







NAIVESCIMPLEMENTATIONS
下面描述SC的抽象模型,可以更好的帮助我们理解SC的运行规则;
- The Multitasking Uniprocessor
在单个核上,执行多线程;每个线程切换的时候,需要将之前的tread挂起;这样对每个tread看起来,就是SC的;
- The Switch
然后,我们就可以用一堆cores, 一个switch, 一个memory来实现SC,如下图所示;
假设每个核心按其程序顺序一次向交换机呈现内存操作。每个核心都可以使用任何不影响它向交换机呈现内存操作的顺序的优化。
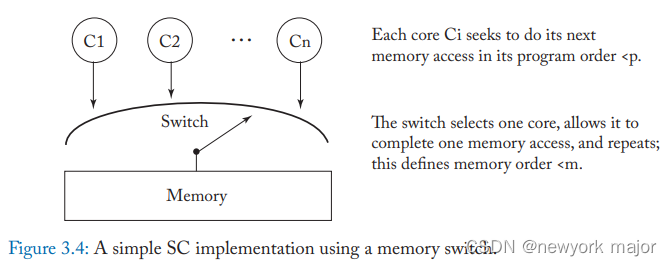
这种做法有一个缺陷,就是当core的数量增加的时候,其性能并未增加,因为都受限于switch的调度;
A BASIC SC IMPLEMENTATION WITH CACHE COHERENCE
coherence可以提高上述SC implemention的并行度,例如,对于非冲突的load/store,带了cohenrence之后,这两个操作可以并行执行;
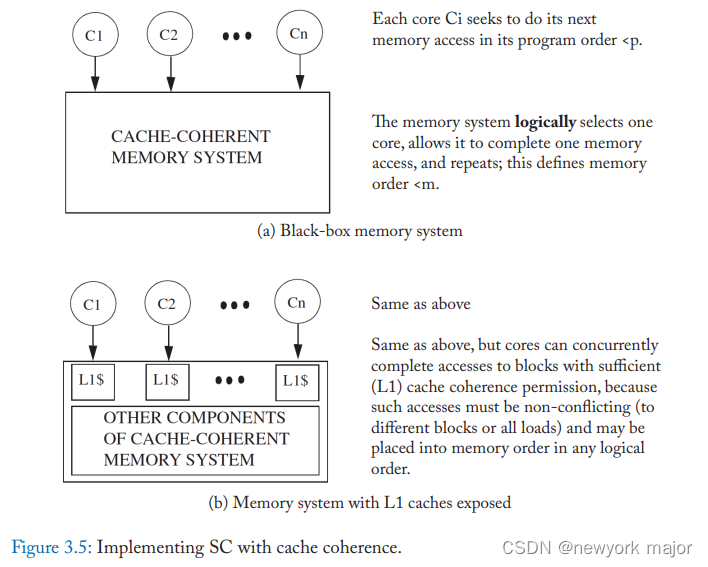
如图所示,交换机和内存被一个缓存 coherent 内存系统取代,表示为一个黑盒子。每个核心按其程序顺序一次向缓存 coherent 内存系统提供内存操作。
在开始对同一核心的下一个请求之前,内存系统会完全满足每个请求;
图 3.5b 稍微“打开”了内存系统黑匣子,显示每个核心都连接到自己的 L1 缓存(稍后我们将讨论多线程)。如果内存系统具有 B 适当的 coherence 权限(load或store状态 M 或 S,store状态 M),则存储系统可以响应对 B 的load或store。此外,内存系统可以并行响应来自不同核心的请求,前提是相应的 L1 缓存具有适当的权限。
例如,图 3.6a 描绘了四个核心各自寻求执行内存操作之前的缓存状态。这四个操作不冲突,可以由各自的 L1 缓存来满足,因此可以同时进行。
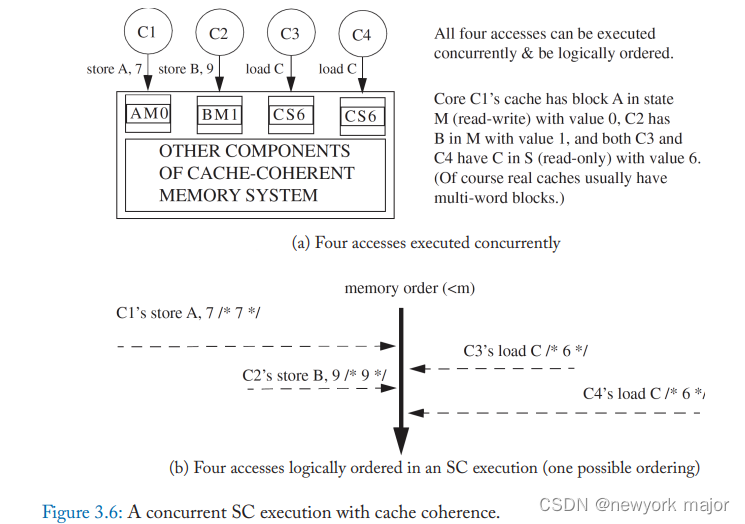
如图 3.6b 所示,我们可以任意排序这些操作以获得合法的 SC 执行模型。更一般地说,L1 缓存可以满足的操作总是可以同时完成,因为 coherence 的 SWMR 不变量确保它们是不冲突的。

