




 本文深入探讨了列式存储的概念,对比了行式与列式存储的优缺点,并详细介绍了RCFile、ORCFile及Parquet三种列式存储格式的工作原理、内部结构及其优化策略。
本文深入探讨了列式存储的概念,对比了行式与列式存储的优缺点,并详细介绍了RCFile、ORCFile及Parquet三种列式存储格式的工作原理、内部结构及其优化策略。
一 列式存储和行式存储
首先我们看一下一张表的存储格式
1.1 行式存储

1.2 列式存储

1.3列式存储和行式存储的比较
行式存储
优点:
#相关的数据是保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录
#这种存储格式比较方便进行INSERT/UPDATE操作
缺点:
#如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。当然数据比较少,一般没啥问题,如果数据量比较大就比较影响性能
#由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,也就是空间利用率不高
#不是所有的列都适合作为索引
列式存储
优点:
#查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询
#高效的压缩率,不仅节省储存空间也节省计算内存和CPU
#任何列都可以作为索引
缺点:
#INSERT/UPDATE很麻烦或者不方便
#不适合扫描小量的数据
二 RCFile存储格式
要点:
#RCFile保证同一的数据位于同一节点,因此元组重构代价较低(需要将分散的数据重新组织,比如一列数据散落在不同集群,查询的时候,需要将各个节点的数据重新组织;但是如果数据都在一个机器上,那就没有必要重新组织)
#RCFile通过列进行数据压缩,因为同一列都是相同的数据类型,所以压缩比比较好
#RCFile可以跳过不必要的列读取
从以上几点也可以看出它是兼顾了行式和列式存储的部分优点。
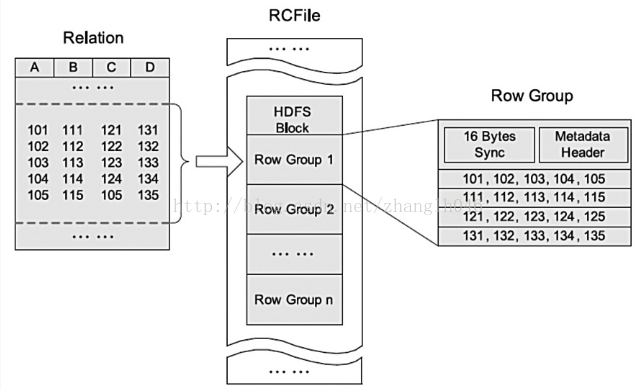
RCFile占用多个block,每一个block以rowgroup(行组)为单位进行组织记录,也就是说存储在一个HDFS Block块中的所有记录被划分为多个行组,对于一张表,所有行组大小相同。一个HDFS块可能有一个或者多个行组
行组包括是三个部分:
Sync:行组头部的同步标志,主要用于隔离HDFS 块中两个连续的行组,大小为16字节。
MetadataHeader:行组的元数据头部,存储行组元数据信息,比如行组中的记录数,每一个列的字节数,列中每一个域的字节数
实际数据:存储顺序是按照域顺序存储。
压缩方式:
RCFile的每一个行组,元数据头部和时真实数据分别被压缩。
对所有元数据头部,RCFile使用RLE(RunLength Encoding )算法压缩
真实数据不会按照真个单元压缩,而是按照一列一列的独立压缩,使用GZip算法,可以获得较好的压缩比。
数据追加
RCFile不支持任意方式的数据追加,因为HDFS仅仅支持文件的追加写到尾部。
RCFile为每一列创建并维护一个ColumnHolder,当记录追加,所有域被分发,每一个域追加其到对应的ColumnHolder,另外RCFile在元数据头部记录每一个域对应的元数据。
RCFile提供两个参数来控制在刷写到磁盘之前,内存中缓存多少个记录。一个参数是记录数的限制,另一个是内存缓存的大小限制。
RCFile首先压缩元数据头部并写到磁盘,然后分别压缩每个columnholder,并将压缩后的columnholder刷写到底层文件系统中的一个行组中。
数据读取和Lazy解压
Map-Reduce,Mapper顺序处理处理每一个块中的行组,当处理一个行组的时候,RCFile无需全部读取行组的全部数据到内存。
他是怎么做的呢?
