







百度音乐不需要登录也可以下载?听到这个消息是不是很兴奋呢,
接下来我们打开百度音乐,随便打开一首歌,切换到百度播放页面:如图
我这里用的是Firfox 浏览器,打开firebug 先清空所有的请求,如图:

现在我们重新刷新下页面,看到这个.mp3的地址就是百度音乐的地址,我们可以直接复制到迅雷里下载,但是这种做法太初级了吧,如果有很多首歌曲呢,每个都这样复制,岂不是很麻烦啊。,接下来我们继续分析。

这个链接有个特点,就是music/1658513 这个是什么呢? 你猜的没错,这个是每首歌曲的Id ,再看后面的参数xcode 这个是个guid ,经过对比之后,每个都不一样,这个从哪来的啊。。我们继续分析其他请求。。

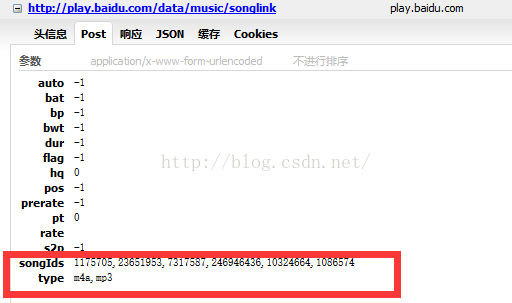
哈哈,还是被我们找到了吧,这个songLink 就是音乐的地址,但是这个请求是怎么来的呢,我们继续往上找,我们看到post请求里的参数,有个songIds 这个就是每首歌的Id,
到了这一步,一切都很顺利,把这个地址复制下来,接下来,该我们的Python出场了。。
这里使用的环境是Python3.4 ,第三方库BeautifulSoup,requests,怎么安装,网上有很多,接下来上代码
新建一个xml文件取名为music.xml 格式如下
<?xml version="1.0" encoding="utf-8"?> <root> <url>http://music.baidu.com/tag/纯净</url> <pageSize>40</pageSize> <savePlay>d:\\纯净\\</savePlay> </root>url 是百度音乐的分类地址 pageSize 是要下载的页数,savePlay 是保存的路径
接下来我们再建一个py文件 主要代码部分:
模拟浏览器请求,防止被屏蔽
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0',
'Referer':'http://play.xml.baidu.com/',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Cache-Control':'max-age=0',
'Connection':'keep-alive'
}
读取xml文件的方法
def getTagText(tag): rc = "" dom=xml.dom.minidom.parse("play.xml") node = dom.getElementsByTagName(tag)[0] for node in node.childNodes: if node.nodeType in ( node.TEXT_NODE, node.CDATA_SECTION_NODE): rc=node.data return rc
解析html方法
def DownHtml(url): try: savePlay=getTagText("savePlay") print("准备开始解析页面:"+url+" 请稍候...") html=requests.get(url,headers=headers,timeout=2000) html.encoding="utf-8" soup=BeautifulSoup(html.text,"html.parser") div_html=soup.find("div",class_="search-song-list song-list song-list-hook") span_html=re.findall('<span class="music-icon-hook" data-musicicon=\'(.*?)\'>',str(div_html)) for v in span_html: data=json.loads(v) play=data["id"],data["songTitle"] queue.append(play) while queue: time.sleep(5) music_tuple=queue.popleft() playUrl=music.replace("$0$",music_tuple[0]) print(music_tuple[1]+".mp3进入下载通道,开始排队等待...\n") resultJson=requests.get(playUrl,headers=headers,timeout=2000) data=resultJson.json() if not data['data']: pass else: v=data["data"]["songList"][0]; print("正在下载, "+v["songName"]+".mp3 ...\n") time.sleep(2) request.urlretrieve(v["songLink"],savePlay+v["songName"]+".mp3") print(v["songName"]+".mp3 下载完成,下载路径:"+savePlay+v["songName"]+".mp3") except: passif __name__=="__main__": start = time.time() pageSize=int(getTagText("pageSize")) pageIndex=25 url=getTagText("url") playurls.append(url) if pageSize>1: for v in range(pageSize): if v>0: purl=url+"?start="+str(pageIndex)+"&size=25&third_type=0" playurls.append(purl) pageIndex+=25 with Pool(4)as p: p.map(DownHtml,playurls) print("本次下载共用时:"+time.time()-start)
 ps :新手自学,如有不足的地方,欢迎指正,环境是在vs2013上开发的,如果其他ide可以单独复制出py,和xml 文件
ps :新手自学,如有不足的地方,欢迎指正,环境是在vs2013上开发的,如果其他ide可以单独复制出py,和xml 文件















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









