






import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
#编造一些伪数据 unsequeeze方法为将数据变成2维的 torch只会处理2维数据
x = torch.unsqueeze(torch.linspace(-1,1,100),dim=1) #x data (tensor),shape=(100,1)
y = x.pow(2)+0.2*torch.rand(x.size())
x,y=Variable(x),Variable(y) #将xY变成variable数据,torch只能处理这种数据
#定义神经网络主要模块
class Net(torch.nn.Module):
def __init__(self,n_features,n_hidden,n_output): #feature 是特征数,hidden是隐变量数
super(Net,self).__init__()
self.hidden=torch.nn.Linear(n_features,n_hidden)
#上为一个隐藏层的定义,n_featrue指hidden接收的特征数,n——hedeen为输出的隐藏状态数
self.predict=torch.nn.Linear(n_hidden,n_output)
#预测层,n_hidden为接收的隐藏层数量,n=n_output为回归预测就输出一个数量的数
#真正搭建神经网络在这里
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
#定义我们的神经网络
net=Net(1,10,1) #输入特征数为一个,隐藏层有10个神经元,输出数为一个
#看一下自己搭的神经网络直接print就好
print(net)
#优化我们的神经元
optimizer=torch.optim.SGD(net.parameters(),lr=0.2)
#定义一个损失函数
loss_func=torch.nn.MSELoss()
#此处添加一个可视化的过程
plt.ion() #将可视化变成一个实时的展示过程
plt.show()
#开始训练
for t in range(200): #训练100步试试
prediction=net(x)
loss=loss_func(prediction,y)
#先优化
optimizer.zero_grad() #先将所有梯度变为0
loss.backward() #反向传播,为每一个节点计算出梯度
optimizer.step() #用optimizer来优化梯度
if t % 5 ==0:
#plot and show learning progress
plt.cla()
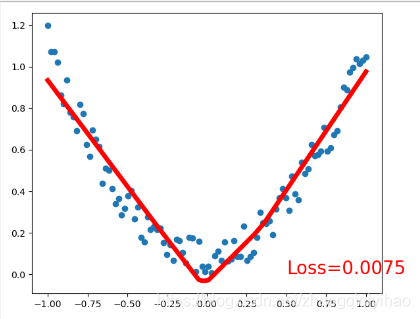
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy(),'r-',lw=5)
plt.text(0.5,0,'Loss=%.4f' % loss.data,fontdict={'size':20,'color':'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
运行结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