它仅仅读取元数据头部和给定要查询的列。因此,他可以跳过不必要的列,比如表A(field1,field2,field3,filed4,field5),做查询的时候:
SELECTfield1 FROM A WHERE field5 = 'CN'.
这样的话,对于每一个行组,他只需要读取field1和field5内容。
在元数据头部和需要的列数据加载到内存后,他们需要解压。元数据头部总会解压并在内存中维护直到RCFile处理下一个行组。然而,RCFile不会解压所有加载的列,它使用一种Lazy解压技术:直到RCFile决定列中数据对查询有用才会去解压,由于使用这种WHERE条件,这种解压技术显得很有用,它直接压满足条件的列
二 ORC File存储格式
ORCFile存储格式,就是OptimizedRC File的缩写。意指优化的RCFile存储格式。
2.1 ORC File 和 RC File比较
#每一个任务只输出单个文件,这样可以减少NameNode的负载
#支持各种复杂的数据类型,比如datetime,decimal,以及复杂的struct,
List,map等
#在文件中存储了轻量级的索引数据
#基于数据类型的块模式压缩:比如Integer类型使用RLE(RunLength Encoding)算法,而字符串使用字典编码(DictionaryEncoding)
#使用单独的RecordReader并行读相同的文件
#无需扫描标记就能分割文件
#绑定读写所需要的内存
#元数据存储使用PB,允许添加和删除字段
2.2 ORC File 结构
和RC File是按照行组row group组织记录的类似,ORC File是按照Stripes(条纹)组织记录的,其实意思都差不多。默认情况stripes大小为250MB.
如图示:
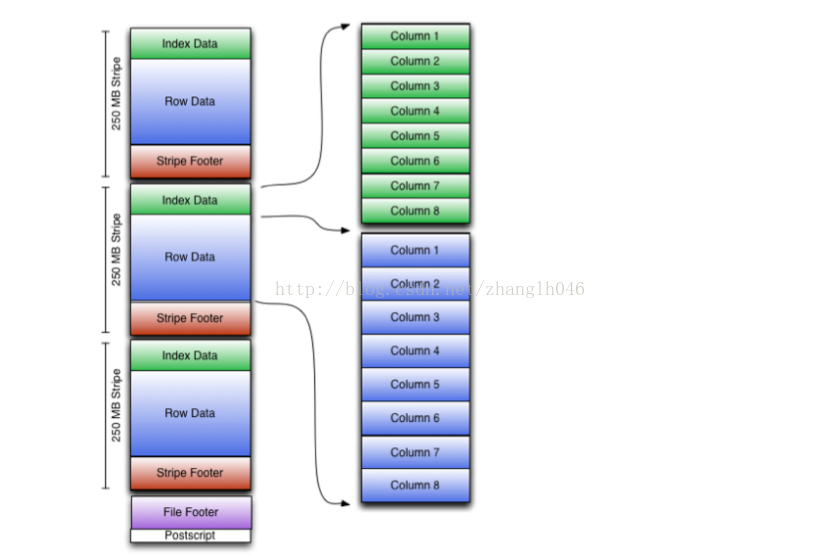
ORC文件存储分为:
2.2.1多个stripes
每一个stripe又包含IndexData(索引数据),RowData(行数据)
StripeFooter,每一个默认是250MB,大的好处是HDFS读的效率更高
IndexData: 保存的是每一列的最大值和最小值,以及每一列所在的行.