使用cache coherence优化SC模型
- 大多数真正的核心实现比我们具有缓存 coherence 的基本 SC 实现更复杂。
- 核心采用预取、推测执行和多线程等功能来提高性能并容忍内存访问延迟。
- 这些特性与内存接口交互,我们现在讨论这些特性如何影响 SC 的实现。值得记住的是,任何功能或优化都是合法的,只要它不会产生违反 SC 的最终结果(load返回的值)
binding prefetch
- 直接将预取值load到core的寄存器中,仿佛是core执行了load一样;现在许多乱序架构,在load指令发射后,并不会暂停执行,而是在不得不需要用到load加载的数据的时候,才stall;
- 这种策略称 之为binding prefetch, 因为在发出预取时,数据的后续使用价值会被绑定;这种方式有如下缺点:
- o 消耗宝贵的处理器寄存器空间;
- o 强制硬件进行预取,即使当前内存系统的负载很重;
- o 预取地址如果是无效地址的话,是否会引起memory fault?
non-binding prefetch
- 相反,大多预取技术都会将预取值直接放入cache,或用于增强cache层次的补充缓冲区(supplemental buffer)中,并同时进行访问。
- 在多核和多处理器系统中,这些cache和buffer还将参与cache一致性协议,因此预取值的存储位置可能在随后访问的期间发生改变;
- 硬件需要保证被访问的值是最新的。这种预取策略被称作非绑定策略(nonbinding)。
- 对于这些方案,预取将只是一种纯粹的性能方案,不影响程序语义。
以block B为例子,其非绑定预取是对 coherent 内存系统的请求,以更改 B 在一个或多个缓存中的 coherence 状态。
最常见的是,软件、核心硬件或缓存硬件请求预取以更改 B 在一级缓存中的状态,以允许通过以下方式加载(例如,B 的状态是 M 或 S)或加载和存储(B 的状态是 M)发出 coherence 请求,例如 GetS 和 GetM。
重要的是,在任何情况下,非绑定预取都不会更改块 B 中的寄存器或数据的状态。非绑定预取的影响仅限于图 3.5a 的“缓存 coherence 内存系统”块内,使得非绑定预取对内存 consistency 模型的影响相当于 no-op 的功能。只要按程序顺序执行加载和存储,以什么顺序获得 coherence 权限都没有关系。
Speculative Cores
- 考虑这样一个core:
- 该core按照PO的顺序执行指令;
- 同时实现了分支预测功能;
- 这样指令在执行的过程中,可能会因为分支预测错误,导致某些指令被丢弃;
- 这种丢弃的load/store, 在整个系统中看来,就像是non-binding-prefetch, 其对SC没有影响;
- 分支预测之后的load可以呈现给 L1 缓存,其中它要么未命中(导致非绑定 GetS 预取)要么命中,然后将值返回到寄存器。
- 如果load被丢弃,核心会丢弃寄存器更新,从而消除加载的任何功能影响——就好像它从未发生过一样。
- 缓存不会撤消非绑定预取,因为这样做不是必需的,并且如果重新执行加载,预取块可以提高性能。
- 对于store,核心可能会提前发出非绑定 GetM 预取,但它不会将存储呈现给缓存,直到store被保证提交。

