







工具目录
1.BurpShiroPassiveScan是一款基于BurpSuite的被动式shiro检测插件2.reconftw是对具有多个子域的目标执行全面检查的脚本3.CTFR是一款不适用字典攻击也不适用蛮力获取的子域名的工具4.JR-scan是一款一键实现基本信息收集,支持POC扫描,支持利用AWVS探测的工具5.dirsearch-Web是一种成熟的命令行工具,旨在暴力破解Web服务器中的目录和文件
1.BurpShiroPassiveScan
介绍
BurpShiroPassiveScan 一个希望能节省一些渗透时间好进行划水的扫描插件
该插件会对BurpSuite传进来的每个不同的域名+端口的流量进行一次shiro检测
目前的功能如下
•shiro框架指纹检测•shiro加密key检测
安装
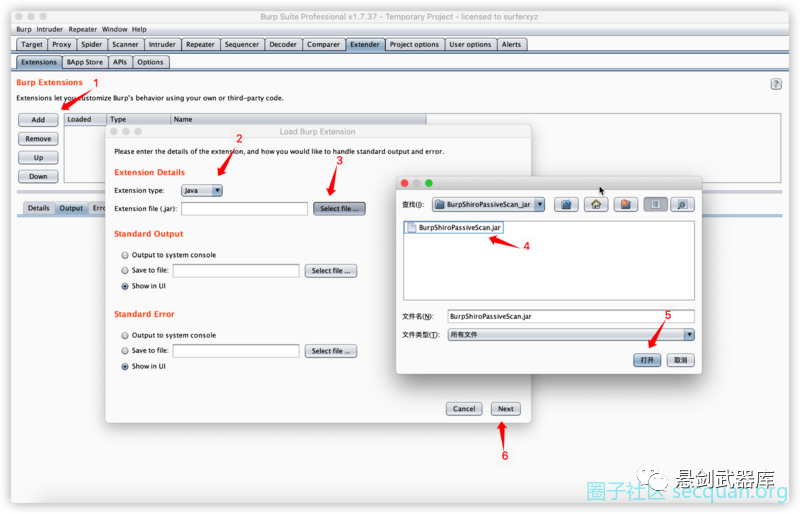
这是一个 java maven项目
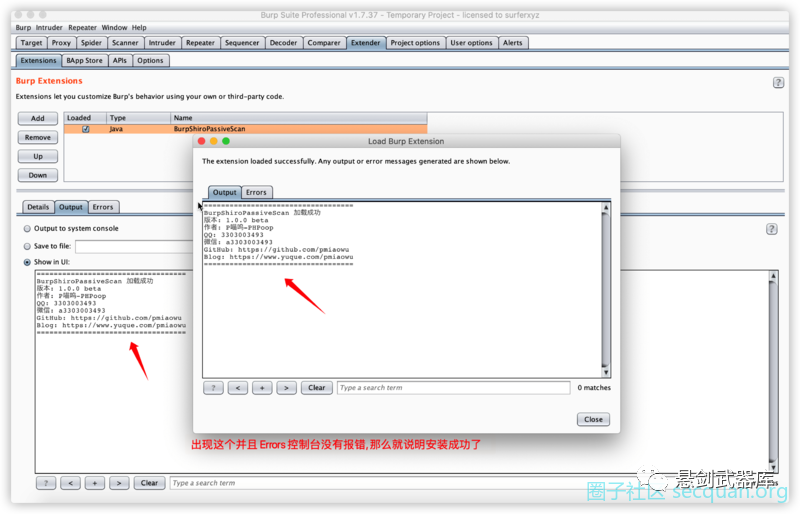
如果你想自己编译的话, 那就下载本源码自己编译成 jar包 然后进行导入BurpSuite
如果不想自己编译, 那么下载该项目提供的 jar包 进行导入即可
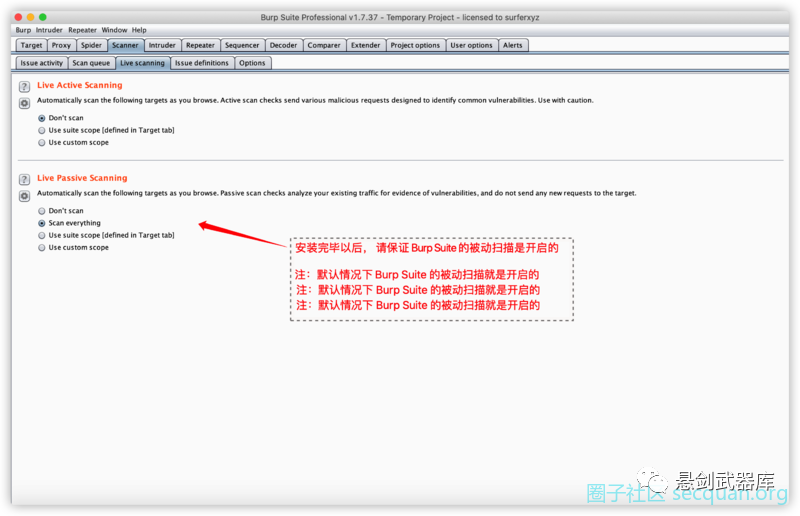
检测方法选择
目前有一种方法进行 shiro框架 key的检测
1.l1nk3r师傅 的 基于原生shiro框架 检测方法
l1nk3r师傅的检测思路地址: https://mp.weixin.qq.com/s/do88_4Td1CSeKLmFqhGCuQ
目前这两种方法都已经实现!!!
