







昨天nagios报警warning,没来得及留下报警截图,nagios值设定的值是

当1分钟多于15个进程等待,5分钟多于10个,15分钟多于5个则为warning状态
当1分钟多于30个进程等待,5分钟多于25个,15分钟多于20个则为critical状态
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
MySQL主服务器load average 骤增

虽然没来得及排查出来最后又下去了,但是在增长的时候没有最后落实这个错误,着实很难过,在网上看许多资料,大部分都是一样的解释,转载的,抄袭的,心中也是错乱,最终就是一个问题在困扰,这三个数值,是本身内核计算完CPU单核的值,还是未除以CPU核数之前的值,这个问题在许多论坛和博文里,有不同的说法,但是大部分还是倾向于是除完的,实在无解,半夜求解同学胖伟,骚伟已翻墙,跑到国外技术网站,给了我这么一段话。

我蹩脚的翻译过来(不对的地方请多指正)
在多处理器系统上
负载相对于可用的处理器内核的数量是相对的
“100%利用”标志负载为1,只是标志在一个单一的核心系统
2标志是在双核,4是标志在四核等
因此,有一个 14 load average值和 24个 内核的负载平均,你的服务器是远离超载的
(一天的心结·······释然)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
以下是从不同地方摄取精华并重新整理已方便自己以后查阅
load average
以下命令均可获取load average系统平均负载
]# top
]# uptime
]# w
]# cat /proc/loadavg
/proc文件系统是一个虚拟的文件系统,不占用磁盘空间,它反映了当前操作系统在内存中的运行情况,查看/proc下的文件可以了解到系统的运行状态。查看系统平均负载使用“cat /proc/loadavg”命令,输出结果如下

前三个数字是1、5、15分钟内的平均进程数。后面的 1/331 一个的分子是正在运行的进程数,分母是进程总数;另一个是最近运行的进程ID号。
top获取:

系统平均负载被定义为:在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进
程数。
如果一个进程满足以下条件则其就会位于运行队列中:
上图椭圆部分3个数值分别表示系统在过去1分钟、5分钟、15分钟内运行进程队列中的平均进程数量。
运行队列嘛,没有等待IO,没有WAIT,没有KILL的进程通通都进这个队列。
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
我们可以这样认为,就是 正在运行的进程 + 准备好等待运行的进程 在特定时间内(1分钟,5分钟,10分钟)的平均进程数
但是具体平均时候分母的值是按秒还是什么单位运算的?我也搞不清楚,大概就是这样算出来的值,不影响对系统初步性能瓶颈判断,此处先略过
在Linux中,进程分为三种状态, 一种是阻塞的进程blocked process,
一种是可运行的进程runnable process,
另外就是正在运行的进程running process。当进程阻塞时,进程会等待I/O设备的数据或者系统调用。
进程可运行状态时,它处在一个运行队列run queue中,与其他可运行进程争夺CPU时间。 系统的load是指正在运行running one和准备好运行runnable one的进程的总数。比如现在系统有2个正在运行的进程,3个可运行进程,那么系统的load就是5,load average就是一定时间内的load数量均值
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
看到一篇文章小汽车的举例说的很不错,但是更深层次的我觉得有个打电话的写的更加详细,现以小汽车举例
为了更好地理解系统负载,我们用交通流量来做类比。
单核CPU可以想象成单车道

比如每个圆圈都是小汽车,第一种是满负荷但CPU时间片不用排队等待正好够用,第二种是%50空闲,第三个是超负荷50%,后面的就有队列等待了
1.单核CPU, 数字在0.00-1.00之间正常
0.00-1.00 之间的数字表示此时路况非常良好,没有拥堵,车辆可以毫无阻碍地通过。
1.00 表示道路还算正常,但有可能会恶化并造成拥堵。此时系统已经没有多余的资源了,管理员需要进行优化。
1.00以上 表示路况不太好了,如果到达2.00表示有桥上车辆一倍数目的车辆正在等待。这种情况你必须进行检查了。
2.多核CPU - 多车道 数字/CPU核数 在0.00-1.00之间正常
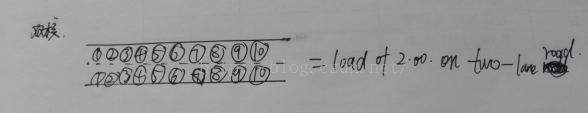
用双核举例,双核的负载已经比单核提高一倍了,那多核的也是同理。
多核CPU的话,满负荷状态的数字为 "1.00 * CPU核数",即双核CPU为2.00,四核CPU为4.00。
3、安全的系统平均负载
这里没有完全的定论,一般来讲70%左右的负载也就是0.7左右应该是没问题的,要根据实际生产环境中实际需求来进行浮动设定
4、应该看哪一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3484
3484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









