shape的各个轴上的最大值
(3)如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则出错
(4)当输入数组的某个轴的长度为1时,沿着此轴运算时都用此轴上的第一组值
由于这种广播计算很常用,因此numpy提供了一个快速产生如上面a,b数组的方法: ogrid对象
ogrid是一个很有趣的对象,它像一个多维数组一样,用切片组元作为下标进行存取,返回的是一组可以用来广播计算的数组。其切片下标有两种形式:
开始值:结束值:步长,和np.arange(开始值, 结束值, 步长)类似
开始值:结束值:长度j,当第三个参数为虚数时,它表示返回的数组的长度,和np.linspace(开始值, 结束值, 长度)类似:
有关numpy中的数学运算的内容将会在下篇文章中详细介绍!
一、list列表类型
list类型是Python中内置的, list中包含的数据之间的类型可以不相同,并且list中数据保存的是数据的指针,因为数据类型不同所以不能一起存放到一个内存空间,致使list中的每个数据都会开辟一个内存空间,所以list类型的数据是很耗费内存的,list中的数据的索引从0开始。
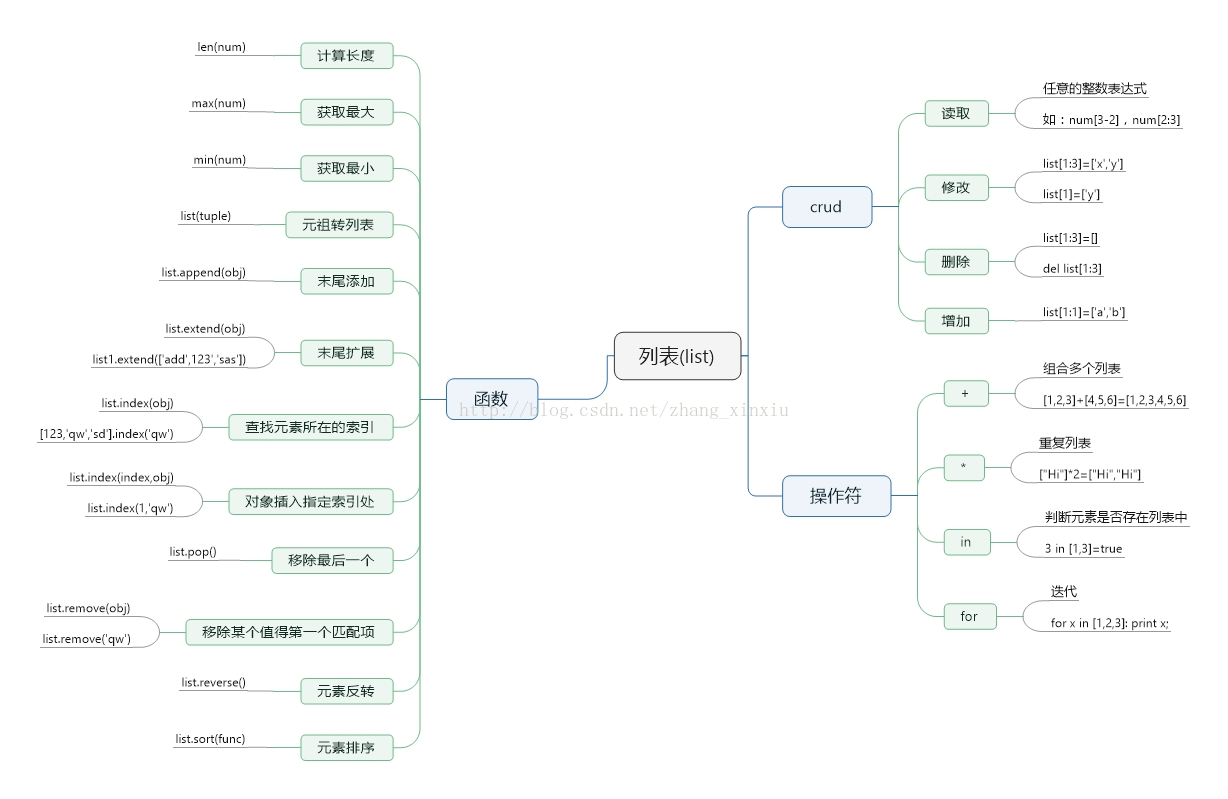
上图是list类型基本内容,其中的函数部分所有的操作跟其它语言中的list类型是相同的,这里面的数据每次写入和读取都会进行装箱和拆箱操作,装箱和拆箱操作既占用内存又耗时,所以在大数据处理的时候慎用list类型的数据。
#定义一个list
>>> l=[1,2,3,4]
#查看l
>>> l
[1, 2, 3, 4]
#获取l中的第二个到第三个(list的索引是从0开始)
>>> l[1:3]
[2, 3]
#在l中增加元素
>>> l[1:3]=['a','b']
>>> l
[1, 'a', 'b', 4]
#在l中删除元素
>>> l[1:3]=[]
>>> l
[1, 4]
>>> del l[1]
>>> l
[1]
#使用numpy中的tile函数将l转化为2维list(tile函数会复制l中的元素,tile的第一个参数代表生成后的维度,第二个参数代表最终行数据的个数)
>>> l=[1,2,3,'a','b','v']
>>> e=tile(l,(2,3))
>>> e
array([['1', '2', '3', 'a', 'b', 'v', '1', '2', '3', 'a', 'b', 'v', '1',
'2', '3', 'a', 'b', 'v'],
['1', '2', '3', 'a', 'b', 'v', '1', '2', '3', 'a', 'b', 'v', '1',
'2', '3', 'a', 'b', 'v']],
dtype='|S1')
>>> print e
[['1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v']
['1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v']]
二、tuple元组类型
元组与list列表类似,也是保存的数据的指针,不同的是元组在内存中申请的是固定地址,不可变更,不能修改和删除元组中的某个元组,只能创建和删除整个元组。为了修改元组的内容,只能再生成一个新的元组,把修改好的内容放到新的元组中,可以使用加号将多个元组合并为一个。无符号的对象,以对象隔开,默认为元组。