根据我的测试 l1nk3r师傅 的更加适合用来检测“shiro key”这个功能!!!
使用 l1nk3r师傅 这个方法 对比 URLDNS 我认为有以下优点
1.去掉了请求dnslog的时间, 提高了扫描速度, 减少了大量的额外请求2.避免了有的站点没有 dnslog 导致漏报3.生成的密文更短, 不容易被waf拦截
基于以上优点, 我决定了, 现在默认使用 l1nk3r师傅 这个方法进行 shiro key的爆破
使用方法
例如我们正常访问网站
访问完毕以后, 插件就会自动去进行扫描
如果有结果那么插件就会在以下地方显示
•Extender•Scanner-Issue activity
问题查看
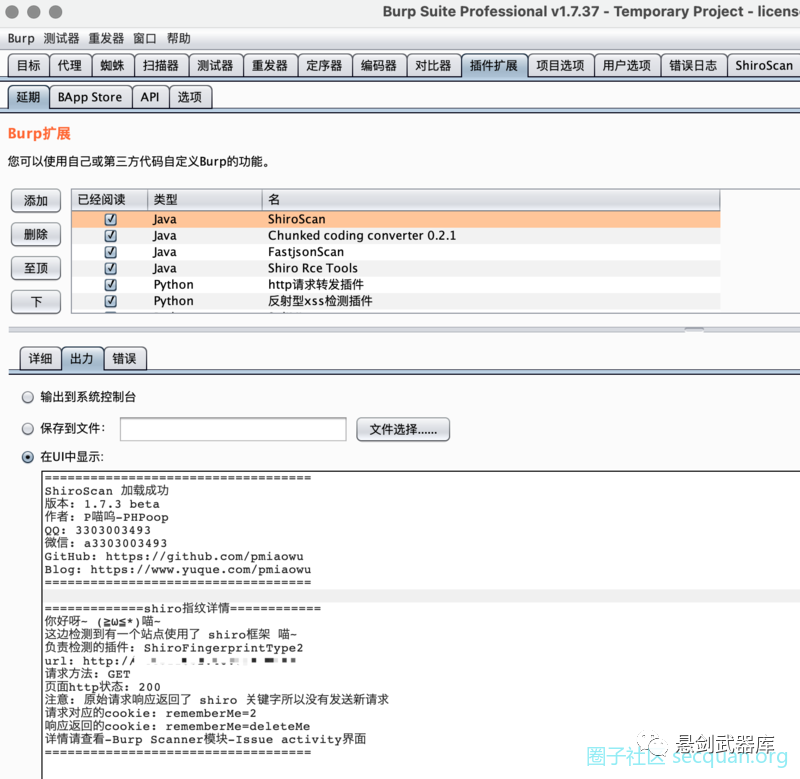
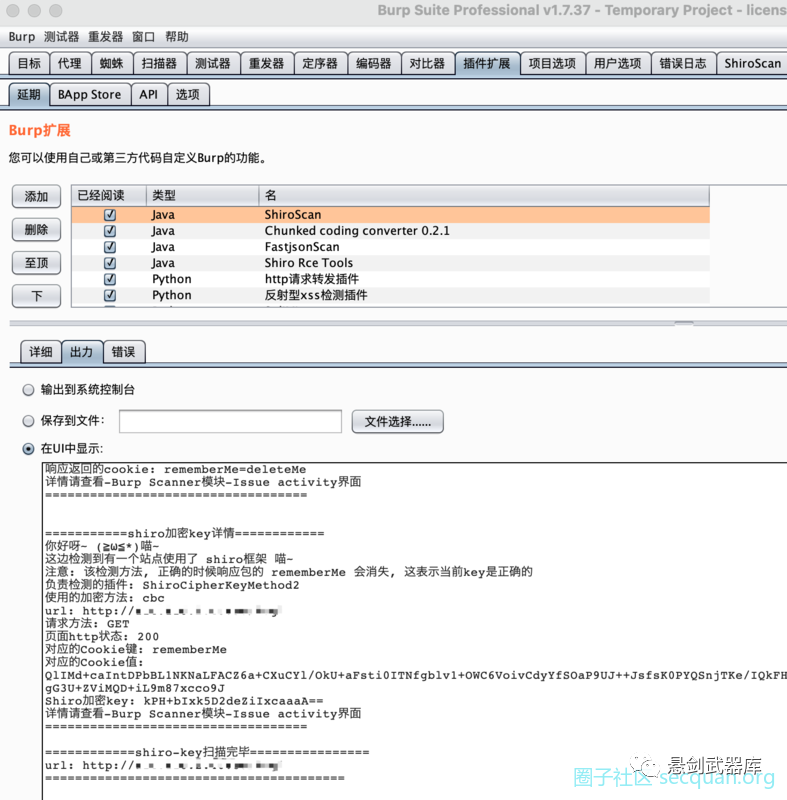
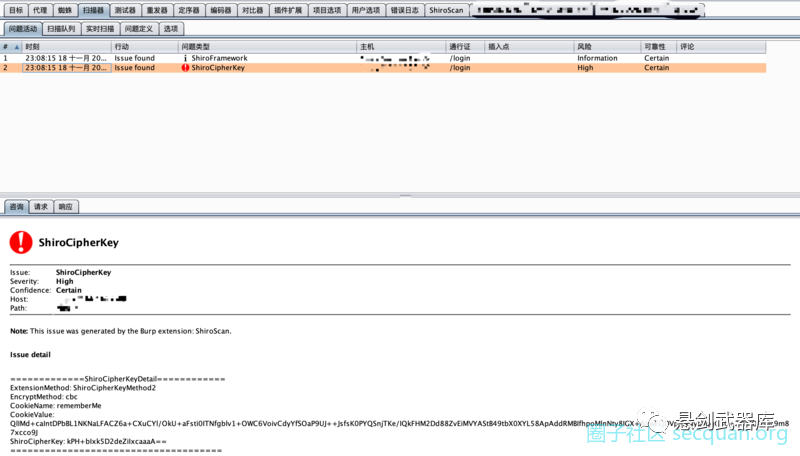
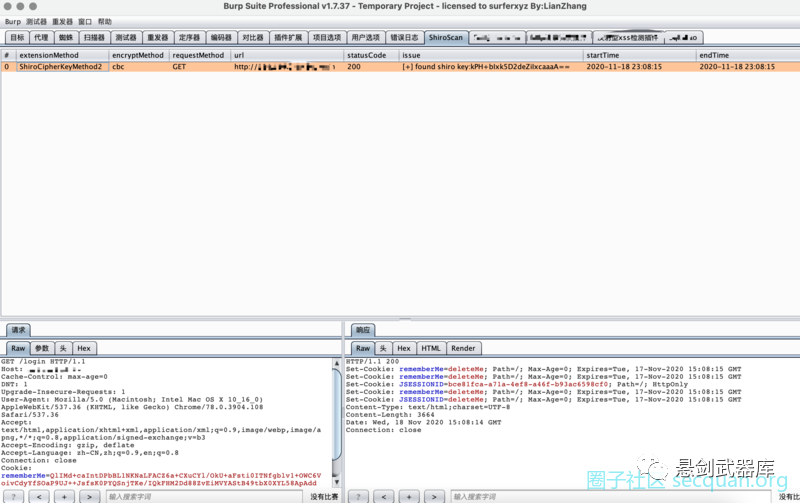
shiro加密key查看
shiro加密方法
目前搭配了两种加密方法 cbc 与 gcm
cbc就是经常使用的
gcm就是最新出的
tag界面查看漏洞情况
现在可以通过tag界面查看漏洞情况了
分别会返回
•waiting for test results = 扫描shiro key 中•shiro key scan out of memory error = 扫描shiro key时,发生内存错误•shiro key scan diff page too many errors = 扫描shiro key时,页面之间的相似度比对失败太多•shiro key scan task timeout = 扫描shiro key时,任务执行超时•shiro key scan unknown error = 扫描shiro key时,发生未知错误•[-] not found shiro key = 没有扫描出 shiro key•[+] found shiro key: xxxxxx = 扫描出了 shiro key
注意: 发生异常错误的时候,不用担心下次不会扫描了,下次访问该站点的时候依然会尝试进行shiro key扫描,直到扫描完毕为止
项目地址
