







一 前言
分布式系统中,一致性指的是数据在多个副本之间是否能够保持一致性的特性。当一个系统数据在一致性的状态下进行更新后,应该保证系统的数据仍然处于一致性。如何来保证分布式系统中数据的一致性呢?这需要一致性协议来保证。
二 Raft协议简介
Raft协议:是Replication And Fault Tolerant的缩写,即复制和容错协议,是一种强一致性协议,在RAFT中,有三种类型的节点:
# Leader: 处理客户端交互和日志复制操作等,一般只有一个Leader节点
# Follower: 群众节点,类似于选民,需要同步数据
# Candidate: 候选者节点,有可能成为Leader的节点,一般条件是由超过大多数的投票
系统在运行的时候,只有Leader和Follower两种状态,只有在系统不稳定的时候,才有Candidate临时的状态节点,当一个Follower对Leader节点的心跳出现异常,就会转变为Candidate,Candidate就会去竞选Leader,它会主动向其他节点发送竞选投票,如果大多数节点店铺把票投给他,它就会替代原来的Leader,成为新的Leader。
raft协议主要干三件事情:
# 竞选Leader
# 日志复制
# 安全
三 Raft协议工作流程
需求: 我们假设客户端需要设置或者更新数据库的值X
3.1 单节点情况

3.2 多节点的情况

3.3 正常的选举Leader过程



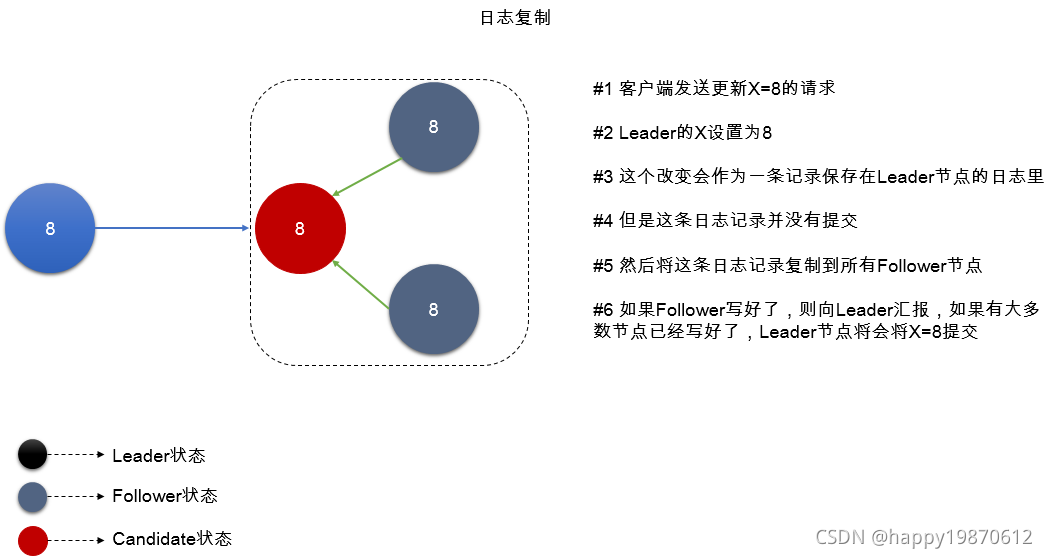
3.4 日志复制过程
# 一旦集群选举出来了Leader,我们需要将所有改变复制到集群中其他节点,它是通过Leader节点的心跳来发送需要添加到其他节点的Entry(改变信息),也就是改变的信息会放在心跳包里发送到其他节点。
# 等待下一次心跳的时候,就发出去
# 各个节点将新的改变信息写入本地,并且响应Leader
# 如果超半数的节点反馈写入成功,则Leader开始进行改变消息的提交
# Leader提交之后,向其他节点发送通知,并且向客户端响应

四 Raft的选举详细流程分析
Raft选举会通过timeout 和 term来控制Leader的选举。
timeout: 是一个150-300ms的随机值,是Follower等待转变为Candidate的时间,即等待再次参加选举的超时时间,可以理解为一个时钟,跑完了一圈后,检查Leader是否存在,如果存在重置timeout;如果没有Leader则,Follower转变为竞选Leader
term: 主要控制选举的轮次,每一个轮次只能有一个Leader,即只要Follower转变为Candidate,就会增加1
4.1 集群初始状态下的选举
每一个节点启动之后,都有一个随机超时变量timeout, 一般随机值为150-300ms

因为timeout是随机的,所以有点超时长有的超时短,如果timeout小的话,即他会先将自己置为Candidate状态,这时候term值会加1.

