







 文章讲述了在处理批量数据录入的业务场景中,对一个涉及多表查询的SQL进行优化的过程。初版SQL由于子查询和OR语句导致执行效率低下。经过两次优化,包括用内连接替换子查询,使用UNIONALL代替OR,并移除GROUPBY和SQL函数,执行时间从最初的50ms降低到5ms。作者对于进一步能否将执行时间缩短到1ms提出疑问。
文章讲述了在处理批量数据录入的业务场景中,对一个涉及多表查询的SQL进行优化的过程。初版SQL由于子查询和OR语句导致执行效率低下。经过两次优化,包括用内连接替换子查询,使用UNIONALL代替OR,并移除GROUPBY和SQL函数,执行时间从最初的50ms降低到5ms。作者对于进一步能否将执行时间缩短到1ms提出疑问。
业务背景
我上篇文章介绍了一个规则引擎的简单使用,主要就是为了众包业务批量录入数据的一些校验的统一管理,
很快就派上了用途,需要新增一个规则
针对录入的每条数据,需要查询历史数据作为对比,看看是存在相同的数据,然后进行限制
这个需求简单分析下前提
1.批量数据录入,如果单条数据查询过长,肯定是不能接受的
2.查询数据所需参数很多,单独为了这次查询建很多索引,不现实。
所以只能从SQL本身来进行优化
3.表的数据量大概百万级别
初版查询SQL
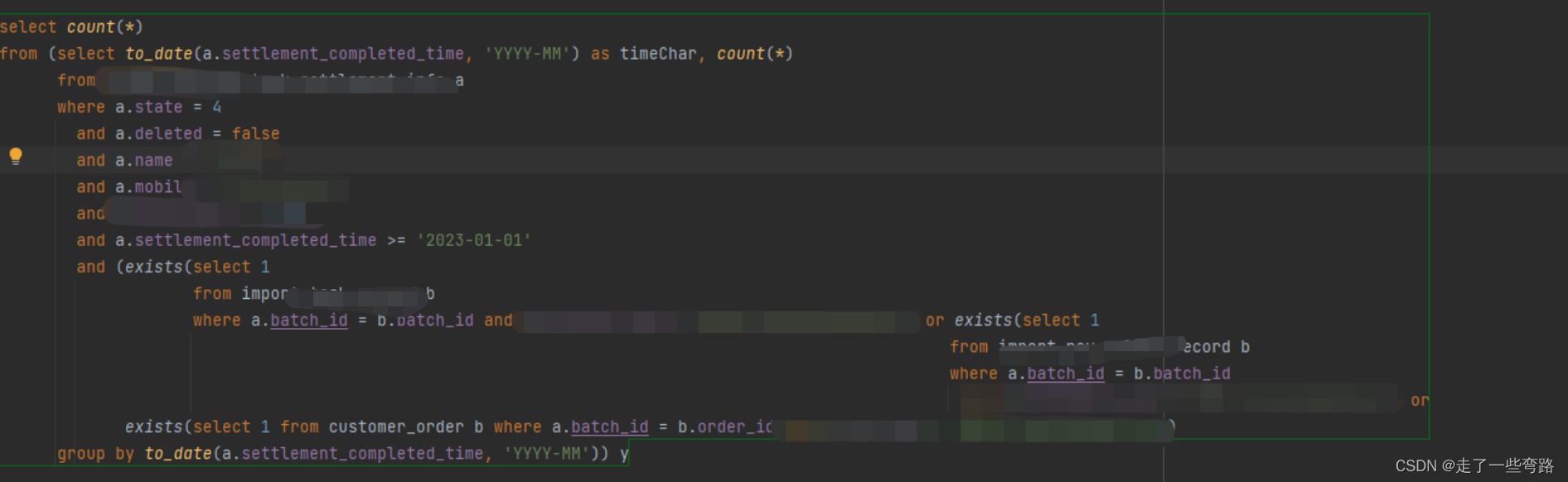
主表A,关联三个业务子表,
根据主表的一个varchar类型的字段(实际存储格式为时间,前期设计是由外部系统传入的)以及其他多个参数
进行分月查询前几个月存在相同的数据的个数,
然后进行校验
这段SQL有什么问题呢
1.子查询问题,
2.or语句问题
如下图所示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









