






 本文介绍了网页采集器的使用,它提供可视化操作,无需编写规则即可批量采集和发布内容,并能自动进行SEO优化,如关键词识别、内链设置、伪原创文章、站点地图生成等。此外,还强调了404页面和正确的关键词、描述设置对SEO的重要性。
本文介绍了网页采集器的使用,它提供可视化操作,无需编写规则即可批量采集和发布内容,并能自动进行SEO优化,如关键词识别、内链设置、伪原创文章、站点地图生成等。此外,还强调了404页面和正确的关键词、描述设置对SEO的重要性。
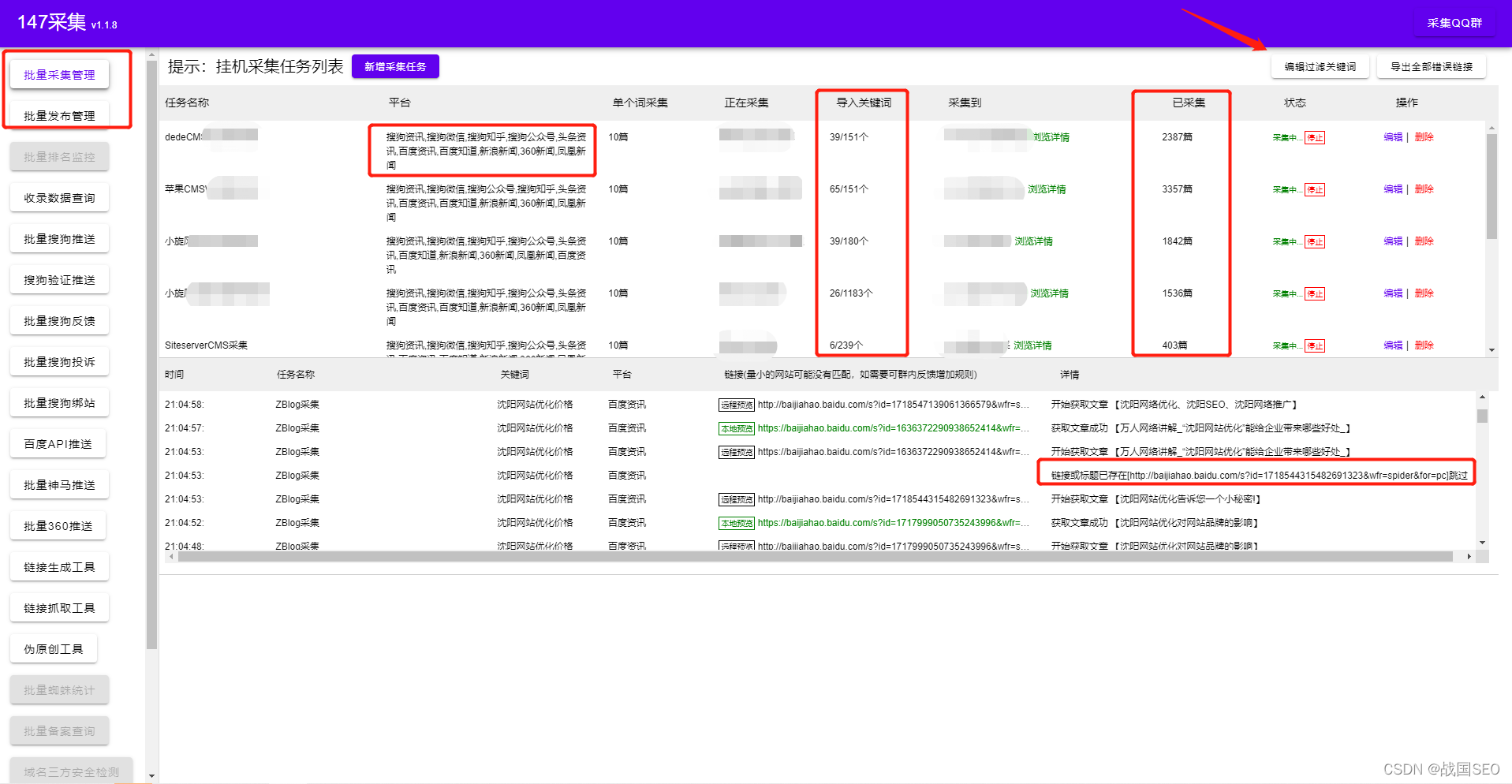
网页采集器,最近很多站长朋友问我指定网站怎么做,市场上的网页采集工具都是基本都是需要写采集规则,这需求站长朋友们会正则表达式,还有html代码基础。这对小白站长来是很难的一件事情。网页采集器可视化批量采集指定网站以及自动伪原创发布并一键自动百度、神马、360、搜狗推送。