上图为元组的基本操作,元组和列表很相似,很多用法也相同,在使用的使用如果元组能够满足需求的话可以考虑使用元组,因为相较列表元组的对内存的需求更低。
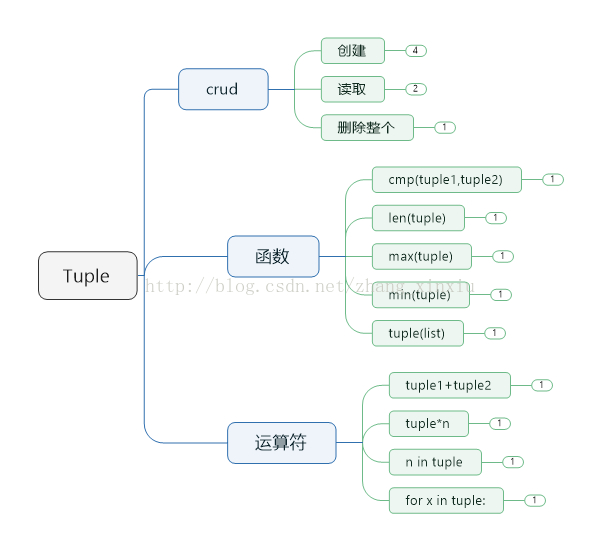
#创建元组
>>> t1=(1,2,3,'a','c')
>>> t1
(1, 2, 3, 'a', 'c')
>>> t2=1,2,3,'c','d'
>>> t2
(1, 2, 3, 'c', 'd')
>>> x,y=1,'q'
>>> x,y
(1, 'q')
#读取元组中的元素
>>> t1[1:3]
(2, 3)
>>> t1[1-3]
'a'
>>> t1
(1, 2, 3, 'a', 'c')
>>> t1[3]
'a'
>>> t1[2-3]
'c'
>>> t1[-1]
'c'
#删除整个元组
>>> del t1
>>> t1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 't1' is not defined
#合并两个元组
>>> t2=1,2,3,'c','d'
>>> t1=(1,2,3,'a','c')
>>> t1+t2
(1, 2, 3, 'a', 'c', 1, 2, 3, 'c', 'd')
#元组复制
>>> t1*2
(1, 2, 3, 'a', 'c', 1, 2, 3, 'a', 'c')
#取元组最大值和最小值
>>> max(t1)
'c'
>>> min(t1)
1
#列表转元组
>>> l=[1,2,3,'a','b']
>>> tuple(l)
(1, 2, 3, 'a', 'b')
三、字典
字典是另一种可变容器的模型,可存储任意类型的对象,但键必须是不可变的,键可以是字符串,数组或元组。

#创建字典
>>> dict={}
>>> dict['q']=1
>>> dict1={'q':1,'w':2}
#修改字典内容
>>> dict1
{'q': 1, 'w': 2}
>>> dict1['q']=2
>>> dict1.update({'w':3})
>>> dict1
{'q': 2, 'w': 3}
#删除字典内容
>>> del dict1['q']
>>> dict1
{'w': 3}
>>> dict1.clear()
>>> dict1
{}
#返回字典的字符串
>>> str(dict2)
'{12: 12}'
#创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值
>>> dict1.fromkeys((1,2,3),3)
{1: 3, 2: 3, 3: 3}
#获取字典中指定的值
>>> dict1
{'q': 1, 'w': 2}
>>> dict1['q']
1
#读取字典中的值,如果不存在返回默认值
>>> dict1.get('q',0)
1
>>> dict1
{'q': 1, 'w': 2}
>>> dict1.get('a',4)
4
>>> dict1
{'q': 1, 'w': 2}
#读取字典中的值,如果不存在返回默认值,并将值写入字典中
>>> dict1
{'q': 1, 'e': 4, 'w': 2}
>>> dict1.setdefault('r',5)
5
>>> dict1
{'q': 1, 'r': 5, 'e': 4, 'w': 2}
#浅拷贝
>>> dict4=dict1.copy()
>>> dict4
{'q': 1, 'r': 5, 'e': 4, 'w': 2}