https://github.com/suifengg/BurpShiroPassiveScan
2.reconftw
介绍
这是一个简单的脚本,旨在对具有多个子域的目标执行全面检查。
安装
git clone https://github.com/six2dez/reconftw
cd reconftw
chmod +x *.sh
./install.sh
./reconftw.sh -d target.com -a
用法
./reconfw.sh -h
$ ./reconftw.sh -h
██▀███ ▓█████ ▄████▄ ▒█████ ███▄ █ █████▒▄▄▄█████▓ █ █░
▓██ ▒ ██▒▓█ ▀ ▒██▀ ▀█ ▒██▒ ██▒ ██ ▀█ █ ▓██ ▒ ▓ ██▒ ▓▒▓█░ █ ░█░
▓██ ░▄█ ▒▒███ ▒▓█ ▄ ▒██░ ██▒▓██ ▀█ ██▒▒████ ░ ▒ ▓██░ ▒░▒█░ █ ░█
▒██▀▀█▄ ▒▓█ ▄ ▒▓▓▄ ▄██▒▒██ ██░▓██▒ ▐▌██▒░▓█▒ ░ ░ ▓██▓ ░ ░█░ █ ░█
░██▓ ▒██▒░▒████▒▒ ▓███▀ ░░ ████▓▒░▒██░ ▓██░░▒█░ ▒██▒ ░ ░░██▒██▓
░ ▒▓ ░▒▓░░░ ▒░ ░░ ░▒ ▒ ░░ ▒░▒░▒░ ░ ▒░ ▒ ▒ ▒ ░ ▒ ░░ ░ ▓░▒ ▒
░▒ ░ ▒░ ░ ░ ░ ░ ▒ ░ ▒ ▒░ ░ ░░ ░ ▒░ ░ ░ ▒ ░ ░
░░ ░ ░ ░ ░ ░ ░ ▒ ░ ░ ░ ░ ░ ░ ░ ░
░ ░ ░░ ░ ░ ░ ░ ░
░
by @six2dez1(Twitter) or @six2dez(rest of sites)
Params (-d always required):
./reconftw.sh -d target.com Target domain (required always)
./reconftw.sh -l targets.txt Web list (required only with -w)
Flags (1 required):
./reconftw.sh -a All checks (default and recommended)
./reconftw.sh -s Only subdomains