row_index包括了改行的偏移量以及改行的长度:
Stream:column 0 section ROW_INDEX start: 3 length 11
Stream:column 1 section ROW_INDEX start: 14 length 28
所以他就可以跳到正确的压缩块位置。
RowData:保存的实际数据
StripeFooter: stream的位置信息
2.2.2一个FileFooter
包含当前文件所有stripes信息,诸如:每一个stripe有多少行,每一列的数据类型,以及列的最大值,最小值等,我们知道stripe的indexdata 也会包含这些数据,所以filefooter的最大值和最小值这些是比较所有的stripe的列得到的结果,如果这个ORC 文件只有一个stripe,那么filefooter的每一列的最大值和最小值就和stripe的估计一样
2.2.3一个PostScript
主要是一些压缩参数和压缩的页脚大小
2.3ORC 查询的优化
我们通过dump工具可以看到orc一些更加详细的信息
hive--orcfiledump /user/hive/warehouse/hadoop.db/orc_emp/000000_0
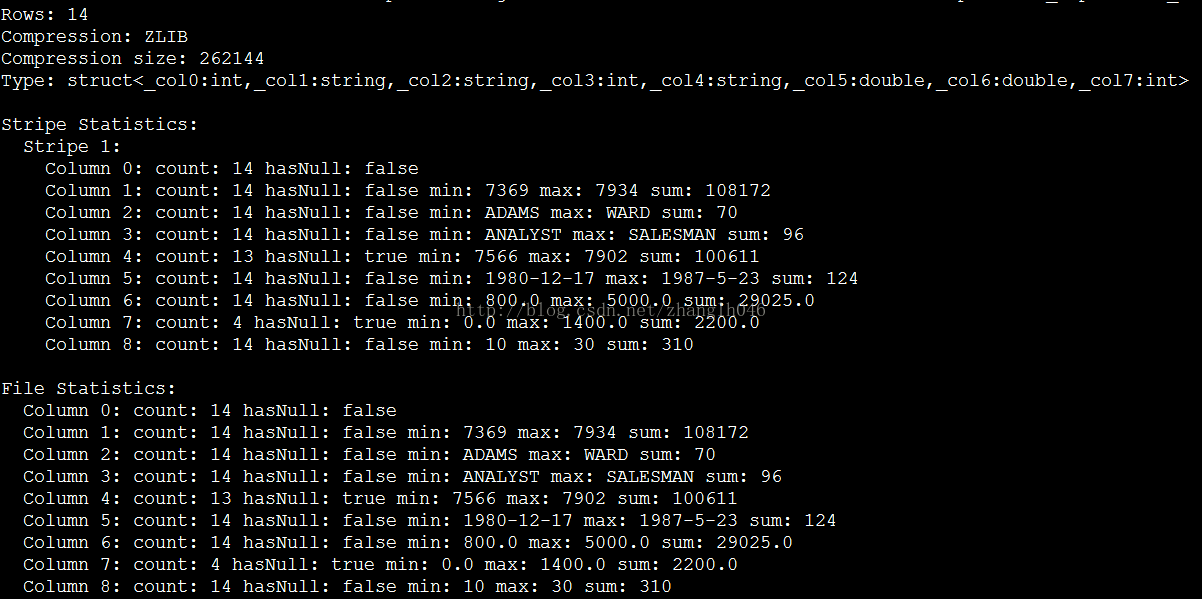

通过上面截图,我们也可以知道一个ORC文件分成多个stripe。文件的元数据统计信息也包括每一个列的最大值和最小值,是否为空等,这就有利于ORC做优化。
如果我们的过滤条件为SELECT *FROM orc_emp WHERE empno = 8888; 这时候Map 任务在读取这个ORC文件时,首先从文件中的统计信息看empno字段min/max值,如果8888不包括在内,那么这个文件就直接跳过了。所以数据写入之前能够先按照id排序,这样同一个empno就可能都在同一个文件或者stripe中,那么在查询的时候,只有负责读取该文件的map任务需要扫描文件,其他map任务如果无需读取,就不用扫描文件,大大节省了map 任务的时间。
排序的手段:
CREATETABLE orc_sort_emp AS SELECT * FROM orc_emp DISTRIBUTE BY empno SORT BY empno;
几乎该语句保证相同的id位于同一个ORC文件中,并且是排序的。
另外,我们这里有了索引,那么Hive是不是默认就使用了呢?
