







1.索引(index)在数据库中是如何设计实现的
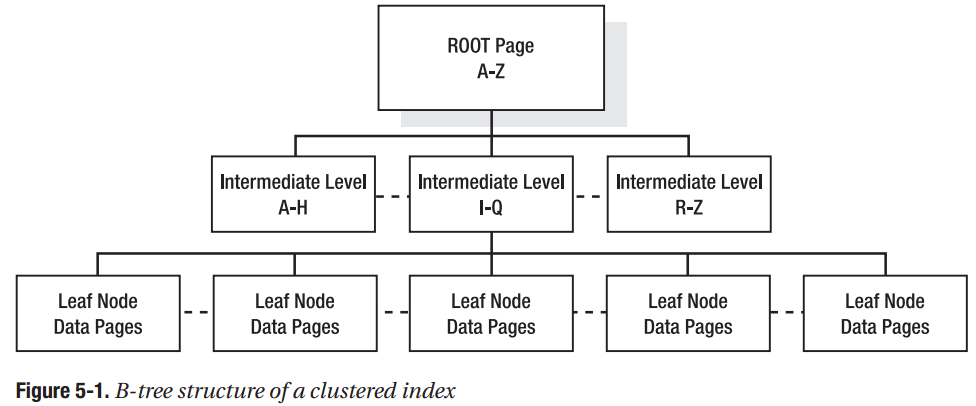
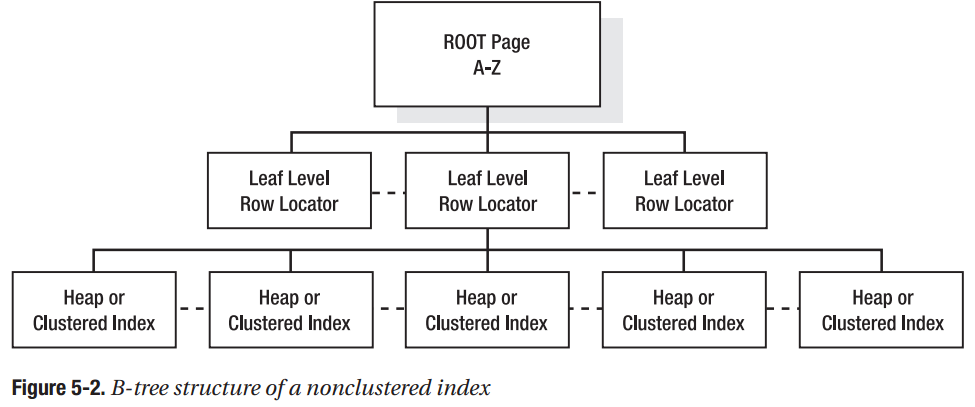
所有的索引(index)都存储在一个 B-tree 的数据结构当中,索引(index)的开始节点作为 B-tree 的根节点。其中的 索引(index)作为中间节点一起组成一棵 B-tree;中间节点是由索引列数据组成的(由于中间节点的大小的一样,所以索引列的不能过大,不然一个节点容纳的索引列太少,对应的查找时间就会增加)。在 B-tree 的底部就是叶节点;叶节点根据索引(index)是聚集索引(clustered index)还是非聚集索引(nonclustered index)而有所不同。
如果是聚集索引(clustered index),叶节点实际是数据页面本身;(见下图 Figure 5-1)
如果非聚集索引(nonclustered index),叶节点是一个指针(pointer),它指向一个heap结构或者聚集索引的数据页面。(见下图 Figure 5-2)
聚集索引决定了table中数据的物理存储方式,一个table只能有一个聚集索引(clustered index)。我的理解就是table中的数据在物理存储上按照聚集索引进行排序。所以后面的内容也讲到:聚集索引列最好是那些不会被频繁修改的列,否则整个数据表的数据会经常移动的,数据库的性能就会很差。
2.索引列(index column)如何选择
前文已经讲述了index是用一个B-tree来保存的,所以接下来讲解如何选择索引,应该就容易理解了。
聚集索引(clustered index)列最佳选择
1) 那些包含在范围查询语句当中的列;如 between 关键字中的列、或 > (大于比较) 或 < (小于比较) 中的数据列。2) order关键字中的数据列
3) 聚集函数中的数据列
4) 表中值唯一的列
聚集索引(clustered index)列不宜选择
1)频繁更新的数据列
2)字节数较大的数据列
非聚集索引(nonclustered index)列最佳选择
1)频繁使用在 WHERE 语句中的数据列
2)频繁使用在 JOIN 语句中的数据列
3)频繁使用在 ORDER BY 语句中的数据列
非聚集索引(nonclustered index)列不宜选择低选择性(selectivty)的列。
selectivty = distinct(index columns) / count(*);
即是 某种列组合的不同值 和 整个数据表的总数据行 的比值。选择非聚集索引时,这个值越高越好。
3. PAD_INDEX 和 FILLFACTOR 参数的使用
在前文我已经提到,索引不能建立在经常进行插入、删除、更新的数据表中,这样会导致整个数据的频繁移动,反而会降低性能。但是适当地设置 PAD_INDEX 和 FILLFACTOR 参数对更新的表格有一定的缓解(注意是缓解不是消除)作用。其中FILLFACTOR 就是索引的数据表页面的填充因子。例如FILLFACTOR=50表示索引数据表中有50%填充数据,另外的50%是空的,用来容纳将要插入的新数据行。--使用实例如下
CREATE NONCLUSTERED INDEX NI_TerminationReason_TerminationReason_DepartmentID
ON HumanResources.TerminationReason
(TerminationReason ASC, DepartmentID ASC)
WITH (PAD_INDEX=ON, FILLFACTOR=50)本文的大部分内容来自于对《SQL Server 2008 Transact-SQL Recipes (Apress 2008)》的理解。

















 1742
1742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









