







from pyspark import SparkContext, SparkConf
conf = SparkConf().setMaster('local').setAppName('ReadHBase')
sc = SparkContext(conf=conf)
lines = sc.textFile("D://tydic_study\spark//num.txt") # 存放文件的路径
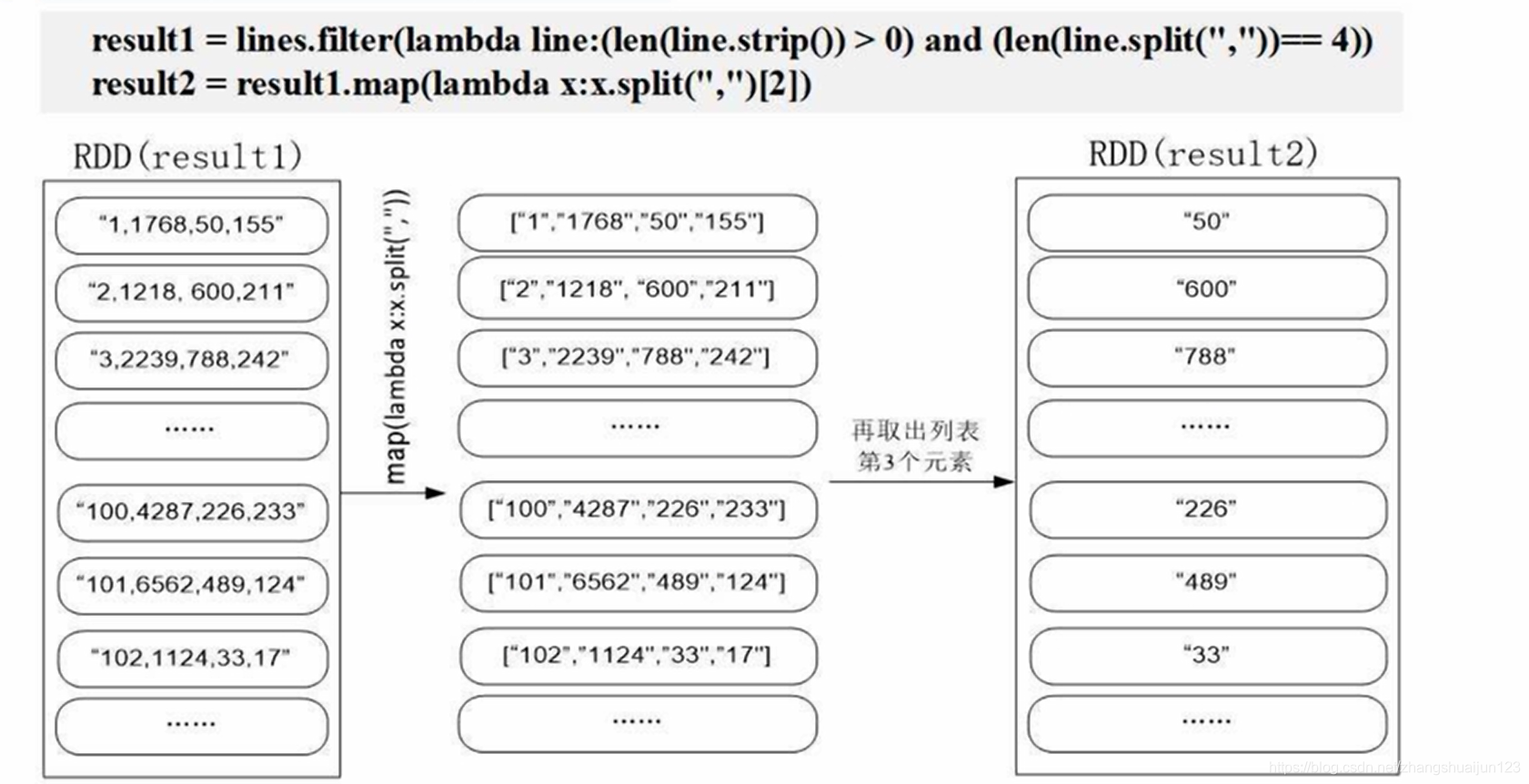
