







 该项目提供了一种基于Bert+MLP的层次分类解决方案,涵盖了数据标注、模型训练、转换和部署的全过程。文章介绍了环境配置、数据准备、模型训练及优化、模型转为ONNX模型并进行推理,以及服务部署的详细步骤。目前存在的问题是模型准确率为78%,未来将优化算法和提升推理速度。
该项目提供了一种基于Bert+MLP的层次分类解决方案,涵盖了数据标注、模型训练、转换和部署的全过程。文章介绍了环境配置、数据准备、模型训练及优化、模型转为ONNX模型并进行推理,以及服务部署的详细步骤。目前存在的问题是模型准确率为78%,未来将优化算法和提升推理速度。
1、层次分类介绍
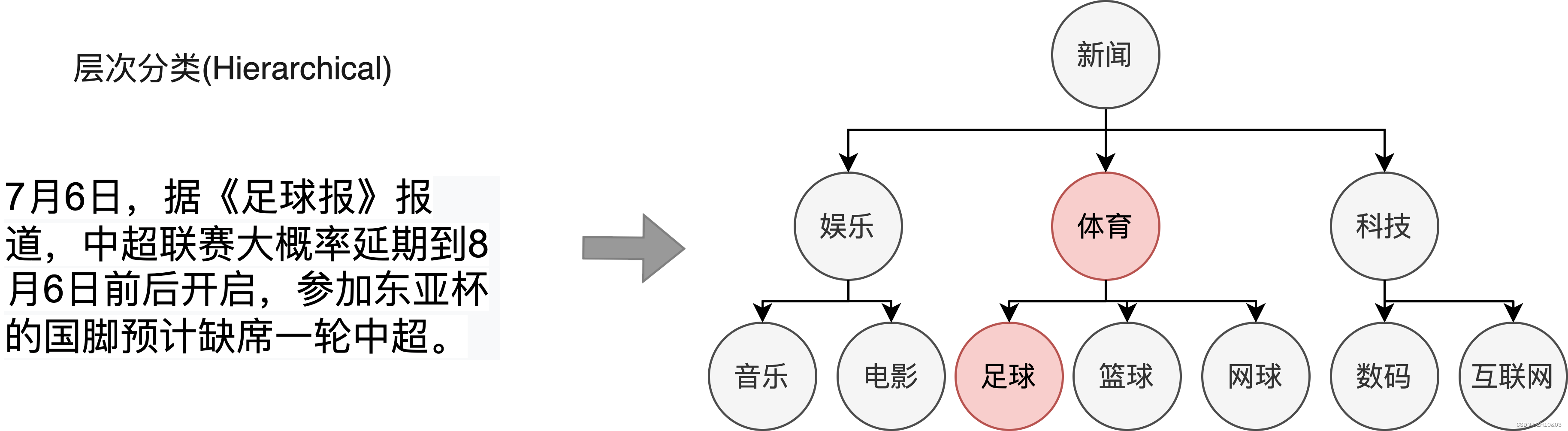
本项目提供通用场景下基于Bert+MLP的层次分类端到端应用方案,打通数据标注-模型训练-模型调优-模型转换-预测部署全流程,有效缩短开发周期,降低AI开发落地门槛。层次文本分类任务的中数据样本具有多个标签且标签之间存在特定的层级结构,目标是预测输入句子/文本可能来自于不同级标签类别中的某一个或几个类别。以下图新闻文本分类为例,该新闻的一级标签为体育,二级标签为足球,体育与足球之间存在层级关系。在现实场景中,大量的数据如新闻分类、专利分类、学术论文分类等标签集合存在层次化结构,需要利用算法为文本自动标注更细粒度和更准确的标签。
2、快速开始
2.1、运行环境
fastapi==0.108.0
numpy==1.24.4
onnxruntime==1.16.3
scikit_learn==1.0.2
torch==1.9.1+cu111
tqdm==4.64.0
transformers==4.30.2
uvicorn==0.25.0
python==3.8
2.2、代码结构
├──_apisever.py
├──_apisever_v1.py ##--API
├──_config.py
├──_data
│___└──_data.txt ##--训练数据
├──_data_load.py ##--数据加载
├──_Dockerfile
├──_gunicorn_conf.py ##--gunicorn高并发设置
├──_index_to_label.json
├──_label_to_index.json
├──_logs
├──_model
│___├──_bert-base-chinese_ ##--#预训练模型
│___└──_dx_model.pth ##--训练后得到的模型
├──_label.py ##--标签转换
├──_model_all.py
├──_model_predict.py ##--模型推理
├──_model_train.py ##--模型训练
├──_model_retrain.py ##--retrain
├──predict.py
├── model_to_onnx.py ##--模型转换为onnx
├──pytorch_gpu.zip ##--环境
├──dx_pytorch_gpu_uvicorn.tar ##--最终镜像
└──_requirements.txt
2.3、数据准备
训练需要准备指定格式的标注数据集,如果没有已标注的数据集,进行文本分类数据标注。指定格式本地数据集目录结构:
data/
├── data.txt #训练数据
data.txt文件格式:
政治_政治竞选 土耳其大选投票倒计时 两阵营对决今再冲刺。土耳其总统选举倒计时,基里切达罗格卢和埃尔多安都在做最后的竞选活动。据本台驻伊斯坦布尔记者AnneAndlauer报道称,艾尔多安今天在伊斯坦布尔的几个地区举行多场集会。基里切达罗格卢则将在首都安卡拉他的竞选宣传,包括与低收入家庭会面,预计他将在集会上宣传他的经济计划。反对派在第一轮竞选前就将经济作为竞选的核心…
label包含:
外交合作,外交会晤,科技会议,军事演习,政治竞选、海洋安全、经济援助…等军事、政治、经济、安全、外交、科技等6大类领域且每个领域分别包含10类场景。
2.4、模型训练
2.4.1 model_train.py
CUDA_VISIBLE_DEVICES=1,6 python model_train.py --train_path ./data/data.txt --save_model_path ./model/dx_full_model.pth --num_labels 60 --batch_size 8 --num_epochs 50 --learning_rate 2e-5 --max_seq_len 512
可支持配置的参数:
save_model_path :保存训练模型的目录;默认保存在当前目录model文件夹下。
max_seq_length:分词器tokenizer使用的最大序列长度。请根据文本长度选择,通常推荐128、256或512,若出现显存不足,请适当调低这一参数;默认为512。
batch_size :批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为8。
learning_rate :训练最大学习率;默认为2e-5。
num_epochs: 训练轮次,使用早停法时可以选择100;默认为3。
num_labels :层次标签总数
from_pretrained:预训练模型地址。默认bert
model_train.py部分代码如下:
import torch
from torch.utils.data import Dataset, DataLoader, random_split
from transformers import BertTokenizer, AdamW
from transformers import BertModel
from data_load import load_data, CustomDataset
from sklearn.metrics import accuracy_score
from tqdm import tqdm
import torch.nn as 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









