







Hadoop分布式集群搭建
0.环境准备
1.vmware 2.centOS
1.虚拟机准备
1.1复制三台虚拟机
1.将三个虚拟机挂在到vmware上 2.选择我已经复制该虚拟机 3.将虚拟机关机
1.2.设置网卡信息
1.更改三个虚拟机的虚拟机名称,以示区分 2.将三个虚拟机的网络适配器改成 NAT模式 3.在网络适配器的高级选项中,点击生成MAC地址,并将生成后的MAC地址记录到文本上,后面会使用到
1.3配置linux的MAC设置
#1.开启虚拟机,进入到网卡设置,修改MAC地址与网卡名称 vim /etc/udev/rules.d/70-persistent-net.rules #2.将三台虚拟机都进行更改,将多余的网卡信息删除掉或注释掉,只保留一个即可。
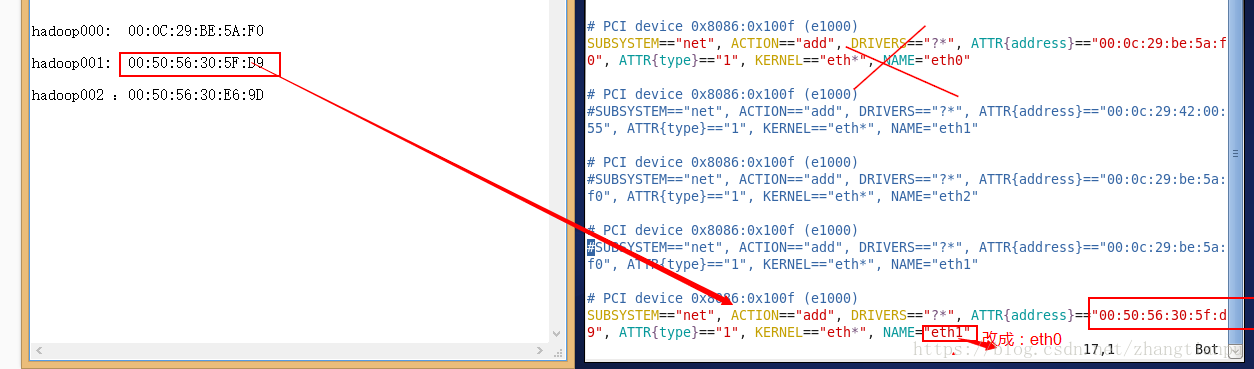
1.4修改linux的网络设置
#1.将动态网络设置成静态网络,三台虚拟机都要设置 vim /etc/sysconfig/network-scripts/ifcfg-eth0 #2.重启三台虚拟机
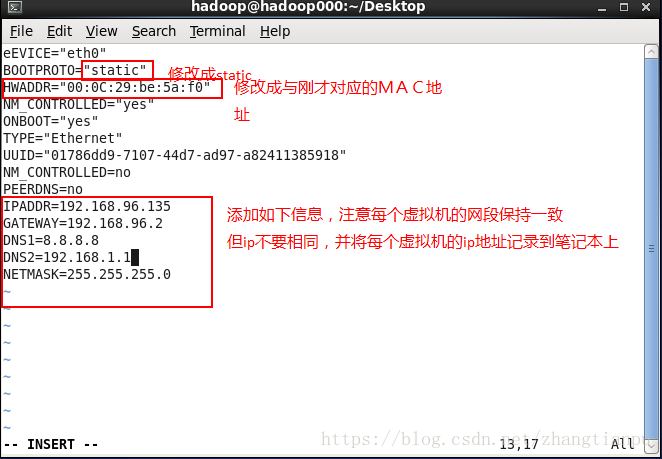
1.5设置linux的主机名
#1 更改主机名 vim /etc/sysconfig/network #2 添加主机名与ip地址的映射关系 vim /etc/hosts 192.168.96.135 hadoop001 192.168.96.134 hadoop000 192.168.96.136 hadoop002 192.168.96.135 localhost
1.6设置VMnet8
注意:
ip地址要与虚拟机中的保持同一个网段,但是不能相同
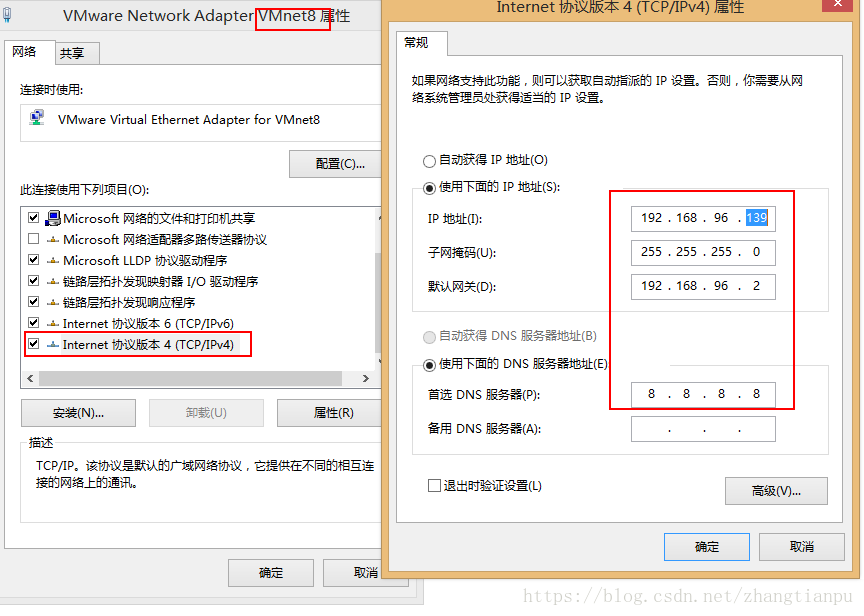
1.7网络验证
# 利用三台虚拟机ping百度 ping www.baidu.com #如果都可以ping通则说明网络配置成功
1.8其他配置
#1.防火墙关闭 #查看防火墙状态,如果是Firewall is not running. 说明防火墙是关闭的 service iptables status #关闭防火墙 service iptables stop #关闭防火墙的自动启动 chkconfig iptables off #查看防火墙是否会随着机器的启动而启动 chkconfig iptables --list #2.时钟同步(这里使用的方法需要虚拟机可以连网) #如果没有安装crontab,需要安装 yum install vixie-cron crontabs crontab -e */1 * * * * /usr/sbin/ntpdate us.pool.ntp.org; #3.关闭selinux vim /etc/selinux/config #设置 SELINUX=disabled
1.8SSH免密码登陆
#1 对三台虚拟机分别生成公钥和私钥,该过程需要键盘输入,直接回车就好 ssh-keygen -t rsa #2 将另外两台虚拟机上的公钥,拷贝到第一台虚拟机上,同时将第一台虚拟机自己的公钥也拷贝到自己身上 #公钥所在的位置在执行完上述命令之后会打印到界面上 Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. cd /home/hadoop/.ssh ssh-copy-id hadoop000(第一台主机名) #3 将第一台主机上的authorized_keys存放公钥的文间,复制到其他两个机器上 scp authorized_keys hadoop001:$PWD
2.集群安装
1.安装jdk(略)
2.安装hadoop
(先在hadoop000上安装如下步骤)