result1 = lines.filter(lambda line: len(lines.strip()) > 0) and len(lines.strip(",") == 4) # 将文件里面的元素生成列表
result2 = result1.map(lambda x: x.split(",")[2]) # 将第三列的元素提取出来
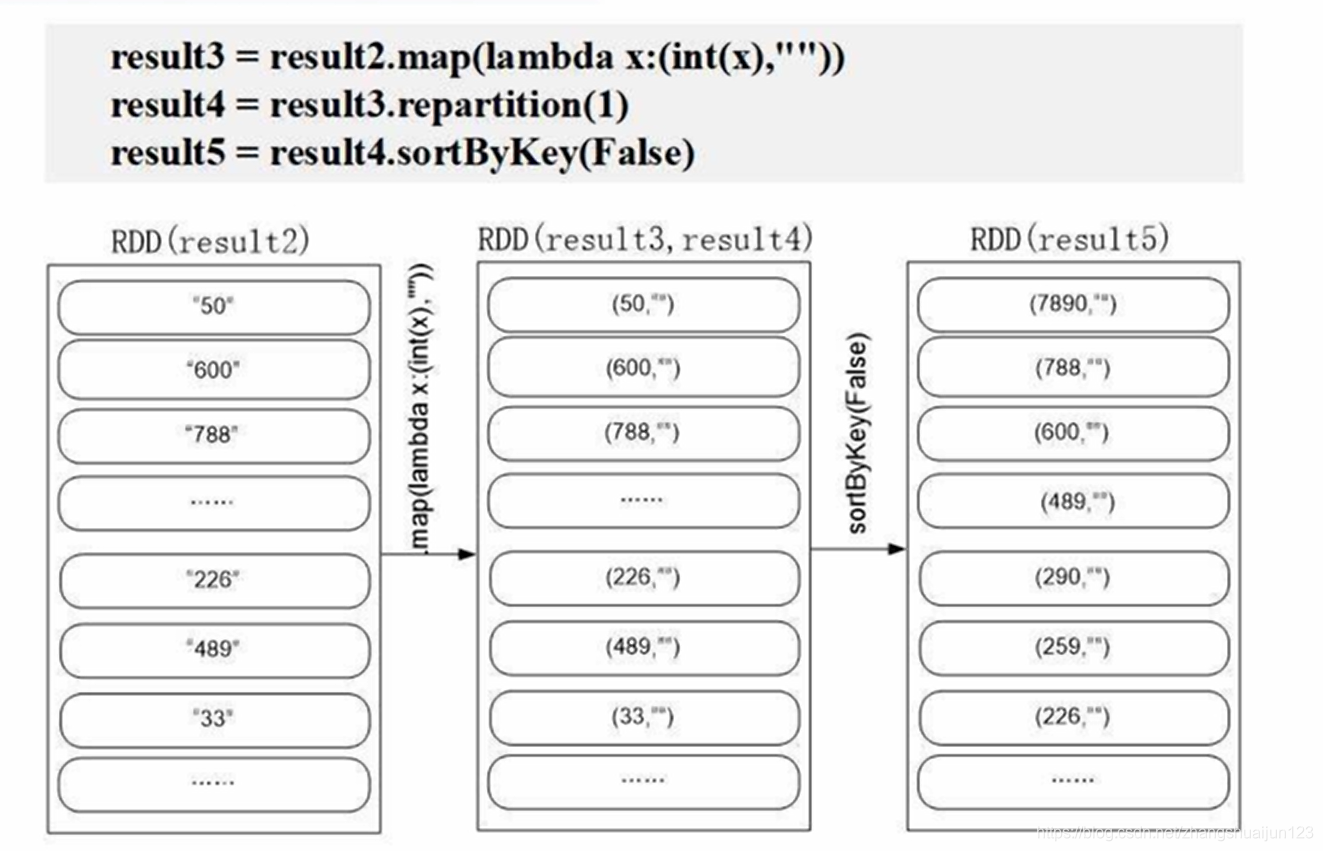
result3 = result2.map(lambda x: (int(x),"")) # 将获得的数据转化为int类型
result4 = result3.repartition(1) # 将整个RDD分成一个分区