四、numpy中的array
标准的python库中一般使用list来保存一组数值,并且可以使用自带的各种函数对数值进行各种运算。由于list中的元素可以是各种对象,list中保存的是对象的指针,这样为了保存['q','w','r'],需要生成3个指针和三个字符串对象,对于大数据量的运算来说这种显然很耗费内存和cpu。
此外python还提供了array模块,array对象和list不同,它直接保存数值,但是由于不支持多维数组,也没有各种运算函数,因此不适合做数值运算。
numpy弥补了上面的不足,提供了两种基本的对象,ndarray(N-dimensional array object)和ufunc(universal function object)。ndarray用来存储单一数据类型的多为数组,ufunc则提供能够对数组进行处理的函数。

4.1 ndarray
4.1.1 创建
可以使用给array对象传递python的序列对象来创建数组,如果传递的是多层嵌套的序列,将会创建多维的数组。>>> a=array([1,2,3,4])
>>> a
array([1, 2, 3, 4])
>>> b=array((4,5,6,7))
>>> b
array([4, 5, 6, 7])
>>> c=array([[1,2,3],[4,5,6],[7,8,9]])
>>> c
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> c.dtype
dtype('int32')
可以使用array的shape属性来获取维度信息
>>> c.shape
(3, 3)
还可以通过改变shape属性的,在保持数组元素的个数不变的情况下,改变数组的每个轴的长度。下面将(4,3)的c数组,转换为(3,4)。
>>> c
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
>>> c.shape
(4, 3)
>>> c.shape=3,4
>>> c
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
note:从(4,3)转换为(3,4)并不是转置,只是改变了每个轴的大小,数组的元素在内存中的位置并没有改变。
当某个轴的元素为-1时,将根据元素的个数自己推算此轴的长度,如下面的c.shape=2,-1将元素转换为(2,6):
>>> c.shape=2,-1
>>> c
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12]])
使用数组的reshape方法可以创建一个改变了尺寸的新数组,原数组的shape保持不变。这种方法创建的新数组和原数组其实是共享数据存储内存区域,因此修改其中任意一个数组的元素都会修改另一个数组的内容。
>>> d=b.reshape((2,2))
>>> d
array([[ 7, 8],
[ 9, 10]])
>>> b[1]=1
>>> b
array([ 7, 1, 9, 10])
>>> d
array([[ 7, 1],
[ 9, 10]])
>>> array([[1,2,3,4],[5,6,7,8],[1,3,5,6]],dtype=float)
array([[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 1., 3., 5., 6.]])
