




一、必备小知识
当需要自己做数据集时,最常用的方法就是从网页爬取图片来制作自己的数据集,今天就来简单的说说如何从百度图片爬取批量图片。当我们在看百度图片时,右键–检查–Elements,点击箭头,再用箭头点击图片时,会显示图片的位置和样式。但是,当我们右键查看网页源码时,出来的却是一大堆JavaScript代码,并没有图片的链接等信息。这是为什么呢?
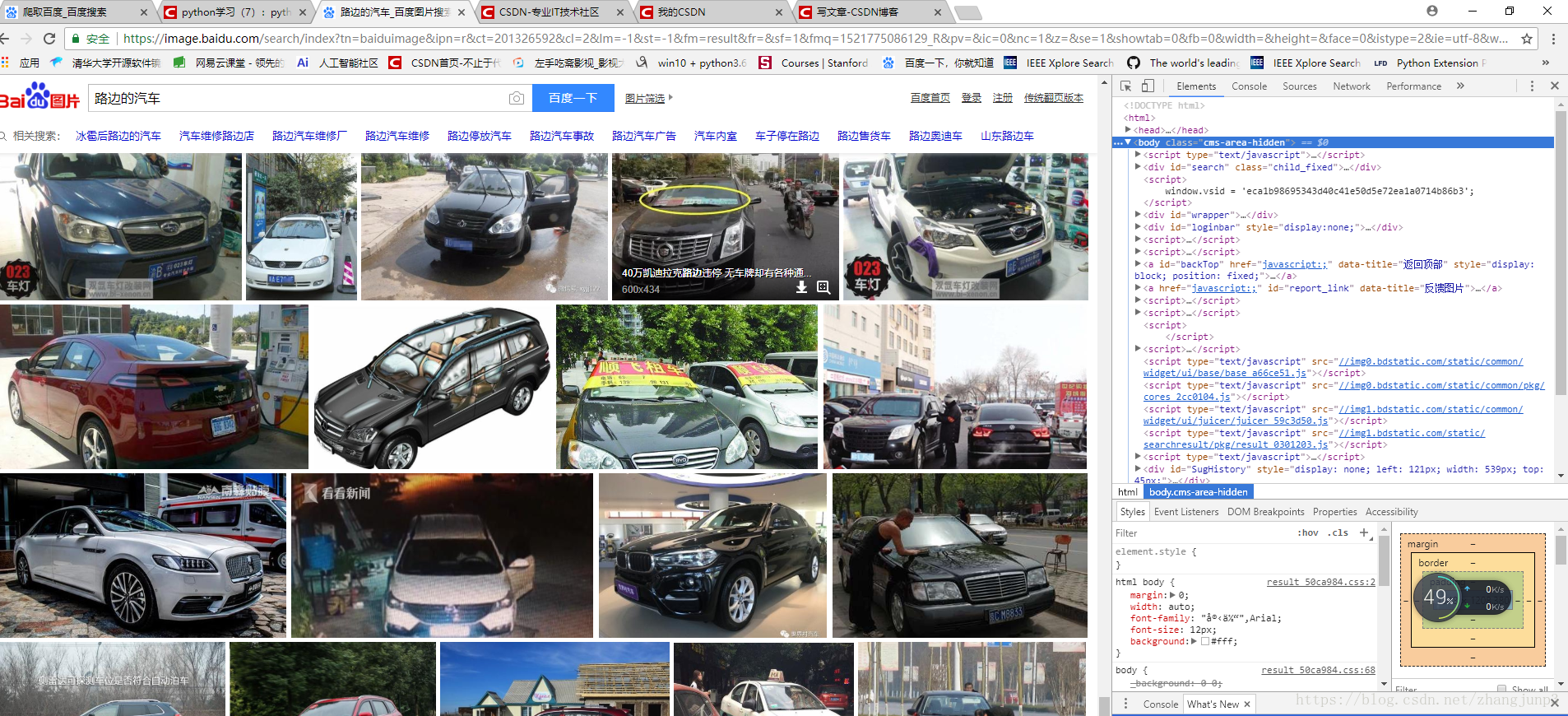
这是因为,百度图片的网页是一个动态页面,它的网页原始数据其实是没有这个图片的,通过运行JavaScript,把这个图片数据把它插入到网页的html标签里面,那这