







假定Customer类和Order类之间为双向一对多关联关系。
Customer类型包含如下属性:
private Long id;
private String name;
private Set ordres = new HashSet();Order类包含如下属性:
private Long id;
private String orderNumber;
private Customer customer;与域模型对应,在关系数据库中,ORDERS表参照CUSTOMERS表。
假定ORDERS表的CUSTOMER_ID外键允许为null。
一:
类级别和关联级别可选的检索策略及默认的检索策略
图:
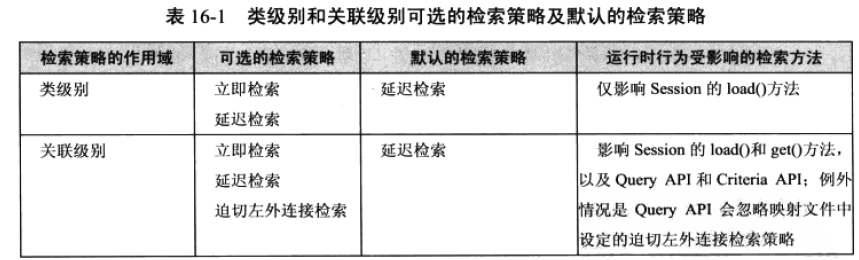
从上图中需要注意:Query API会忽略映射文件中设定的迫切左外连接检索策略。
下图列数这3中检索策略的运行机制
图:

下图是设定检索策略的几个属性。
图:

在映射文件中配置的检索策略是固定的,不可以满足运行时各种应用逻辑的动态需求。
所以Hibernate还允许在应用程序中以编程的方式显示设定检索策略。程序代码中的检索策略会覆盖映射文件中配置的检索策略。
二:类级别的检索策略
类级别可选的检索策略包括立即检索策略和延迟检索,默认后者。
如果程序加载一个持久化对象的目地是为了访问它的属性,可以采用立即检索。
如果程序加载一个持久化对象的目的仅仅是为了获得它的对象的引用,可以采用延迟检索。
下面的代码无须访问Customer对象的属性:
//假定采用延迟检索session.load()方法不会执行查询CUSTOMERS表的select语句
Customer customer = (Customer)session.load (Customer.class,new Long(1));
Order order = new Order ("Tom_Order001");
order.setCustomer(customer);//建立关联关系
session.save(order);//计划执行insert语句,向ORDERS表中插入一条记录。
最后的结果为:
insert
into ORDERS(ID,ORDER_NUMBER,CUSTOMER_ID)values(1,'Tom_Order001',1);需要注意的是,不管Customer.hbm.xhtml文件中<class>元素的lazy属性是true还是false,Session的get()方法以及Query的list()方法在Customer类级别总是使用立即检索策略。
Session的get()方法总是立即到数据库中检索Customer对象,如果数据库中不存在相应的数据,就返回null。
Tips:当通过Session的get()方法加载Customer对象时,假定对与Customer关联的Order对象采用延迟检索,那么hibernate只会立即到数据库中加载Customer对象,而不会立即加载与之相关联的Order对象,即不会立即执行查询ORDERS表的select语句,Query的list()方法类似。
三:一对多和多对多关联的检索策略
1:在映射文件中用<set>元素来配置一对多关联及多对多关联关系。
在Customer.hbm.xml文件中的一下代码用于配置Customer和Order类的一对多的关联关系:
<set name = "orders" inverse = "true">
<key column = "CUSTOMER_ID" />
<one-to-many class = "mypack.Order" />
</set>下图列出了lazy属性和fetch属性取不同值时对Customer类的orders集合采用的检索策略。
图:
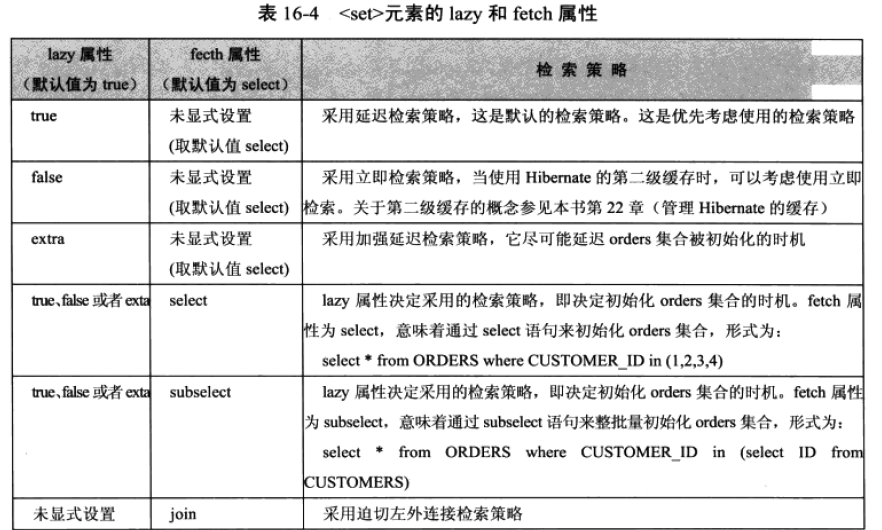
2:TIPS:如果把fetch属性设置为join,那么lazy属性被忽略,此时显式设置lazy属性是无意义的。这里要注意对于Session的get方法和load方法来说是没有意义的,但是对于Query的API来说是有意义的,因为Query API会忽略映射文件中设定的迫切左外连接检索策略。
3:在很多的情况下,应用程序并不需要访问多的一方对象,所以在一对多关联级别中不能随意使用立即检索策略,应该优先考虑使用默认的延迟检索策略。
4:当Customer类的映射文件中的<set>元素lazy为true时。
此时运行Session的get()方法返回的Customer对象的orders属性引用一个没有被初始化的集合代理类的实例,此时orders集合中没有存放任何Order对象。由此可见,
尽管Hibernate会延迟检索与Customer对象关联的Order对象,但不会创建Order代理实例。事实上,这时也无法创建Order代理实例,因为无法知道与Customer关联的所有Order对象的OID。
那么Customer对象的orders属性引用的集合代理类实例被初始化主要包括如下二种情况:
(1):当应用程序第一次访问它,如调用iterator(),size(),isEmpty()或contains()方法时;
(2):通过org.hibernate.Hibernate类的initialize()静态方法初始化它。
5:当Customer类的映射文件中的<set>元素lazy为extra时。
增强的延迟检索策略与一般的延迟检索策略很相似。主要区别在于,增强延迟检索策略能进一步延迟Customer对象的orders集合代理实例初始化的时间。当程序第一次访问orders属性的interator()方法时,会导致orders集合代理类的实例的初始化,而当程序第一次访问orders属性的size(),contains()和isEmpty()方法时,Hibernate不会初始化orders集合代理类实例,仅通过特定的select语句查询必要的信息,而不会检索所有的Order对象。
