









事件起因:
楼主今年手上有个项目,上线后,每天大概15w的访问量,单台pod(公司用的docker),TPS在6-7之间,第一次压测的时候,最好的情况是5个pod,TPS达到了36。楼主当时有点绝望,因为跟我们其他的服务上千的qps差距太大了,但是考虑到这个服务的特殊性,所以没有仔细去验证性能这么差的原因在哪儿。
上线1月多,其实没有遇到过该服务出现并发特别大导致服务不可用,所以也还算稳定。
双11前,公司在搞全链路压测,当然也给我这个服务提要求了,希望能达到1k TPS。楼主当时听闻这个消息,人都傻了..粗略算了一下,起码得200台机器啊。
于是为了这个目标,楼主进行了第二次压测,在压测的时候,发现单台服务器的cpu一直稳定在7%,跟第一次完全没有质的变化,于是,没办法,只能让运维这边加机器,直接干到30个pod,再次压测,TPS最高能达到170了。其实对于楼主的业务来说完全够用了,但是耐不住上面的大佬提的要求啊,无奈,在170的压测报告提出后,领导又找上来了,说为什么上不去,瓶颈卡在哪儿?于是楼主开始了漫长的验证之旅:
1.由于压测的时候,cpu一直很稳定在7%,查看了tomcat参数后,以为是tomcat中的启动时线程数(100)搞小了,但是最大线程数也有800,当时不能验证问题所在,所以找了台vm去测试,但是遇到很多问题,环境问题,机器数量问题,最终搁置了。
2.后来我同事大佬(后简称大佬)说应该不是线程数的问题,于是我们找了一天晚上压测,用arthas观察了线程的状态,发现在30个pod时,每次都只有7个线程在工作,其他的线程状态都是waiting,4个runnable,3个timeWaiting,说明根本没有那么多的线程参与工作,排除了1的可能性。于是,我们又查看cpu,还是稳定在7%,在并发100和400的时候,cpu细微波动,但是接口耗时明显上涨,其实这时候就已经觉得很奇怪了。