样造成的结果是,我们在开发者工具中虽然能看到这个html标签,但实际上,当我们在看网页的原始数据的时候,其实是没有这个标签的,它只在运行时加载和渲染,那这个时候怎么办呢?怎么把这个图片给下载下来呢?这里面我们就换一个思路,我们就来抓包。
我们点击Network–XHR,然后我们在往下滑动滚动条时,会一直出现一个名为:acjson?tn=resultjson&ipn=…的请求,点击它再点Preview,我们看到这是一条json数据,点开data,我们看到这里面有30条数据,每一条都对应着一张图片。
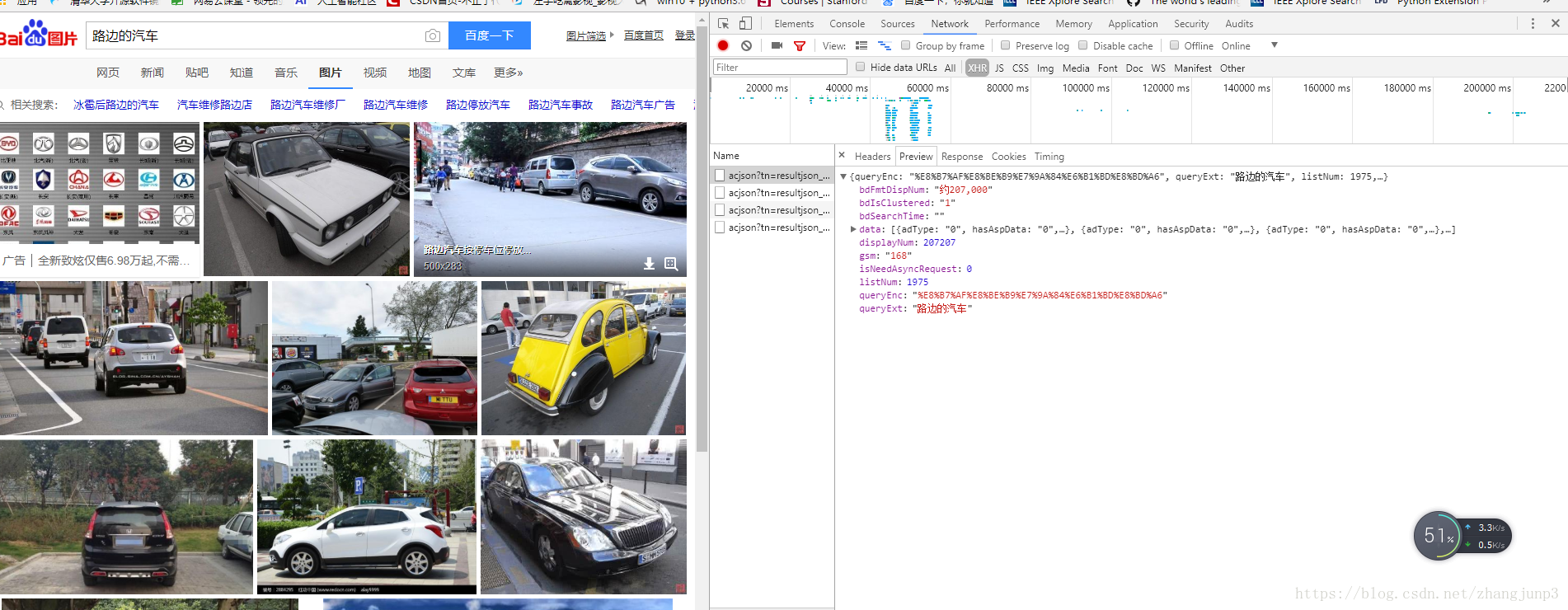