Customer customer = (Customer)session.get(Customer,class,new Long(1));
//以下语句不会初始化orders集合代理类的实例
//执行select count(*) from ORDERS where CUSTOMER_ID=1;
int size = customer.getOrders().size();
5:批量延迟检索和批量立即检索(使用batch-size)属性
<set>元素有一个batch-size属性,用于为延迟检索策略或立即设定批量检索的数量。
批量检索能减少select语句的数目,提高延迟检索或立即检索的运行性能。
(1):批量延迟检索
看下面的具体的例子:
以下代码用于检索所有的customer对象:
List customerLists = session.createQuery("from Customer as c").list();
Iterator it = customerLists.iterator();
Customer customer1 = (Customer)it.next();
Customer customer2 = (Customer)it.next();
Customer customer3 = (Customer)it.next();
Customer customer4 = (Customer)it.next();
Iterator orderIt1 = customer1.getOrders().iterator();
Iterator orderIt2 = customer2.getOrders().iterator();
Iterator orderIt3 = customer3.getOrders().iterator();
Iterator orderIt4 = customer4.getOrders().iterator();如果对Customer对象的orders集合采用延迟检索策略(<set>元素的lazy属性为true),当Query的list()方法检索Customer对象时,仅立即执行检索Customer对象的select语句:
Select * from CUSTOMERS;
在CUSTOMERS表中共有4条记录,因此,Hibernate将创建4个Customer对象,
他们的orders属性各自引用一个集合代理类的实例。
当访问customer1.getOrders().iterator()方法时,会初始化OID为1的Customer对象的orders集合代理实例,Hibernate执行的select语句为:
Select * from ORDERS where CUSTOMER_ID=1;
当访问customer2.getOrders().iterator()方法时,会初始化OID为2的Customer对象的orders集合代理实例,Hibernate执行的select语句为:
Select * from ORDERS where CUSTOMER_ID=2;
当访问customer3.getOrders().iterator()方法时,会初始化OID为3的Customer对象的orders集合代理实例,Hibernate执行的select语句为:
Select * from ORDERS where CUSTOMER_ID=3;
当访问customer4.getOrders().iterator()方法时,会初始化OID为4的Customer对象的orders集合代理实例,Hibernate执行的select语句为:
Select * from ORDERS where CUSTOMER_ID=4;
有上面的可见,为了初始化4个orders集合代理实例,Hibernate必须执行4条查询ORDERS表的select语句。为了减少select语句的数目,可以采用批量延迟检索,设置<set>元素的batch-size属性:
<set name = “orders” inverse=”true” lazy = “true” batch-size=”3”>
当访问customer1.getOrders().iterator()方法时,此时Session的缓存中共有4个orders集合代理类实例没有被初始化,由于<set>元素的batch-size属性为3,因此会批量初始化3个orders集合代理类的实例,Hibernate执行的select语句为:
Select * from ORDERS where CUSTOMER_ID in (1,2,3);
当访问customer2.getOrders().iterator()方法时,不需要再初始化它的orders集合代理类实例;同样,当访问customer3.getOrders().iterator()方法时,也不需要在初始化它的orders集合代理类实例。
当访问customer4.getOrders().iterator()方法时,会自动再批量初始化3个orders集合代理类实例,假如Session缓存中不足3个orders集合代理类实例,就初始化剩余的所有的orders集合代理类实例。在本例中,会初始化OID为4的Customer对象的orders集合代理类实例,Hibernate执行的select语句为:
Select * from ORDERS where CUSTOMER_ID=4;
由此可见,如果把<set>元素的batch-size属性设为3,那么初始化4个orders集合代理类实例,只需要执行两条查询ORDERS表的select语句。
(2):批量立即检索
对于一下的检索方法:
List customerLists = session.createQuery(“from Customer as c”).list();