./reconftw.sh -g Only Google Dorks
./reconftw.sh -w Only web scan
./reconftw.sh -h Show this help
Examples:
./reconftw.sh -d target.com -a -> All checks
./reconftw.sh -d target.com -s -> Only subdomains
./reconftw.sh -d target.com -g -> Only Google Dorks
./reconftw.sh -d target.com -l targets.txt -w -> Only Web Scan (Target list required)
用例
./reconfw.sh -a baidu.com
特征
Google Dorks(基于deggogle_hunter)
子域枚举(多种工具:Pasive,分辨率,蛮力和排列)
Sub TKO(副翼和核)
探测(httpx)
Web屏幕截图(水色)
模板扫描仪(核)
端口扫描(naabu)
网址提取(waybackurls和gau)
模式搜索(gf和gf模式)
参数发现(paramspider和arjun)
XSS(Gxss和dalfox)
GitHub检查(git-hound)
Favicon Real IP(收藏夹)
Javascript检查(JSFScan.sh)
目录模糊/发现(dirsearch和ffuf)
Cors(CORScanner)
SSL检查(testssl)
您也可以只执行子域扫描,网络扫描或Google Dork。请记住,webscan需要带有-l标志的目标列表。
它使用目标域的名称在Recon /文件夹中生成并输出,例如Recon / target.com /
项目地址
https://github.com/six2dez/reconftw
3.CTFR
介绍
您会错过AXFR技术吗?此工具允许您在几秒钟内从HTTP S网站获取子域。
这个怎么运作?CTFR既不使用字典攻击也不使用蛮力,而只是滥用证书透明度日志。
有关CT日志的详细信息,请www.certificate-transparency.org和crt.sh。[1]
入门
请按照以下说明安装运行CTFR
先决条件
R确保安装以下工具
Python 3.0 or later.