于是我们就清楚了,百度图片一开始只加载30张图片,当我们往下滑动滚动条时,页面会动态加载1条json数据,每条json数据里面包含了30条信息,信息里面又包含了图片的URL,JavaScript会将这些url解析并显示出来。这样,每次滚动到底就又多出30张图片。
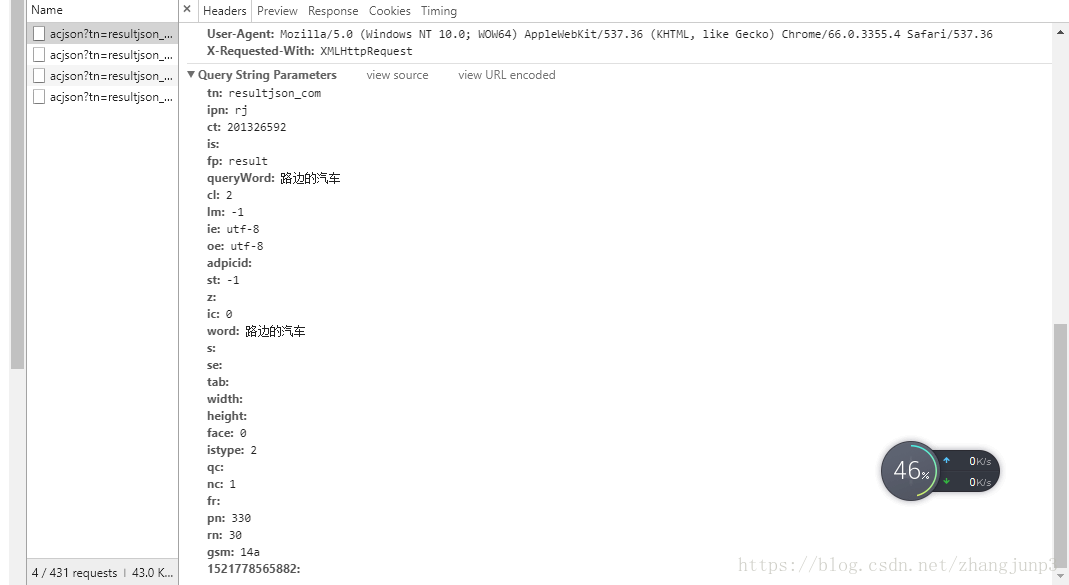
那么,这些一直出现的json数据有什么规律呢?我们点击Headers,然后对比这些json数据的头部信息。通过对比,我们发现headers下的Query String Parameters中的字段大多保持不变,只有pn字段保持以30为步长递增。wonderful!这下找到规律啦!