如果Customer类的orders集合使用立即检索策略。
<set name=”orders” inverse=”true” lazy=”false”>
那么Query的list()方法会立即执行以下select语句:
Select * from CUSTOMERS;
Select * from ORDERS where CUSTOMER_ID = 1;
Select * from ORDERS where CUSTOMER_ID = 2;
Select * from ORDERS where CUSTOMER_ID = 3;
Select * from ORDERS where CUSTOMER_ID = 4;
为了减少select语句数目,可以设置<set>元素的batch-size属性:
<set name=”orders” inverse=”true” lazy=”false” batch-size=”3”>
此时Query的list()方法立即执行以下的select语句:
Select * from CUSTOMERS;
Select * from ORDERS where CUSTOMER_ID in(1,2,3);
Select * from ORDERS where CUSTOMER_ID = 4;
(3):用带子查询的select语句整批量初始化orders集合(fetch属性 为”subselect”)
<set>元素的fetch属性默认值为select。
对于一下代码:
List customerLists = session.createQuery("from Customer as c").list();
Iterator it = customerLists.iterator();
Customer customer1 = (Customer)it.next();
Customer customer2 = (Customer)it.next();
Customer customer3 = (Customer)it.next();
Customer customer4 = (Customer)it.next();
Iterator orderIt1 = customer1.getOrders().iterator();
当orders集合使用立即检索策略,并且fetch属性取值为subselect时:
<set name=”orders” inverse=”true” lazy=”false” fetch=”subselect”>
程序执行到Query的list()方法时会立即执行以下带子查询的select语句:
Select * from CUSTOMERS;
Select * from ORDERS where CUSTOMER_ID in (select ID from CUSTOMERS)
当orders集合使用默认的延迟检索策略,并且fetch属性取值为subselect时:
<set name=”orders” inverse=”true” lazy=”true” fetch=”subselect”>
程序执行到Iterator orderIt1 = customer1.getOrders().iterator();
时会立即执行以下带子查询的select语句:
Select * from ORDERS where CUSTOMER_ID in (select ID from CUSTOMERS)
由此可见,假定缓存中有n个orders集合代理类实例没有被初始化,那么当fetch属性为”subselect”时,Hibernate能够通过带子查询的select语句,来批量初始化n个orders集合代理类实例。
当fetch属性为“subselect”时,不必设置batch-size属性,如果显示设置了batch-size属性,那么batch-size属性被忽略。而fetch属性为”select”时,可以显示设置batch-size属性。
当fetch属性为”subselect”时,子查询中的select语句为最初查询CUSTOMERS表的select语句。假如查询CUSTOMERS表的select语句为:
Select * from CUSTOMERS where age > 20;
那么初始化orders集合代理类实例的select语句为:
Select * from ORDERS;
Where CUSTOMER_ID IN(Select * from CUSTOMERS where age > 20;
);
Tips:
Customer customer1 = (Customer)session.get(Customer.class, new Long(1));
Customer customer2 = (Customer)session.get(Customer.class, new Long(3));
Iterator orderIt1 = customer1.getOrders().iterator();
Iterator orderIt2 = customer2.getOrders().iterator();
Customer.hbm.xml中的<set>元素配置为:
<set name="orders" inverse="true" lazy= "true" batch-size = "2" fetch="subselect">
此时:不是使用Query的list方法,而是使用session的get()方法,则
会忽略fetch的设置的subselect。
Hibernate: select customer0_.id as id0_0_, customer0_.name as name0_0_ from customers customer0_ where customer0_.id=?