pip3 (sudo apt-get install python3-pip).
正在安装
$ git clone https://github.com/UnaPibaGeek/ctfr.git
$ cd ctfr
$ pip3 install -r requirements.txt
Running
$ python3 ctfr.py --help
用法
-d --domain [target_domain] (required)
-o --output [output_file] (optional)
例子
$ python3 ctfr.py -d starbucks.com
$ python3 ctfr.py -d facebook.com -o /home/shei/subdomains_fb.txt
项目地址
https://github.com/UnaPibaGeek/ctfr
4.JR-scan
介绍
利用python3写的综合扫描工具,可“一键”实现基本信息收集(端口、敏感目录、WAF、服务、操作系统),支持POC扫描(可自行添加POC,操作简单),支持利用AWVS探测,未来争取实现xray联动。
在启动扫描器后,傻瓜式操作即可完成扫描。
扫描器允许进行单个扫描,批量扫描(从文件列表里扫描网站),C段扫描
启动方法:直接利用Python3运行JR.py即可
提示:最好是在liux环境下运行,win的话,可能会出现编码问题!!!
安装
git clone https://github.com/suifengg/JR-scan
python3.8 /JR/JR.PY
启动界面
数据库界面
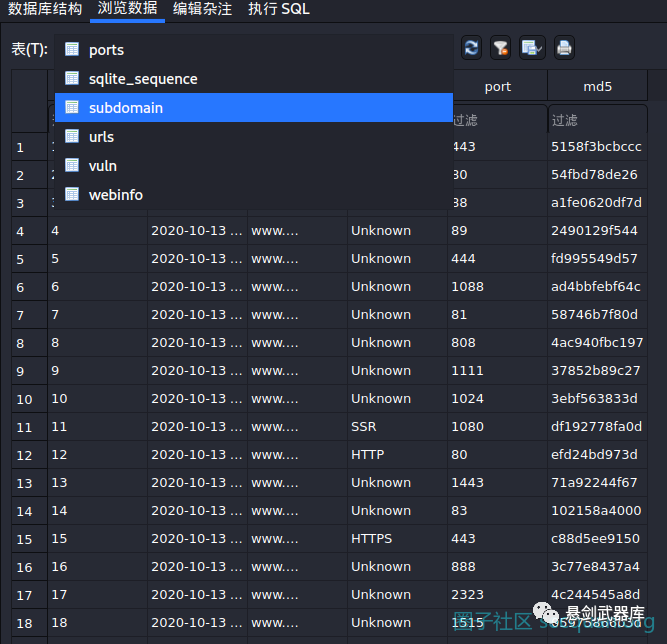
网站整体界面
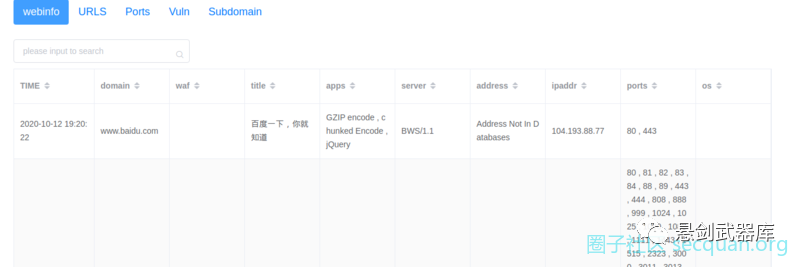
端口界面
URL界面
漏洞界面

项目地址
https://github.com/suifengg/JR-scan
5.dirsearch-Web路径扫描器
总览
•Dirsearch是一种成熟的命令行工具,旨在暴力破解Web服务器中的目录和文件。•随着6年的增长,dirsearch现在已成为顶级的Web内容扫描仪。•作为功能丰富的工具,dirsearch为用户提供了执行复杂的Web内容发现的机会,其中包括单词列表的许多矢量,高精度,出色的性能,高级的连接/请求设置,现代的蛮力技术和出色的输出。
安装及使用
git clone https://github.com/maurosoria/dirsearch.git
cd dirsearch
python3 dirsearch.py -u <URL> -e <EXTENSIONS>
•要使用SOCKS代理或../在单词列表中使用它,您需要使用以下命令安装点子requirements.txt:pip3 install -r requirements.txt•如果您使用的是Windows,并且没有git,则可以在此处[2]安装ZIP文件。Dirsearch还支持Docker[3]
Dirsearch需要python 3或更高版本
特征
•快速•易于使用•多线程•通配符响应过滤(无效的网页)•保持活跃的联系•支持多种扩展•支持每种HTTP方法•支持HTTP请求数据•扩展不包括•报告(纯文本,JSON,XML,Markdown,CSV)•递归暴力破解•IP范围内的目标枚举•子目录暴力破解•力扩展•HTTP和SOCKS代理支持•HTTP cookie和标头支持•文件中的HTTP标头•用户代理随机化•代理主机随机化•批量处理•请求延迟•429个响应码检测•多种单词列表格式(小写,大写,大写)•文件中的默认配置•通过主机名强制请求的选项•添加自定义后缀和前缀的选项•可以将响应代码列入白名单,支持范围(-i 200,300-399)•可以将响应代码列入黑名单,支持范围(-x 404,500-599)•选择按大小排除响应•选择排除文字回复•选择排除正则表达式的响应•选择通过重定向排除响应•仅显示响应长度在范围内的项目的选项•从每个单词列表条目中删除所有扩展名的选项•静音模式•调试模式
关于词表
摘要:
Wordlist必须是一个文本文件,每一行都是一个端点。关于扩展名,与其他工具不同,如果不使用该-f标志,dirsearch不会将扩展名附加到每个单词上。默认情况下,仅%EXT%单词表中的关键字将被扩展名(-e <extensions>)替换。
详细资料:
•单词表中的每一行都将照此处理,除非使用特殊关键字%EXT%时,它将为作为参数传递的每个扩展名(-e | --extensions)生成一个条目。
例:
root/
index.%EXT%
传递扩展名“ asp”和“ aspx”(-e asp,aspx)将生成以下字典:
root/
index
index.asp
index.aspx
•对于没有%EXT%的单词列表(例如SecLists[4]),您需要使用*-f | --force-extensions**开关可将扩展名附加到单词表中的每个单词以及“ /”。对于不想强制使用的单词列表中的条目,可以在它们的末尾添加%NOFORCE%*,以便dirsearch不会附加任何扩展名。
例:
admin
home.%EXT%
api%NOFORCE%
通过**-f** / --force-extensions标志(-f -e php,html)传递扩展名“ php”和“ html”将生成以下字典:
admin
admin.php
admin.html
admin/
home
home.php
home.html
api
要使用多个单词列表,可以用逗号分隔单词列表。示例:-w wordlist1.txt,wordlist2.txt
选件
Usage: dirsearch.py [-u|--url] target [-e|--extensions] extensions [options]
Options:
--version show program's version number and exit