二、代码实现
在win10,anaconda3.6的平台实现的。
下面直接上代码:
import requests
import os
def getManyPages(keyword,pages):
params=[]
for i in range(30,30*pages+30,30):
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': 0,
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '3c',
'1488942260214': ''
})
url = 'https://image.baidu.com/search/acjson'
urls = []
for i in params:
urls.append(requests.get(url,params=i).json().get('data'))
return urls
def getImg(dataList, localPath):
if not os.path.exists(localPath): # 新建文件夹
os.mkdir(localPath)
x = 0
for list in dataList:
for i in list:
if i.get('thumbURL') != None:
print('正在下载:%s' % i.get('thumbURL'))
ir = requests.get(i.get('thumbURL'))
open(localPath + '%d.jpg' % x, 'wb').write(ir.content)
x += 1
else:
print('图片链接不存在')
if __name__ == '__main__':
dataList = getManyPages('路边的汽车',20) # 参数1:关键字,参数2:要下载的页数
getImg(dataList,'D:\PyCharm Community Edition 2017.2.3\Work\爬取图片\data\\') # 参数2:指定保存的路径这里的关键字和页数可以随意设置。执行完成后,可以在指定的文件夹下查看下载好的照片,如下图所示:
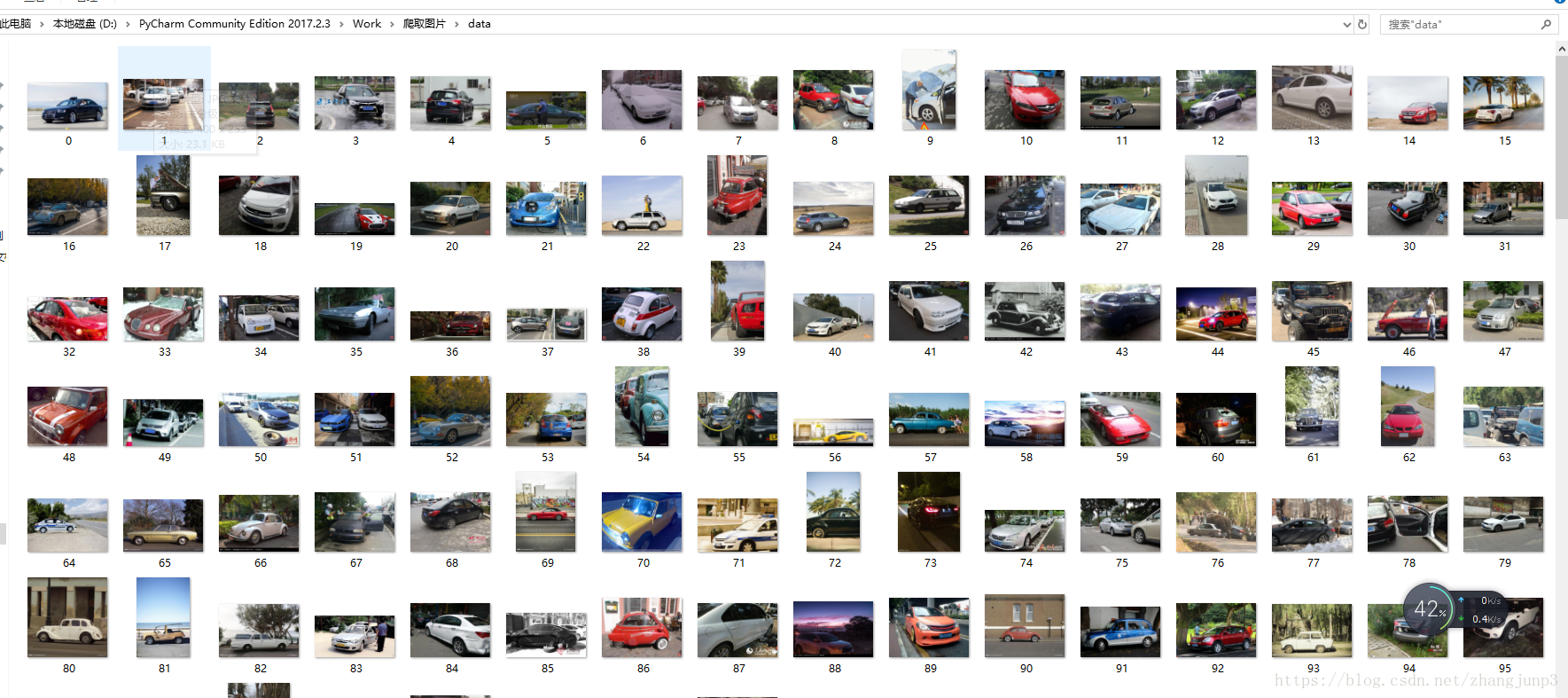
以上就是全部过程,希望能帮到需要爬取图片的朋友们

















 2100
2100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