Hibernate: select customer0_.id as id0_0_, customer0_.name as name0_0_ from customers customer0_ where customer0_.id=?
Hibernate: select orders0_.customerid as customerid1_, orders0_.id as id1_, orders0_.id as id1_0_, orders0_.ordernumber as ordernum2_1_0_, orders0_.customerid as customerid1_0_ from orders orders0_ where orders0_.customerid in (?, ?);
6:迫切左外连接检索(fetch属性为join)
如果把Customer.hbm.xml中<set>元素的fetch属性设为join:
<set name=”order” inverse = “true” fetch = “join” >
需要值得注意的是,Query的list()方法会忽略映射文件中配置的迫切左外连接检索策略。
四:多对一和一对一关联的检索策略
在映射文件中,<many-to-on>及<one-to-one>元素分别来设置多对一和一对一的关联关系。
在Order.hbm.xml文件中,以下代码设置Order类和Customer类的多对一关联关系。
<many-to-one name=”customer” column=”CUSTOMER_ID”
Class = “mypack.Customer” />
下图中列数:<many-to-one>元素的lazy属性及fetch属性取不同值是设置的检索策略。
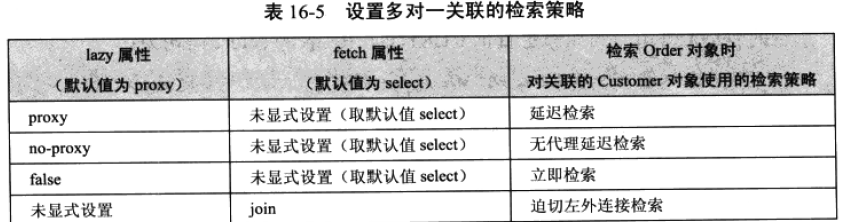
1:tips:对于一对一关联,入轨使用延迟加载策略,必须把<one-to-one>元素的constrained属性设为true:
<one-to-one>元素的constrained属性与<many-to-one>元素的not-null属性在语义上有些相似,它表明Order对象必须和一个Customer对象关联,即Order对象的customer属性不能为空。
2:批量延迟检索和批量立即检索(使用batch-size属性)
如果在关联级别使用了延迟检索或立即检索策略,可以设定批量检索的大小,以帮助提高延迟检索或立即检索的运行性能。
(1):批量延迟检索
代码:
Query query = session.createQuery("from Order as c");
List orderLists = query.list();
Iterator it = orderLists.iterator();
Order order1 = (Order)it.next();
Order order2 = (Order)it.next();
Order order3 = (Order)it.next();
Order order4 = (Order)it.next();
Order order5 = (Order)it.next();
Order order6 = (Order)it.next();
Customer customer1 = order1.getCustomer();
if (customer1 != null) {
System.out.println(customer1.getName());
}
Customer customer2 = order2.getCustomer();
if (customer2 != null) {
System.out.println(customer2.getName());
}
Customer customer3 = order3.getCustomer();
if (customer3 != null) {
System.out.println(customer3.getName());
}
Customer customer4 = order4.getCustomer();
if (customer4 != null) {
System.out.println(customer4.getName());
}
Customer customer5 = order5.getCustomer();
if (customer5 != null) {
System.out.println(customer5.getName());
}假定Order.hbm.xml文件中的<many-to-one>元素的lazy属性为默认值proxy,当Query的list()方法检索Order对象时,仅立即执行检索Order对象的select语句。
以上select语句共检索出6条ORDERS记录,Hibernate将会创建6个Order对象,如果ORDERS记录的CUSTOMER_ID字段不为null,就创建一个Customer代理类实例。Hibernate会保证在Session的缓存中不会出现OID相同的两个Customer代理类实例。