-h, --help show this help message and exit
Mandatory:
-u URL, --url=URL Target URL
-l FILE, --url-list=FILE
URL list file
--cidr=CIDR Target CIDR
-e EXTENSIONS, --extensions=EXTENSIONS
Extension list separated by commas (Example: php,asp)
-X EXTENSIONS, --exclude-extensions=EXTENSIONS
Exclude extension list separated by commas (Example:
asp,jsp)
-f, --force-extensions
Add extensions to the end of every wordlist entry. By
default dirsearch only replaces the %EXT% keyword with
extensions
Dictionary Settings:
-w WORDLIST, --wordlists=WORDLIST
Customize wordlists (separated by commas)
--prefixes=PREFIXES
Add custom prefixes to all entries (separated by
commas)
--suffixes=SUFFIXES
Add custom suffixes to all entries, ignore directories
(separated by commas)
--only-selected Only entries with selected extensions or no extension
+ directories
--remove-extensions
Remove extensions in all wordlist entries (Example:
admin.php -> admin)
-U, --uppercase Uppercase wordlist
-L, --lowercase Lowercase wordlist
-C, --capital Capital wordlist
General Settings:
-r, --recursive Bruteforce recursively
-R DEPTH, --recursion-depth=DEPTH
Maximum recursion depth
-t THREADS, --threads=THREADS
Number of threads
--subdirs=SUBDIRS Scan sub-directories of the given URL[s] (separated by
commas)
--exclude-subdirs=SUBDIRS
Exclude the following subdirectories during recursive
scan (separated by commas)
-i STATUS, --include-status=STATUS
Include status codes, separated by commas, support
ranges (Example: 200,300-399)
-x STATUS, --exclude-status=STATUS
Exclude status codes, separated by commas, support
ranges (Example: 301,500-599)
--exclude-sizes=SIZES
Exclude responses by sizes, separated by commas
(Example: 123B,4KB)
--exclude-texts=TEXTS
Exclude responses by texts, separated by commas
(Example: 'Not found', 'Error')
--exclude-regexps=REGEXPS
Exclude responses by regexps, separated by commas
(Example: 'Not foun[a-z]{1}', '^Error$')
--exclude-redirects=REGEXPS
Exclude responses by redirect regexps or texts,
separated by commas (Example: 'https://okta.com/*')
--calibration=PATH Path to test for calibration
--random-agent Choose a random User-Agent for each request
--minimal=LENGTH Minimal response length
--maximal=LENGTH Maximal response length
-q, --quiet-mode Quiet mode
--full-url Print full URLs in the output
--no-color No colored output
Request Settings:
-m METHOD, --http-method=METHOD
HTTP method (default: GET)
-d DATA, --data=DATA
HTTP request data
-H HEADERS, --header=HEADERS
HTTP request header, support multiple flags (Example:
-H 'Referer: example.com' -H 'Accept: */*')