并没有,需要我们把这个参数设置为true:
hive.optimize.index.filter= true
具体有没有使用,可以把jobhistoryserver打开,然后去查看maptask日志。
2.4参数设置
|
Key |
Default |
Notes |
|
orc.compress |
ZLIB |
high level compression (one of NONE, ZLIB, SNAPPY) |
|
orc.compress.size |
262,144 |
number of bytes in each compression chunk |
|
orc.stripe.size |
67,108,864 |
number of bytes in each stripe |
|
orc.row.index.stride |
10,000 |
number of rows between index entries (must be >= 1000) |
|
orc.create.index |
true |
whether to create row indexes |
|
orc.bloom.filter.columns |
"" |
comma separated list of column names for which bloom filter should be created |
|
orc.bloom.filter.fpp |
0.05 |
false positive probability for bloom filter (must >0.0 and <1.0) |
比如:
createtable Addresses (
name string,
street string,
city string,
state string,
zip int
)stored as orc tblproperties ("orc.compress"="NONE");
三 Parquet存储格式
在有些时候,比如数据文件是嵌套的。这个时候,列式存储怎么工作呢?这就引出了Parquet存储。
Parquet是不跟任何数据处理技术绑定在一起的,可以用于多种数据处理框架。
查询引擎:Hive,Imapla,Presto等
计算框架:Map-Reduce,Spark等
数据模型:Avro,Thrift,PB
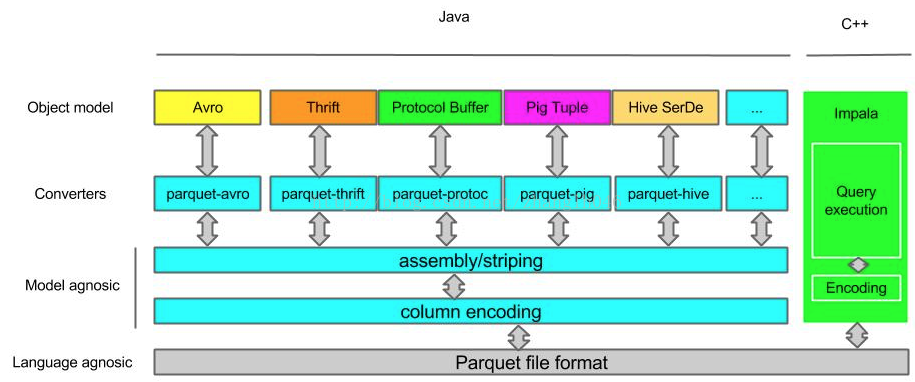
3.1 Parquet如何与这些组件工作呢?
存储格式:定义了parquet内部的数据类型,存储格式
对象模型转换器:完成外部对象模型和parquet内部数据类型的映射
对象模型:Avro,Thrift等都是对象模型
Avro,Thrift, Protocol Buffers都有他们自己的存储格式,但是Parquet并没有使用他们,而是使用了自己定义的存储格式。所以如果使用了Avro等对象模型,这些数据序列化到磁盘最后使用的是parquet的转换器把他们转成parquet自己的格式。
3.3 parquet的文件结构
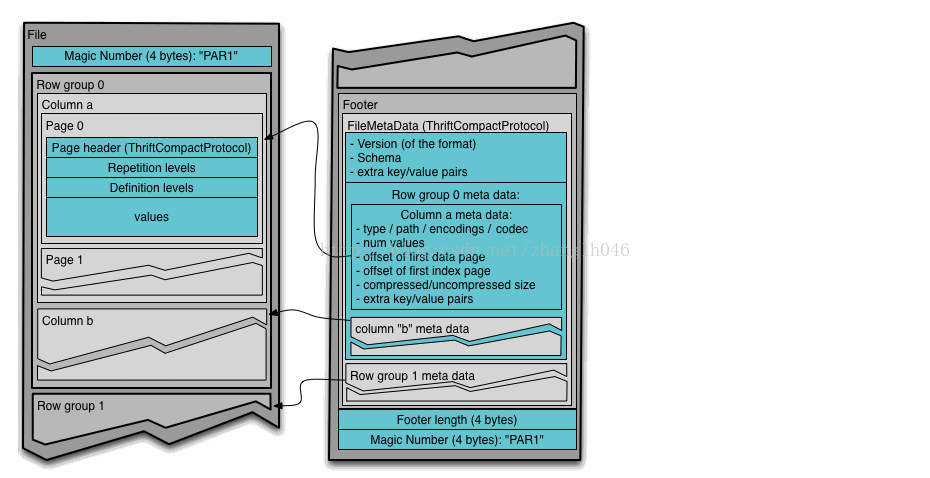
Parquet文件在磁盘所有数据分成多个RowGroup 和 Footer
RowGroup: 真正存储数据区域,每一个RowGroup存储多个Column
Chunk的数据。
ColumnChunk就代表当前RowGroup某一列的数据,因为可能这一列还在其他RowGroup有数据。ColumnChunk可能包含一个Page。
Page是压缩和编码的单元,主要包括PageHeader,RepetitionLevel,
DefinitionLevel和Values.