#1 安装hadoop tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C app/ #2 配置环境变量 vim /etc/profile #添加如下内容 export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0 export PATH=$HADOOP_HOME/bin:$PATH #3 修改hadoop-env.sh cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop vim hadoop-env.sh #修改java的JDK路径 export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
<!--4. 修改core-site.xml--> #4 修改core-site.xml <configuration> <property> <name>fs.defaultFS</name> <!--设置hdfs的默认访问路径--> <value>hdfs://hadoop000:8020</value> </property> <!--设置hadoop的存储位置--> <!--如果使用默认的设置将保存在临时文件夹,每次重启都会重置该文件夹--> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/app/tmp</value> </property> </configuration>
#5 设置hdfs-site.xml cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop vim hdfs-site.xml
<!--添加如下内容--> <configuration> <property> <!--设置副本系数,即一个文件会被保存几份,如果不设置默认副本系数为3,在这里可以不用设置--> <name>dfs.replication</name> <value>3</value> </property> <property> <!--设置namenode的存放路径--> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/app/tmp/dfs/name</value> </property> <property> <!--设置datanode的存放路径--> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/app/tmp/dfs/data</value> </property> </configuration>
#6 配置yarn-site.xml cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop vim yarn-site.xml
<!--添加如下内容-->
<property>
<!--默认-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--告诉yarn,resourcemanager跑在那个机器上-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop000</value>
</property>
#7 配置mapred-site.xml cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop vim mapred-site.xml
<!--添加如下内容--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
