









翻阅大大小小的博客,无论中外只要你搜索PreparedStatement这个关键字,得到的大多数结果是在重复执行一条语句多次的情况下PreparedStatement会获得比Statement更好的性能,辟如下文引用的这段文字。
选择PreparedStatement还是Statement取决于你要怎么使用它们. 对于只执行一次的SQL语句选择Statement是最好的. 相反, 如果SQL语句被多次执行选用PreparedStatement是最好的.
PreparedStatement的第一次执行消耗是很高的. 它的性能体现在后面的重复执行.
没错,jdbc中PreparedStatement的初衷除了防止sql注入以外,还有一个功能就是让用户在执行重复的sql能够提高运行效率,对于效率的提升主要体现在了省去了sql语句编译的时间。但是在实际的使用中,还是有不少门道的。
首先来看两段代码,测试的表结构如下:
| id | first | second |
|---|---|---|
| bigint(11) AUTO_INCREMENT | varchar(10) | varchar(10) |
public void preparedGet(int first) {
Connection conn = getConnection();
String sql = "select * from test_table where first = ?";
PreparedStatement pst = null;
ResultSet rs = null;
try {
pst = conn.prepareStatement(sql);
pst.setString(1, "" + first);
int loop = 0;
while(loop < 5) {
rs = pst.executeQuery();
rs.close();
loop++;
}
pst.close();
} catch (SQLException e) {
e.printStackTrace();
}
}public void simpleGet(int first) {
Connection conn = getConnection();
String sql = "select * from test_table where first = '" + first + "'";
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
int loop = 0;
while(loop < 5) {
rs = stmt.executeQuery(sql);
rs.close();
loop++;
}
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}第一段代码使用了PreparedStatement,第二段代码使用的是Statement 每次查询都执行5次,程序结束后查看mysql的日志
Statement的运行日志:

PreparedStatement的运行日志:

可以看到两种方法运行的log是完全一样的,也就是说PreparedStatement并没有开启预编译功能。
下面我们一起深挖一下源代码,看看其中的门道,代码版本为5.1
ConnectionImpl.java中的prepareStatement()函数
boolean canServerPrepare = true;
String nativeSql = getProcessEscapeCodesForPrepStmts() ? nativeSQL(sql) : sql;
if (this.useServerPreparedStmts && getEmulateUnsupportedPstmts()) {
canServerPrepare = canHandleAsServerPreparedStatement(nativeSql);
}
if (this.useServerPreparedStmts && getEmulateUnsupportedPstmts()) {
canServerPrepare = canHandleAsServerPreparedStatement(nativeSql);
}
if (this.useServerPreparedStmts && canServerPrepare) {
if (this.getCachePreparedStatements()) {
......
} else {
try {
//这里使用的是ServerPreparedStatement
pStmt = ServerPreparedStatement.getInstance(getMultiHostSafeProxy(), nativeSql, this.database, resultSetType, resultSetConcurrency);
pStmt.setResultSetType(resultSetType);
pStmt.setResultSetConcurrency(resultSetConcurrency);
} catch (SQLException sqlEx) {
// Punt, if necessary
if (getEmulateUnsupportedPstmts()) {
pStmt = (PreparedStatement) clientPrepareStatement(nativeSql, resultSetType, resultSetConcurrency, false);
} else {
throw sqlEx;
}
}
}
} else {
//这里使用的是clientPrepareStatement
pStmt = (PreparedStatement) clientPrepareStatement(nativeSql, resultSetType, resultSetConcurrency, false);
}可以看到,由于我们的代码中没有设置useServerPreparedStmts,实际上走到的是clientPrepareStatement这个分支,下面我们来对比一下clientPrepareStatement和ServerPreparedStatement的区别
实际上clientPrepareStatement调用的是com.mysql.jdbc.PreparedStatement.getInstance方法,其实本质上就是构造了一个PreparedStatement对象,在该类的构造方法中也并没有任何关于预编译的内容,其execute()方法也就是创建了一个MySQLConnection对象,然后调用executeInternal()方法将对应的sql请求发送到服务端。由此可以看到若想使用jdbc的预编译功能,得开启useServerPreparedStmts参数,下面我们先加上这个参数再次运行上面的测试代码看看效果。在jdbc连接的url中加上useServerPrepStmts=true参数