Dynamically Scheduled Cores
现在的cores, 为了增加性能,不会严格按照PO的顺序来执行指令,而是可能乱序;
对于单核来讲,不管是动态,还是乱序,有数据依赖(RAW/WAW/WAR等)的地方,还是要必须强制满足;
对于多核系统,动态调度会带来一个新的问题:memory consistency speculation;
- 某个core有两个load, L1,L2, L1 <P L2, 但是L2的地址先计算出来,处于dynamic schedule的考虑,L2先执行;
- 但是这个乱序,对于其他的core来讲,不可见,这就会违反SC;
怎么解决这个问题?
需要core检查之前乱序执行的指令,是否可以乱序,或者说,检查prediction是否是正确的;
- 方式1, 执行了L2之后,在commit L2时,检查该地址是否还保留在cache中;
- 如果还在,说明其值在load的execution和commit之间,没有发生过变化;
- 或者再次期间,收到了GETM,说明另一个core正在获取M态,则这个load需要丢弃;
⭘🡽 方式2,每次commit load时,都将specutive load replay一次;
- 如果commit时,该地址的值,已经不等于之前execution的值,则specutive的被丢弃,重新执行;
- 否则,直接从cache里面取,时间也很短;
从上面的例子可以看出,重要的是,SC(或任何其他内存 consistency 模型):
- dictates the order in which loads and stores (appear to) get applied to coherent memory but
- (规定load和store(出现)应用于 coherent 内存的顺序)
- does NOTdictate the order of coherence activity
- (不规定 coherence 活动的顺序。)

Multithreading
- 每个多线程核心都应在逻辑上等效于多个(虚拟)核心,这些核心通过交换机共享每个一级缓存,其中缓存选择下一个为哪个虚拟核心提供服务;
- 此外,每个缓存实际上可以同时服务多个非冲突请求,因为它可以假装它们是按某种顺序服务的。
- 一个挑战是, 在T2 store的操作,对其他core的所有thread可见之前,T1需要确保无法提前读到T2写入的值;
- 因此,虽然线程 T1 可以在线程 T2 以内存顺序插入store后立即发起读取操作(例如,通过将其写入状态 M 的缓存块),但它无法从处理器核心中的shared load-store queue中读取该值。
SC中的原子操作
- 对于多线程的代码,程序员需要对这些线程进行同步,一般此类同步都是一些原子性成对执行的操作;
- 此类同步功能可以概括为RMW类指令,例如,test-and-set, fetch-and-increment, compare-and-swap;
- 此类指令一般对同步,spin-lock等有着至关重要的作用;
- RMW需要原子性的操作,意味着其load/store需要在SC规定的顺序上,连续的出现;
原子操作指令难点不在于设计,而在于其性能的好坏;其设计的基本思想就是让当前核锁定memory system, 阻止其他的cores来进行memory 访问,然后进行read/modify/write的修改;
更好一些的设计,利用只需要保证SC规定的顺序这一约束:
- 如果当前该地址没有在M态,则首先获取该block的M态;
- 然后此时core只需要在cache中进行load/store即可;
- 不需要进行coherence和bus lock的操作;
- 总线来的coherence, 只需要保证当前的RMW完成,然后再响应即可;
- 这样的设计方式,不会有死锁风险,其数据的同步是由memory coherence完成的;

更加优化的做法:允许load和store之间,插入更多的时间
- 刚开始时,某个block是read-only状态,此时执行load;
- 然后,执行响应的coherence操作,去获取read-write状态;
- 等到获取到状态后,进行store操作;
- 需要保证的是,在load和获取到read-write状态这段时间内,该地址没有被其他人操作过(在load-part和store-part之间,该地址没有从cache中evict出去过);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