于是楼主当时去看了下cat监控,楼主服务在压测的时候,出现了一个时间段都是2秒多甚至还有3秒多的请求,而这个请求只做了一件事,就是去第三方服务请求数据,于是楼主去看了下第三方的服务接口耗时,他们的接口耗时居然稳定在600-800之间。这就让楼主更加觉得奇怪了,因为对方的服务很稳定,而且看耗时和请求量,压测完全没有对他们的服务造成任何影响。说明在请求他们服务前,就已经耗时很长了,这个时候,就要跟你们介绍一下arthas的trace命令了(建议百度,楼主当时也是百度的),通过arthas命令去分析楼主调用的第三方服务,一层一层查下去,最后发现是获取http的时候hang住了,获取一个连接居然花了2-3秒,所以判断问题就出在这儿。
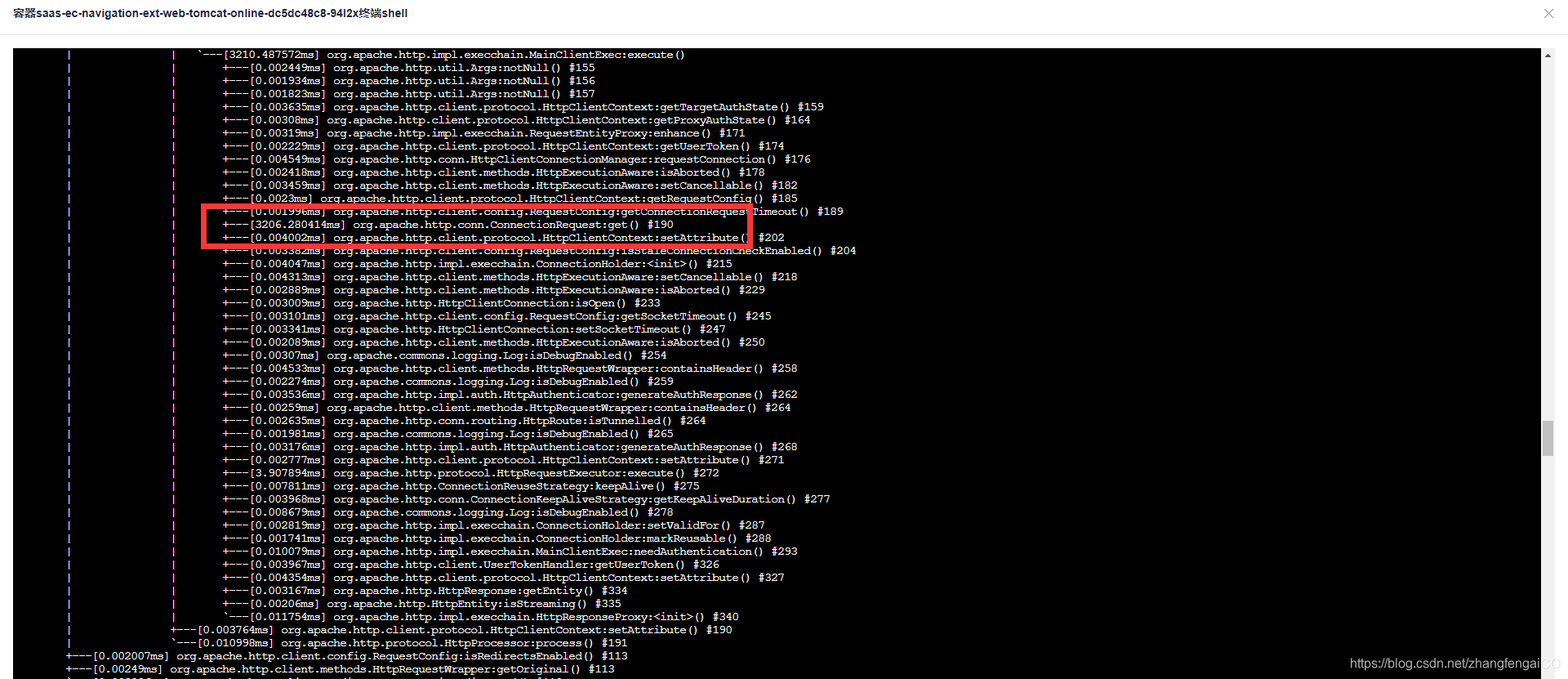
于是查看代码,这个http连接在哪里被调用的,因为楼主是使用的第三方服务提供的skd包,这个http连接的配置就是使用的默认的,最大连接数配置的是100,问题就在这儿。于是跟第三方沟通后,由他们优化后,重新打包;第二天,重新压测,发现使用新的sdk后,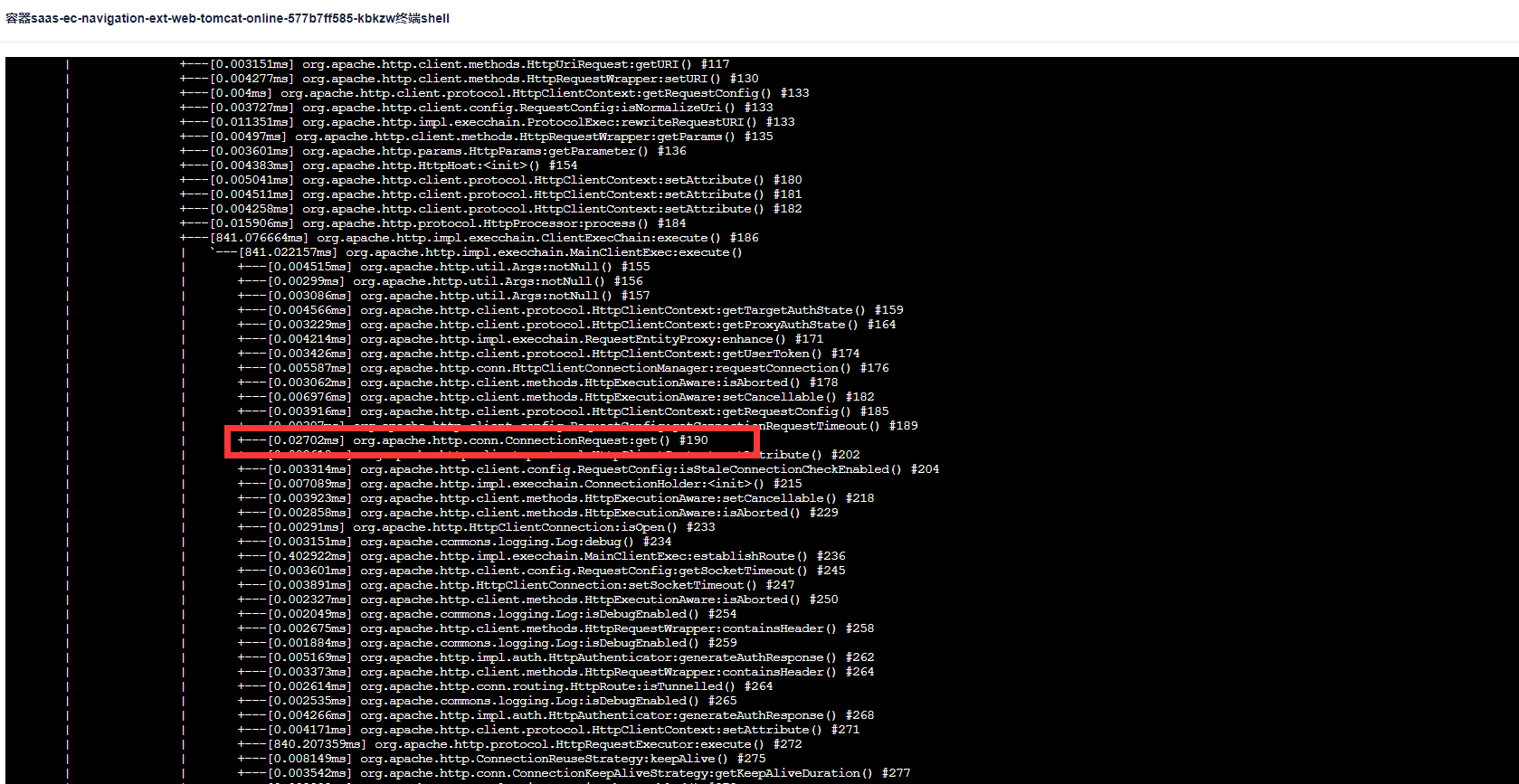
30个pod在800并发的情况下,能达到930TPS了,900并发的时候,已经压到对方瓶颈,耗时直接翻了3倍。在800并发的时候,CPU最高才40%,所以判断其实在这个并发下,还有优化的空间,跟运维那边沟通后,直接从30个pod减容成10个pod,重新压测,发现在800并发的情况下依然可以做到920TPS,此时CPU最高80%。由此判断:在10个pod数就可以支持将近1kTPS,成功完成了上面大佬的要求。
优化之路路阻且长,但是走的越远越能成长,各位共勉!















 9111
9111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