>>> array([[1,2,3,4],[5,6,7,8],[1,3,5,6]],dtype=complex)
array([[ 1.+0.j, 2.+0.j, 3.+0.j, 4.+0.j],
[ 5.+0.j, 6.+0.j, 7.+0.j, 8.+0.j],
[ 1.+0.j, 3.+0.j, 5.+0.j, 6.+0.j]])
上面的方法都是先创建一个python序列,然后通过array函数将其转换为数组,这样做效率并不高。numpy还提供了很多专门用来创建数组的函数。
arange函数,类似于python中的range函数,通过给定开始值,结束值和步长来创建一维数组,数组中的值不包括终值:
>>> arange(0,1,0.1)
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
>>> linspace(0,1,12)
array([ 0. , 0.09090909, 0.18181818, 0.27272727, 0.36363636,
0.45454545, 0.54545455, 0.63636364, 0.72727273, 0.81818182,
0.90909091, 1. ])
>>> linspace(0,1,12,endpoint=False)
array([ 0. , 0.08333333, 0.16666667, 0.25 , 0.33333333,
0.41666667, 0.5 , 0.58333333, 0.66666667, 0.75 ,
0.83333333, 0.91666667])
>>> logspace(0, 2, 20)
array([ 1. , 1.27427499, 1.62377674, 2.06913808,
2.6366509 , 3.35981829, 4.2813324 , 5.45559478,
6.95192796, 8.8586679 , 11.28837892, 14.38449888,
18.32980711, 23.35721469, 29.76351442, 37.92690191,
48.32930239, 61.58482111, 78.47599704, 100. ])
另外可以使用frombuffer,fromstring,fromfile等函数从字节序列创建数组。如下面以fromstring为例:
>>> t='abcdef'
>>> fromstring(t,dtype=int8)
array([ 97, 98, 99, 100, 101, 102], dtype=int8)
>>> fromstring(t,dtype=int16)
array([25185, 25699, 26213], dtype=int16)
>>> def func(i):
... return i%2+1
...
>>> fromfunction(func,(10,))
array([ 1., 2., 1., 2., 1., 2., 1., 2., 1., 2.])
下面创建了一个九九乘法表,输出的数组a中的每个元素a[i,j]都等于func1(i,j):
>>> def func1(i,j):
... return (i+1)*(j+1)
...
>>> fromfunction(func1,(9,9))
array([[ 1., 2., 3., 4., 5., 6., 7., 8., 9.],
[ 2., 4., 6., 8., 10., 12., 14., 16., 18.],
[ 3., 6., 9., 12., 15., 18., 21., 24., 27.],
[ 4., 8., 12., 16., 20., 24., 28., 32., 36.],
[ 5., 10., 15., 20., 25., 30., 35., 40., 45.],
[ 6., 12., 18., 24., 30., 36., 42., 48., 54.],
[ 7., 14., 21., 28., 35., 42., 49., 56., 63.],
[ 8., 16., 24., 32., 40., 48., 56., 64., 72.],
[ 9., 18., 27., 36., 45., 54., 63., 72., 81.]])