--header-list=FILE File contains HTTP request headers
-F, --follow-redirects
Follow HTTP redirects
--user-agent=USERAGENT
--cookie=COOKIE
Connection Settings:
--timeout=TIMEOUT Connection timeout
--ip=IP Server IP address
-s DELAY, --delay=DELAY
Delay between requests
--proxy=PROXY Proxy URL, support HTTP and SOCKS proxies (Example:
localhost:8080, socks5://localhost:8088)
--proxy-list=FILE File contains proxy servers
--matches-proxy=PROXY
Proxy to replay with found paths
--max-retries=RETRIES
-b, --request-by-hostname
By default dirsearch requests by IP for speed. This
will force requests by hostname
--exit-on-error Exit whenever an error occurs
--debug Debug mode
Reports:
--simple-report=OUTPUTFILE
--plain-text-report=OUTPUTFILE
--json-report=OUTPUTFILE
--xml-report=OUTPUTFILE
--markdown-report=OUTPUTFILE
--csv-report=OUTPUTFILE
注意:您可以通过编辑default.conf文件来更改dirsearch的默认配置(默认扩展名,超时,单词列表位置等)。
使用
简单实用
python3 dirsearch.py -u https://target
python3 dirsearch.py -e php,html,js -u https://target
python3 dirsearch.py -e php,html,js -u https://target -w /path/to/wordlist
递归扫描
通过使用-r | --recursive参数,dirsearch将自动对找到的目录进行暴力破解。
python3 dirsearch.py -e php,html,js -u https://target -r
您可以使用-R或--recursion-depth设置最大递归深度
python3 dirsearch.py -e php,html,js -u https://target -r -R 3
线程数
线程号(-t | --threads)反映了单独的暴力破解进程的数量,每个进程将针对目标执行路径暴力破解。因此,线程数越大,目录搜索运行得越快。默认情况下,线程数为20,但是如果您想加快进度,可以增加它。
尽管如此,速度实际上仍然不可控,因为它很大程度上取决于服务器的响应时间。作为警告,我们建议您不要将线程数过大,以免受到过多自动化请求的影响,因此应对其进行调整以适合您要扫描的系统的功能。
python3 dirsearch.py -e php,htm,js,bak,zip,tgz,txt -u https://target -t 30
前缀/后缀
•--prefixes:向所有条目添加自定义前缀
python3 dirsearch.py -e php -u https://target --prefixes .,admin,_,~
基本单词表:
tools
生成的前缀:
.tools
admintools
_tools
~tools
•--suffixes:向所有条目添加自定义后缀
python3 dirsearch.py -e php -u https://target --suffixes ~,/
基本单词表:
index.php
internal
生成后缀:
index.php~
index.php/
internal~
internal/
排除扩展
使用**-X | --exclude-extensions**与您的exclude-extension列表一起删除单词列表中具有给定扩展名的所有条目
python3 dirsearch.py -e asp,aspx,htm,js -u https://target -X php,jsp,jspx
基本单词表:
admin
admin.%EXT%
index.html
home.php
test.jsp
后:
admin
admin.asp
admin.aspx
admin.htm
admin.js
index.html
词表格式
支持的单词列表格式:大写,小写,大写
小写:
admin
index.html
test
大写:
ADMIN
INDEX.HTML
TEST
筛选器
使用**-i | --include-status和-x | --exclude-status**选择允许和不允许的响应状态代码
python3 dirsearch.py -e php,html,js -u https://target -i 200,204,400,403 -x 500,502,429
还支持**--exclude-sizes,-- **exclude-texts,-- exclude-regexps和**--exclude-redirects**以使用更高级的过滤器
python3 dirsearch.py -e php,html,js -u https://target --exclude-sizes 1B,243KB
