







在ElasticSearch中,倒排索引是一种常用的索引结构,用于快速搜索文档中的某个词汇。
倒排索引的结构于传统的索引结构相反,传统的索引结构是由文档构成的,每个文档包含若干个词汇,然后根据这些词汇建立索引。而倒排索引是由词汇构成的,每个词汇对应了若干个文档,然后根据这些文档建立索引。
对于一个包含多个词汇的文档,倒排索引会将每个词汇作为一个关键字(Term),然后记录下该词汇所在的文档编号(Document ID)及该词汇在文档中的位置(Term Position)。这样。当用户输入一个关键字时,就可以快速地查找到包含该关键字的文档编号,然后通过文档编号再查找对应的文档内容。
倒排索引的优点在于它可以快速定位包含关键字的文档,而且可以支持复杂的搜索操作,如词组搜索,通配符搜索等。同时,由于倒排索引是由词汇构成的,因此在进行数据分析和统计时也非常有用。在ElasticSearch中,倒排索引是一种非常重要的索引结构,它被广泛应用于搜索引擎,日志分析,推荐系统等领域。
扩展:
倒排索引建立过程:
我说的倒排索引建立过程主要有两个步骤,分别是分词,建立倒排索引。
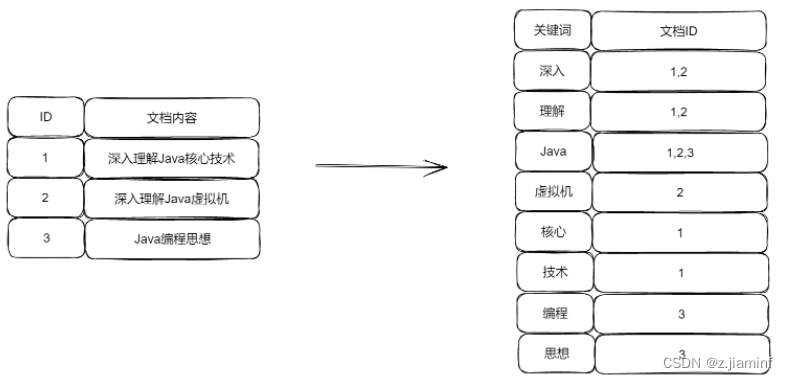
比如我们现在有三份文档内容,分别是
| id | content |
| 1 | 深入理解java核心技术---Hollis |
| 2 | 深入理解java虚拟机 |
| 3 | java编程思想 |
分词:
在倒排索引建立过程中,首先需要将文档中的原始文本分解成一个个词项(Term),ElasticSearch中默认使用标准分词器(Srandard Analyzer)进行分词。
以上三个文本内容,我们经过分词之后,就会包含了“深入”,“理解”,“java”,“核心”,“技术”,“编程”,“思想”,“Hollis”等词
生成倒排索引:
将分开的词,当做索引,与对应的文档ID进行关联,形成倒排表。
| 词条 | 文档ID |
| 深入 | 1,2 |
| 理解 | 1,2 |
| java | 1,2,3 |
| 虚拟机 | 2 |
| 核心 | 1 |
| 技术 | 1 |
| 编程 | 3 |
| 思想 | 3 |
在生产倒排表后,还会对倒排表进行压缩,减少空间占用。常用的压缩算法包含Variable byte Encoding和Simple9 。最后在将压缩后的倒排表存储在磁盘中,以便后续的搜索操作能够快速访问倒排表。
















 4053
4053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