网页采集器可以任何网页数据都可以抓取,所见即所得的操作方式,只要点点鼠标就能轻松获得。那么我们如何使用好网页采集器让网站更多的被搜索引擎收录以及获取一个良好的SEO排名。
网页采集器需要我们能够清晰直观的网站定位会带来相对较高的客户群体转化率。我们网站的目的是为了营销。只有专注于某件事,才能更好的展示我们的网站,这样网站内容建设会相当简单。网页采集器基于高度智能的正文识别算法,按关键词采集文章,无需编写采集规则。
网页采集器做网站SEO优化需要网站结构合理。首先要提到的是,网站的结构要清晰,布局要合理,要拒绝冗杂的代码,要拒绝大量的JS脚本和FLASH动画,这些会影响网站的打开速度,栏目设置要清晰可见,让客户浏览清晰明了。
和关键字描述信息。事实上,大多数人都知道关键词和描述对一个网站非常重要,但是有些人会忽略这些信息。关键词和描述相当于一个搜索领导者提交的名片。有了这张名片,人们会更了解你的网站。
网页采集器可以通过长尾关键词做全网关键词文章泛采集,然后结合批量伪原创对网站进行文章定时发布,这样就可以让搜索引擎判定你的网站内容属于原创,更容易获得搜索引擎的青睐。还有一点就是提醒大家,网站收录后,不要轻易更改自己网站的关键词。所以好的关键词和描述也是一个网站的必要条件之一。网页采集器可以对文章标题描述以及内容做相应的SEO优化设置。

网页采集器内置很多网站优化方法。网页采集器支持自动内链,我们都知道网站内链用好了在一个网站中起着非常重要的作用,所以在网站中网页采集器会合理安排内链。网页采集器伪原创文章也会大大提高一个网站SEO优化的指数。好的伪原创文章,对蜘蛛的吸引力是很大的。网页采集器自动全网采集,覆盖六大搜索引擎。自动过滤内容相关度和文章通顺度,只采集相关度高、通顺度高的文章。
当蜘蛛进入网站时,网站地图被视为一个很好的向导,蜘蛛可以很容易地进入网站的每个角落,网页采集器可以自动生成并更新网站的sitemap地图,让蜘蛛第一时间知道你网站有哪些文章链接可以方便蜘蛛进行抓取你的网站的每个链接,sitemap的作用有点类似于网页采集器提供的文章聚合以及TAG标签聚合的功能,一旦蜘蛛来访将不需要蜘蛛花什么功夫获取你网站的链接。
404错误跳转页面也需要设置,网页采集器提供了多种多样的404页面样式,方便蜘蛛抓取哪些不存在的链接,能够得到一个正常的页面,免得蜘蛛认为你的网站是一个死链很多的网站。有很多人不做301重定向文件和404页面。其实这两页还是很重要的,起到提醒的作用。
网页采集器能够自动配图、智能伪原创、定时采集、自动发布,自动提交搜索引擎,支持多种内容管理系统和建站程序。今天关于网页采集器的讲解就到这里下期分享更多SEO相关的知识,希望小编的文章可以在你的SEO建站的道路上可以对你有所帮助。


















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