python3 dirsearch.py -e php,html,js -u https://target --exclude-texts "403 Forbidden"
python3 dirsearch.py -e php,html,js -u https://target --exclude-regexps "^Error$"
扫描子目录
扫描子目录
您可以从URL中使用**--subdirs**扫描子目录。
python3 dirsearch.py -e php,html,js -u https://target --subdirs admin/,folder/,/
此功能的反向版本是**--exclude-subdirs**,它可以防止目录搜索进行强行强制执行的目录,而在执行递归扫描时,这些目录不应被强行使用。
python3 dirsearch.py -e php,html,js -u https://target --recursive -R 2 --exclude-subdirs "server-status/,%3f/"
代理
Dirsearch支持SOCKS和HTTP代理,具有两个选项:代理服务器或代理服务器列表。
python3 dirsearch.py -e php,html,js -u https://target --proxy 127.0.0.1:8080
python3 dirsearch.py -e php,html,js -u https://target --proxy socks5://10.10.0.1:8080
python3 dirsearch.py -e php,html,js -u https://target --proxylist proxyservers.txt
报告
Dirsearch允许用户将输出保存到文件中。它支持多种输出格式,例如text或json,并且我们会不断更新新格式
python3 dirsearch.py -e php -l URLs.txt --plain-text-report report.txt
python3 dirsearch.py -e php -u https://target --json-report target.json
python3 dirsearch.py -e php -u https://target --simple-report target.txt
其他命令
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt -H "X-Forwarded-Host: 127.0.0.1" -f
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt -t 100 -m POST --data "username=admin"
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --random-agent --cookie "isAdmin=1"
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --json-report=target.json
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --header-list rate-limit-bypasses.txt
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --minimal 1
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt -q --stop-on-error
python3 dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --full-url
python3 dirsearch.py -u https://target -w db/dicc.txt --no-extension
还有更多功能,需要自己发现哦
提示
•要以每秒的请求速率运行dirsearch,请尝试 -t <rate> -s 1•是否要查找配置文件或备份?试用--suffixes ~和--prefixes .•对于您不想强制扩展的某些端点,请%NOFORCE%在它们的末尾添加•是否只想查找文件夹/目录?结合--no-extension和--suffixes /!•的组合--cidr,-F并且-q将降低大部分噪声+假阴性的用CIDR当暴力破解
支持Docker
安装Docker
curl -fsSL https://get.docker.com | bash
建立映像目录搜寻
创建图像
docker build -t “ dirsearch:v0.4.1 ” 。
使用目录搜索
用于
docker run -it --rm "dirsearch:v0.4.1" -u target -e php,html,js,zip
项目地址
https://github.com/suifengg/dirsearch
References
[1] www.certificate-transparency.org和crt.sh。: http://www.certificate-transparency.org和crt.sh。[2] 此处: https://github.com/maurosoria/dirsearch/archive/master.zip[3] Docker: https://github.com/maurosoria/dirsearch#support-docker[4] SecLists: https://github.com/danielmiessler/SecLists














 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