#8 配置slaves cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop vim slaves
//配置如下,告诉服务器namenode,nodemanage需要跑到哪几个机器上 hadoop000 hadoop001 hadoop002
3.分发配置
#复制hadoop000的配置到hadoop001和hadoop002上 scp -r ~/app hadoop001:~/ scp -r ~/app hadoop002:~/ scp /etc/profile hadoop001:/etc scp /etc/profile hadoop002:/etc
4.对NN做格式化
只要在hadoop000上执行即可
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin hdfs namenode -format
5.启动hadoop集群
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin ./start-all.sh
6.验证
1.进程验证
#在hadoop000上输入jps显示: ResourceManager NameNode SecondaryNameNode DataNode NodeManager
#在hadoop001上输入jsp显示: DataNode NodeManager
#在hadoop002上输入jps显示: NodeManager DataNode
2.网页验证
http://hadoop000:50070
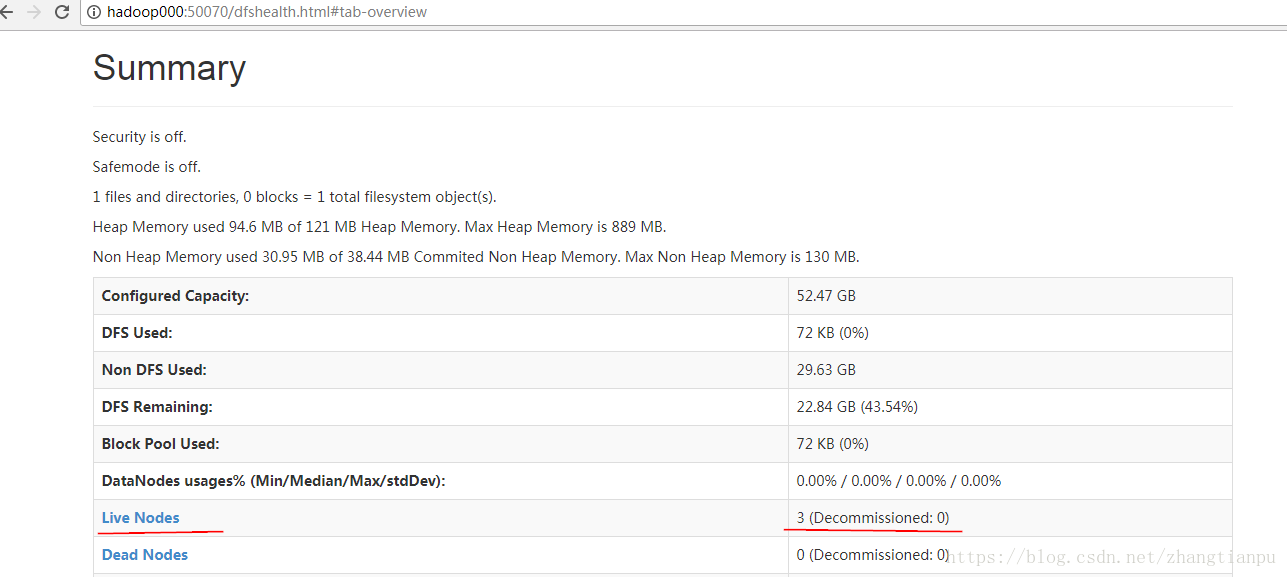
http://hadoop000:8088
7:集群的关闭
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin ./stop-all.sh
问题:
1.
2018-07-26 12:23:41,529 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to hadoop000/192.168.96.134:8020. Exiting. java.io.IOException: All specified directories are failed to load. at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:478) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1394) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1355) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:228) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:829) at java.lang.Thread.run(Thread.java:745) 2018-07-26 12:23:41,532 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool <registering> (Datanode Uuid unassigned) service to hadoop000/192.168.96.134:8020
原因:多次对hadoop集群进行了格式化,所以产生了不同的cluster ID。 解决:删除掉dfs文件,然后再重新进行格式化即可















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