>>> arange(0, 60, 10).reshape(-1, 1) + arange(0, 6)
array([[ 0, 1, 2, 3, 4, 5],
[10, 11, 12, 13, 14, 15],
[20, 21, 22, 23, 24, 25],
[30, 31, 32, 33, 34, 35],
[40, 41, 42, 43, 44, 45],
[50, 51, 52, 53, 54, 55]])
4.1.2 结构数组
下面定义了一个结构数组,它的每个元素都有name,age和weight字段:>>> from numpy import *
>>> persontype=dtype({'names':['name','age','weight'],'formats':['S32','i','f']})
>>> persontype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
>>> a=array([("Zhang",32,75.5),("Wang",24,65.2)],dtype=persontype)
>>> a
array([('Zhang', 32, 75.5), ('Wang', 24, 65.19999694824219)],
dtype=[('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
>>> a.dtype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
S32 : 32个字节的字符串类型,由于结构中的每个元素的大小必须固定,因此需要指定字符串的长度
i : 32bit的整数类型,相当于int32
f : 32bit的单精度浮点数类型,相当于float32
然后我们调用array函数创建数组,通过关键字参数 dtype=persontype, 指定所创建的数组的元素类型为结构persontype。运行上面程序之后,我们可以在IPython中执行如下的语句查看数组a的元素类型:
>>> a.dtype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
| : 忽视字节顺序
< : 低位字节在前
> : 高位字节在前
结构数组的存取方法和一般数组相同,通过下标能够取得其中的元素,注意元素的值看上去像是组元,实际上它是一个结构:
>>> a[0]
('Zhang', 32, 75.5)
>>> a[0].dtype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
因为a是一个结构数组,所以a[0]是和a共享内存数据的,因此可以通过修改a[0]来修改他的字段,改变元素数组中的对应字段:
>>> c=a[1]
>>> c
('Wang', 24, 65.19999694824219)
>>> c["name"]="Li"
>>> c
('Li', 24, 65.19999694824219)
>>> a
array([('Zhang', 32, 75.5), ('Li', 24, 65.19999694824219)],
dtype=[('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
>>> a[1]
('Li', 24, 65.19999694824219)
4.1.3ufunc运算
ufunc是universal function的缩写,它是一种能对数组的每个元素进行操作的函数。Numpy内置的许多ufunc都是c语言级别实现的,因此它的运行速度非常快。让我们来看个例子:>>> import numpy as np
>>> x=np.linspace(0,2*np.pi,10)
>>> y=np.sin(x)
>>> y
array([ 0.00000000e+00, 6.42787610e-01, 9.84807753e-01,
8.66025404e-01, 3.42020143e-01, -3.42020143e-01,
-8.66025404e-01, -9.84807753e-01, -6.42787610e-01,
-2.44929360e-16])先用linspace产生一个从0到2*pi的等距离的10个函数,然后使用numpy的sin函数计算数组x中每个元素的正弦值,然后将结果返回给y。计算之后x的值并没有改变,而是新创建了一个数组保存结果。如果我们希望将sin函数计算的结果直接覆盖到数组x中的话,可以将被覆盖的数组作为第二个参数传递给sin, 如:
>>> t=np.sin(x,x)
>>> x
array([ 0.00000000e+00, 6.42787610e-01, 9.84807753e-01,
8.66025404e-01, 3.42020143e-01, -3.42020143e-01,
-8.66025404e-01, -9.84807753e-01, -6.42787610e-01,
-2.44929360e-16])sin的第二个参数也是x,那么它做的事情是对x中的每个值求正弦值,并把结果放到x中对应的位置中。此时函数的返回值仍然是整个计算的结果,只不过它就是x,因此两个变量的id是相同的(t和x指向同一块内存区域)。