PageHeader: 包含一些元数据,诸如编码和压缩类型,有多少数据,当前page第一个数据的偏移量,当前Page第一个索引的偏移量,压缩和解压的大小
DefinitionLevel: 当前字段在路径中的深度
RepetitionLevel: 当前字段是否可以重复
Footer:主要当前文件的元数据和一些统计信息
我们主要分析一下什么是DefinitionLevel和RepetitionLevel
3.3.1为什么需要DefinitionLevel和RepetitionLevel
我们知道,这种嵌套的数据类型,可能有很多层,也有很多列,那么在序列化和反序列化的时候,怎么知道数据匹配呢? 意思就是,我怎么知道你这个数据是哪一个节点下面呢?所以才引入了DefinitionLevel和RepetitionLevel。
3.3.2Definition Level
指明该列的路径上有多少个可选的字段被定义了。A.B.C 表示C列这个路径上有三个可选的字段被定义了。也可以理解为definition Level是该路径上有定义的repeated field 和optional field的个数,不包括required field,因为requiredfield是必须有定义的
嵌套数据的特点是有的字段可以为空,比如optional或者repeated。
如果一个字段被定义,那么它的所有父节点都是被定义的。我们从root节点开始遍历,当某一个字段路径上的节点为空或者我们说已经没有子节点的节点的时候,我们就记录下当前的深度作为这个字段的DefinitionLevel. 当一个字段的DefinitionLevel = Max Definition Level,表示这个字段是有数据的。另外,required类型是字段定义的,所以它不需要DefinitionLevel
messageDemo {--- D = 0
optional group field1 { ----D = 1
required group fiel2 {----D = 1(required是不使用DefinitionLevel的)
optional string field3;----D = 2
}
}
}
3.3.3Repetition Level
RepetitionLevel是针对repeated字段的,对于optional和required,是没有啥关系的。意思就是指在哪一个深度上进行重复。
简单的说,就是通过数字让程序明白在路径中什么repeated字段重复了,以此来确定这个字段的位置
举个例子:
我们定一个Author的数据模型:
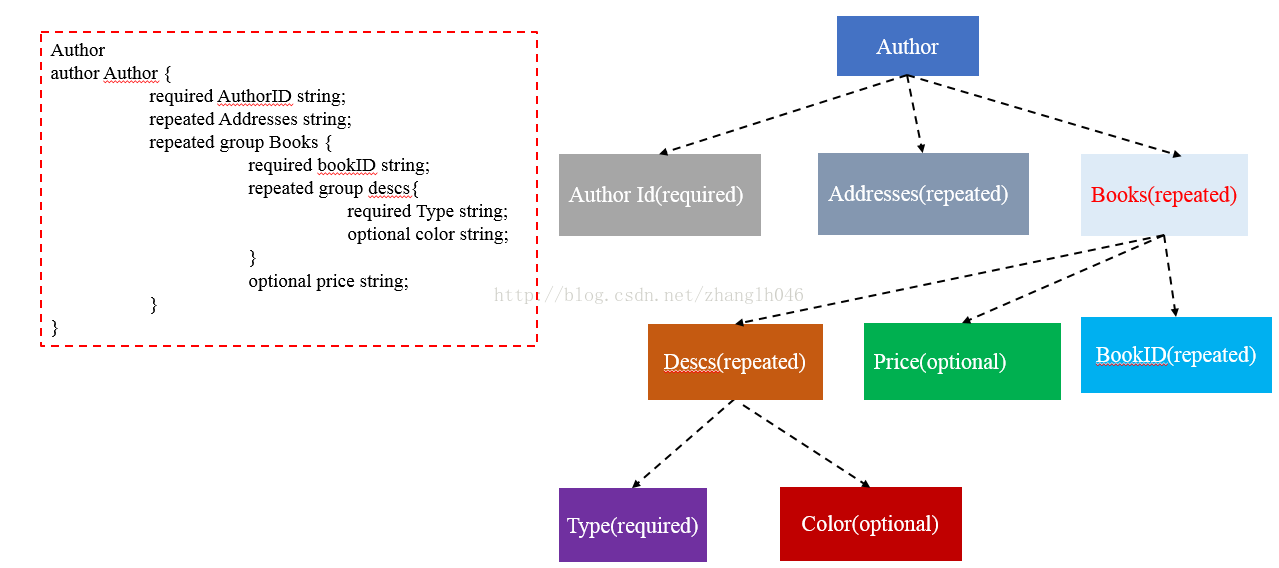

最后生成的数据:

分析:
AuthorID:因为该字段是required,必须定义的,所以,它是没有DefinitionValue,所以都是0