这时候我们确实看到了sql server进行了预编译,可以发现在ServerPreparedStatement的构造函数中调用了serverPrepare()方法
Buffer prepareResultPacket = mysql.sendCommand(MysqlDefs.COM_PREPARE, sql, null, false, characterEncoding, 0);
//记录下预编译语句的id
this.serverStatementId = prepareResultPacket.readLong();
this.fieldCount = prepareResultPacket.readInt();
this.parameterCount = prepareResultPacket.readInt();
this.parameterBindings = new BindValue[this.parameterCount];该方法中向sql服务器发送了一条PREPARE指令,并记录下了编译好的sql语句所对应的serverStatementId,在之后每次调用set*的方法的时候,会把对应的每个参数的值记录在parameterBindings里。
同时ServerPreparedStatement重写了executeInternal()方法,该方法调用了serverExecute()
Buffer packet = mysql.getSharedSendPacket();
packet.clear();
packet.writeByte((byte) MysqlDefs.COM_EXECUTE);
//将该语句对应的id写入数据包
packet.writeLong(this.serverStatementId);
//将对应的参数写入数据包
for (int i = 0; i < this.parameterCount; i++) {
if (!this.parameterBindings[i].isLongData) {
if (!this.parameterBindings[i].isNull) {
storeBinding(packet, this.parameterBindings[i], mysql);
} else {
nullBitsBuffer[i / 8] |= (1 << (i & 7));
}
}
}
//发送数据包
Buffer resultPacket = mysql.sendCommand(MysqlDefs.COM_EXECUTE, null, packet, false, null, 0);从这段代码我们可以看到,ServerPreparedStatement在记录下serverStatementId后,对于相同SQL模板的操作,每次只是发送serverStatementId和对应的参数,省去了编译sql的过程。
分析到这里,我们已经基本上清楚了PreparedStatement预编译的原理。但是细心的读者会发现serverStatementId是绑定在ServerPreparedStatement对象上的啊,一般情况下,当我们执行完一条sql指令后,会调用close方法回收资源并清除该对象,那岂不是说每次我们执行sql指令时都会创建新的PreparedStatement对象同时编译语句吗?我们来看下面的代码:
public void preparedGet(int first) {
Connection conn = getConnection();
String sql = "select * from test_table where first = ?";
PreparedStatement pst = null;
ResultSet rs = null;
try {
pst = conn.prepareStatement(sql);
pst.setString(1, "" + first);
rs = pst.executeQuery();
rs.close();
pst.close();
} catch (SQLException e) {
e.printStackTrace();
}
}我们将代码中的循环去掉,改为重复运行该方法若干次,再看看日志的输出。
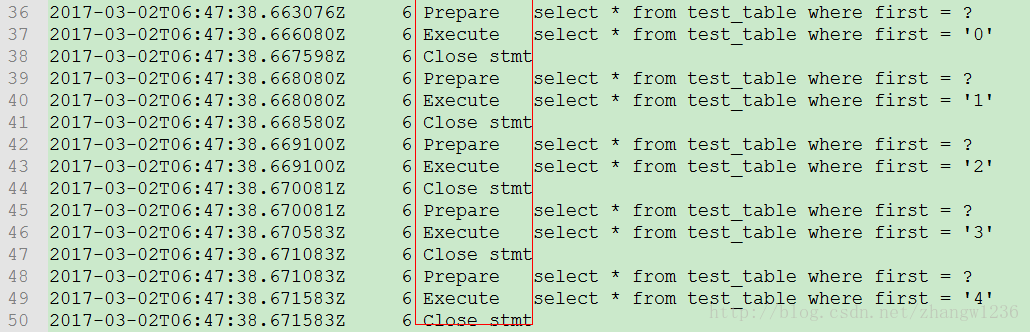
确实如我们之前所猜测,由于serverStatementId是和ServerPreparedStatement对象绑定的,在我们每次new了一个新的PreparedStatement实例后,jdbc都执行了语句编译的操作,这不是我们所期望的。有什么办法可以让jdbc只对相同的语句编译一次呢?
回到之前的分析的ConnectionImpl.java中的prepareStatement()函数,有这么一条语句:
if (this.getCachePreparedStatements())当时跳过了这条语句走了else分支创建了一个新的ServerPreparedStatement对象,下面我们进入到这个if分支中一探究竟:
pStmt = (com.mysql.jdbc.ServerPreparedStatement) this.serverSideStatementCache.remove(sql);serverSideStatementCache的类型是LRUCache,一个LRU的缓存。当找到了相同的sql语句时,直接返回了缓存中的PreparedStatement对象,之后将该对象从缓存中删除。
当执行完sql语句后,调用close方法时:
public void close() throws SQLException {
MySQLConnection locallyScopedConn = this.connection;
if (locallyScopedConn == null) {
return; // already closed
}
synchronized (locallyScopedConn.getConnectionMutex()) {
if (this.isCached && isPoolable() && !this.isClosed) {
clearParameters();
this.isClosed = true;
//将该对象重新存入缓存中
this.connection.recachePreparedStatement(this);
return;
}
realClose(true, true);
}
}为了使getCachePreparedStatements()条件生效,我们添加jdbc的url中添加cachePrepStmts=true参数,再次执行上述测试代码:

到这里,我们才真正地实现了一次编译次次运行。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