我们使用下面一个小程序,比较下numpy.math和python标准库的math.sin的计算速度:
import time
import math
import numpy as np
x=[i*0.001 for i in xrange(1000000)]
start=time.clock()
for i,t in enumerate(x):
x[i]=math.sin(t)
print "math.sin:",time.clock()-start
x=[i*0.001 for i in xrange(1000000)]
x=np.array(x)
start=time.clock()
np.sin(x,x)
print "np.math sin:",time.clock()-start
#输出
#math.sin: 0.360840664005
#np.math sin: 0.0248599687013同样计算100万次np.sin要比math.sin快10倍多,这主要是np.sin在c语言级别的循环计算。np.sin同样也支持单个数值运算,但是在执行单词求正弦运算时它的效率就比math.sin低很多,如下:
x=[i*0.001 for i in xrange(1000000)]
start=time.clock()
for i,t in enumerate(x):
x[i]=np.sin(t)
print "np.sin:",time.clock()-start
#np.sin: 2.09553287431请注意在计算单个值的时候math.sin效率要比np.sin高差不多10倍,这主要是由于np.sin同时支持数组和单个值的计算,c语言内部的实现要比math.sin复杂的多,所以在使用的时候如果是单个数值尽量使用math.sin,大量的数组或矩阵使用np.sin。另外np.sin返回的数据类型是float64,而math.sin返回的是floatl类型:
>>> import numpy as np
>>> type(np.sin(0.5))
<type 'numpy.float64'>
>>> import math
>>> type(math.sin(0.5))
<type 'float'>通过上面的例子我们了解了如何最有效率地使用math库和numpy库中的数学函数。因为它们各有长短,因此在导入时不建议使用*号全部载入,而是应该使用import numpy as np的方式载入,这样我们可以根据需要选择合适的函数调用。
4.2广播
当我们使用ufunc函数对两个数组进行计算时,ufunc函数会对两个数组的对应元素进行计算,因此它要求这两个数组有相同的大小(shape大小相同)。如果两个shape不同,则会进行如下的广播处理:(1)让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐
(2)输出数组的shape是输入数组shape的各个轴上的最大值
(3)如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则出错
(4)当输入数组的某个轴的长度为1时,沿着此轴运算时都用此轴上的第一组值
>>> a=np.arange(0,60,10).reshape(-1,1)
>>> a
array([[ 0],
[10],
[20],
[30],
[40],
[50]])
>>> a.shape
(6, 1)
>>> b=np.arange(0,5)
>>> b
array([0, 1, 2, 3, 4])
>>> c=a+b
>>> c
array([[ 0, 1, 2, 3, 4],
[10, 11, 12, 13, 14],
[20, 21, 22, 23, 24],
[30, 31, 32, 33, 34],
[40, 41, 42, 43, 44],
[50, 51, 52, 53, 54]])由于这种广播计算很常用,因此numpy提供了一个快速产生如上面a,b数组的方法: ogrid对象
>>> x,y = np.ogrid[0:5,0:5]
>>> x
array([[0],
[1],
[2],
[3],
[4]])
>>> y
array([[0, 1, 2, 3, 4]])ogrid是一个很有趣的对象,它像一个多维数组一样,用切片组元作为下标进行存取,返回的是一组可以用来广播计算的数组。其切片下标有两种形式:
开始值:结束值:步长,和np.arange(开始值, 结束值, 步长)类似
开始值:结束值:长度j,当第三个参数为虚数时,它表示返回的数组的长度,和np.linspace(开始值, 结束值, 长度)类似:
>>> x, y = np.ogrid[0:1:4j, 0:1:3j]
>>> x
array([[ 0. ],
[ 0.33333333],
[ 0.66666667],
[ 1. ]])
>>> y
array([[ 0. , 0.5, 1. ]])有关numpy中的数学运算的内容将会在下篇文章中详细介绍!















 2249
2249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