result5 = result4.sortByKey(False) # 根据Key进排序
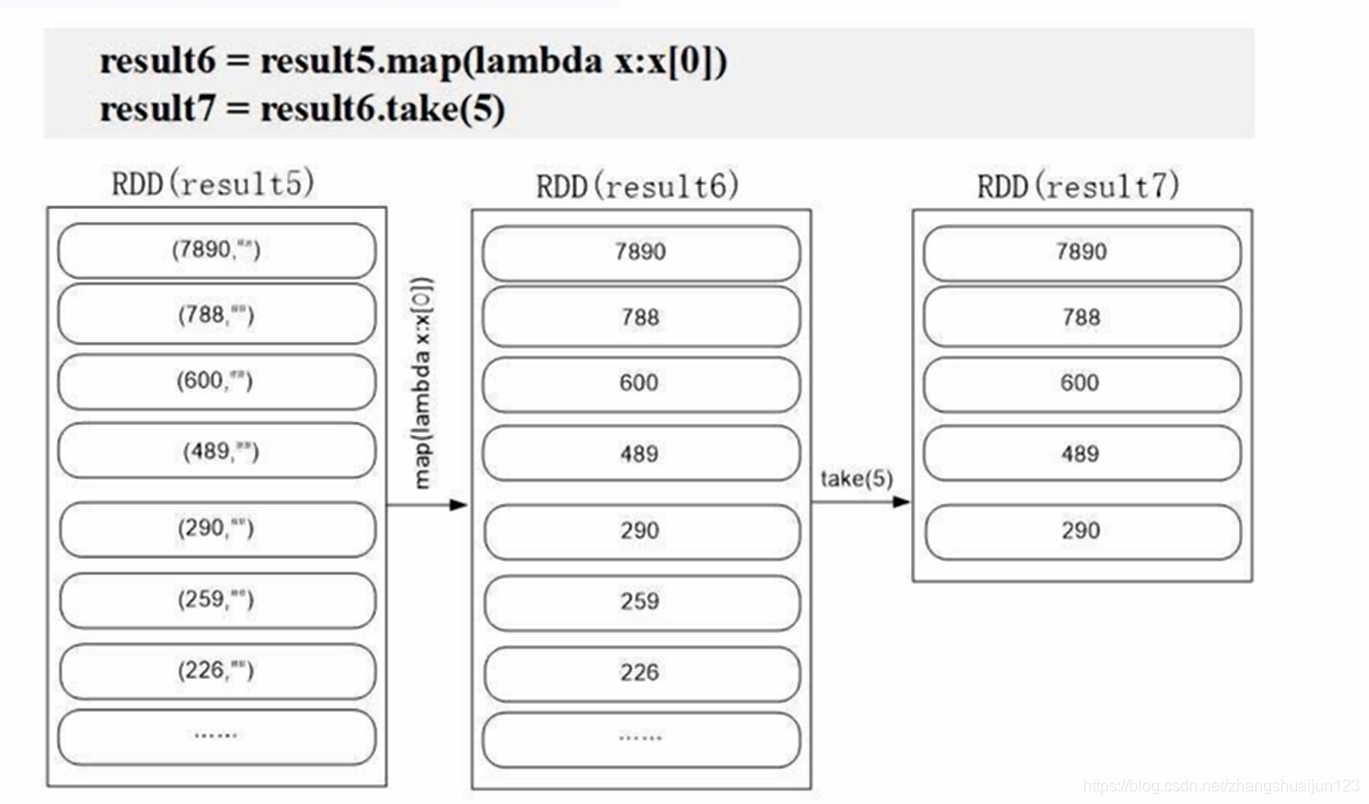
result6 = result5.map(lambda x: x[0])
result7 = result6.take(5)
for a in result7:
print(a)


















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