Addresses:因为该字段是repeated,允许0个或多个值,所以DefinitionLevel = 1;第一个Author的第一个Addresses由于之前没有重复,是一个新的record,所以RepetitionLevel = 0; 第二个 Addresses由于在之前已经出现过一次,所以它是重复的,重复深度是1,所以RepetitionLevel = 1;
到第二Author的时候,Address是一个新的record,所以没有重复,RepetitionLevel = 0,DefinitionLevel = 1
Books.BookID:因为该字段是required,必须定义的,所以,他没有DefinitionValue,那么他的DefinitionValue和父父节点的DefinitionValue相同,DefinitionValue = 1. 因为Books是Repeated的,但是Books.BookId只出现一次,所以RepetitionLevel = 0。
到第二个Books.BookId的时候,由于之前已经有过Books,所以现在是重复的,只是Books重复,所以重复深度为1,那么此时RepetitionLevel = 1,DefinitionValue = 1. 到第三个Books.BookkId的时候,同样他也是重复的,重复深度也还是1,所以RepetitionLevel = 1,DefinitionValue = 1.
Books.Price: 由于price是optional,所以在树种有两个DefinitionLevel=2,由于第一次出现Books.Price,所以RepetitionLevel = 0;
第二个Books.Price的时候,DefinitionLevel=2,但是Books已经是重复的,所以现在RepetitionLevel = 1;第三个没有Books.Price,所以DefinitionLevel = 1(和Books的DefinitionLevel一样),RepetitionLevel = 1;
Books.Descs.Type:由于是Required,所以DefinitionLevel没有,和父节点的DefinitionLevel是一样的,故DefinitionLevel = 2;第一次出现Books.Descs.Type,所以RepetitionLevel = 0;第二次出现Books.Descs.Type,由于之前已经存在了Books.Descs,所以现在他重复了,Descs重复深度是2,所以DefinitionLevel = 2, Repetition Level = 2; 下一个Books.Descs.Type由于没有Descs,所以DefinitionLevel = 1,Repetition Level只是Books重复,所以深度为1,值为NULL
;到下一个Books.Descs.Type,由于只是Books重复,所以重复深度为1,DefinitionLevel = 2


















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