Candidate节点此时会向给自己投一票,并且向其他Follower发送投票选举请求

如果其余节点在这个轮次内(term)没有挂掉或者还没有为自己或者其他节点投票,然后将会对这个请求进行投票,并且会重置自己的选举超时时间timeout,term也会加1;如果超半数的Follower节点选举该节点, 则该节点成为Leader。

然后Leader节点开始发送Append Entry的消息到Follower节点,而且Leader发送是以一定时间间隔发送的,这个时间间隔不能超过心跳超时时间(heartbeat timeout),也可以理解为Leader发送的Append Entry的消息是随着心跳一起发送的。

Follower节点响应Leader的Append Entry的请求,并将Entry写入本地

Leader收到Follower节点响应,将客户端的系统变量的更新的Entry进行提交;提交完成后通知其他Follower节点,至此集群系统变量处于一致性状态
4.2 如果Leader不可用状态下的选举
如果Leader发生故障,Follower没有接受到Leader的心跳请求,然后最先超时的变成Candidate状态,此时其term会加1

然后Leader停止,集群会重新进行选举,Candidate节点会像其他节点发送选举请求;并且首先会投自己一票,即Vote Count =1

如果Follower还没有开始投票,则Follower节点对Candidate节点的请求进行响应投票
但是之前的Leader节点已经挂掉了,所以不会响应Candidate的请求

Candidate节点的Vote Count =2, 因为满足大多数的原则,即使Leader没有响应,Candidate依然可以被选举为Leader

Leader然后在指定的心跳间隔时间向Follower节点发送Append Entry消息,Follower节点进行Append Entry响应

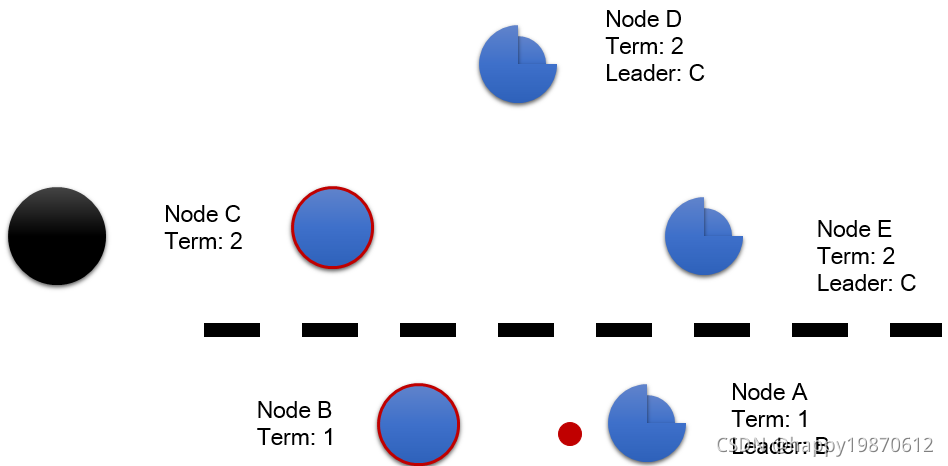
4.3 如果两个节点同时变为Candidate,选举可能会分裂
选举分裂场景如图示:



很明显,此时此刻,Node A 和 Node C的投票数量不满足大多数,即(4/2+1=3),怎么办呢?
这时候的解决办法是,等待所有节点谁最先超时,即等待Follower和Candidate的timeout超时时间, 谁最先超时,谁开始作为Candidate,然后更新Term。 其余的作为Follower,即便之前是Candidate状态,也需要恢复成Follower状态。后面的流程就和前面的一样了,不再赘述。
五 网络分区情况下的处理
如果出现网络分区的时候,raft协议怎么处理呢?
5.1 正常情况下的处理流程
Node B现在是Leader, 所有的客户端请求会先走Leader,然后复制到其他Follower节点


5.2 出现分区的情况
假设C,D和E三台机器在中国,A和 B在美国,然后电缆坏了,那么就分成了2个partition,如图示:

这个时候会出现什么事情呢?
第一: 经过Leader的请求不能提交,因为下面的分区只有2个节点,没有超过半数,所以不能提交

第二:由于上面的分区某个Follower最先超时,没有获取到Leader的心跳请求,则会将自己转变为Candidate;然后term值加1;分区中其他节点发送竞选请求,并且重置自己的timeout。如果竞选成功,则当选为Leader
第三:另外一个客户端写入请求X=10, 上面的分区顺利复制,,Leade进行了提交,达到了一致性

5.3 分区恢复后,各节点是怎么处理
我们知道,分区恢复后明显有2个Leader节点,这肯定是有问题的,raft是怎么处理的呢?
#1 第一轮的主节点(term=1)Node B 向集群中所有节点发送心跳
#2 下面分区的节点发现自己的term和别人的term小,则辞去Leader工作,转变为Follower;并且回滚之前未提交的日志,使用集群中最新的日志















 910
910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