再假定Customer.hbm.xml文件中<set> 元素的lazy属性默认值为true,因此当Hibernate检索Customer对象时,不会立即查询ORDERS表来初始化它的orders集合代理类实例。
运行结果可想而知:为了检索4个Customer对新,Hibernate必须执行4条查询CUSTOMERS表的select语句。为了减少select语句的数目,可以设置Customer.hbm.xml文件中<class>元素的batch-size属性:
<class name=”mypack.Customer” table=”CUSTOMERS” batch-size=”3”>
Batch-size属性用于指定批量初始化Customer代理类实例的数目。当访问customer1.getName()方法时,此时Session的缓存中有4个Customer代理类实例没有被初始化,由于batch-size属性为3,因此Hibernate会批量初始化3个Customer代理类实例。Hibernate执行的select语句为:
Select * from CUSTOMERS where ID in(1,2,3);
Tips:必须根据实际情况确定批量检索数目,合理的批量检索数目应该控制在3-10之间。
(2):批量立即检索
假如Customer.hbm.xml文件中<class>和<set>元素都设置了batch-size属性:
<class name=”mypack.Customer” table=”CUSTOMERS” batch-size=”4”>
<set
name = “orders” inverse = “true” batch-size = “4” lazy = “false”
>
并且Order.hbm.xml文件中<many-to-one>元素的lazy属性的为false:
<many-to-one
Name = “customer” column=”CUSTOMER_ID”
Class = “mypack.Customer”
Lazy = “false”/>
执行以下程序:
List orderLists = session.createQuery(“fromt Order as c”).list();
Hibernate对Order对象采用立即检索,对于Order关联的Customer对象采用批量立即检索,对与Customer关联的Order对象也采用批量立即检索,Hibernate执行3条select语句:
Select * from ORDERS;
Select * from CUSTOMER where ID in(1,2,3,4);
Select * from ORDERS where CUSTOMER_ID in (1,2,3,4);
五:控制迫切左外连接检索的深度
Hibernate.max_fetch_depth属性的合理取值取决于数据库系统的表连接性能以及表的大小。如果数据库表的记录少,并且数据库系统具有良好的表连接性能,可以把hibernate.max_fetch_depth属性值设置得高一些。通常,可以先把他设为4,然后慢慢的加大或者减少这个数值,比较取不同之时引用程序的运行性能,然后选择一个最佳值。
六:在应用程序中显示指定迫切左外连接检索策略
在映射文件中设定的检索策略是固定的,要么为延迟检索,要么为立即检索,要么为外连接检索。但是应用逻辑是多种多样的。有些情况下需要延迟检索,有些情况下需要外连接检索。
Hibernate允许在应用程序中覆盖映射文件中设定的检索策略,由应用程序在运行时决定
检索对象图的深度。
以下Query的list()方法都用于检索OID为1的Customer对象:
(1):第一个Query.list()方法
session.createQuery(“from Customer as c where c.id=1”).list();
(2):第二个Query.list()方法
session.createQuery(“from Customer as c left join fetch c.orders wher c.id = 1”);
假定映射文件对Customer类的orders集合采用延迟检索策略。在执行第一个Query.list()方法时,将使用映射文件配置的检索策略。
在执行第二个Query.list()方法时,在HQL语句中显示指定迫切左外连接检索关联的Order对象,因此会覆盖掉映射文件配置的检索策略,不管在Customer.hbm.xml文件中<set>元素的lazy属性是true还是false。
七:属性级别的检索策略(略)
总结这几种策略的优缺点,以及各自优先考虑的场合。
图:
















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









