







积分拟合法计算圆周率
原理:
主要就是利用tan(π/4)= 1
arctanx=x-x^3/3+x^5/5-x^7/7+...+(-1)^nx^(2n+1)/2n+1 当x=1时
π/4=1-1/3+1/5-1/7+....+(-1)^n1/2n+1)
π=4(1-1/3+1/5-1/7+1/9-1/11+..+(-1)^n1/2n+1)
串行计算圆周率
#include<cstdio>
#include<time.h>
#include<omp.h>
using namespace std;
static long num_steps = 10000000;
double step;
void main()
{
int i;
double x, pi, sum = 0.0;
clock_t t1 = clock();
step = 1.0 / (double)num_steps;
for (i = 0; i < num_steps; i++) {
x = (i + 0.5)*step;
sum = sum + 4.0 / (1.0 + x * x);
}
pi = step * sum;
clock_t t2 = clock();
printf("PI is %.20f\n", pi);
printf("Time: %.2f seconds\n", (float)(t2 - t1) / CLOCKS_PER_SEC);
}openMP并行计算圆周率
#include<cstdio>
#include<time.h>
#include<omp.h>
using namespace std;
static long num_steps = 10000000;
double step;
int main()
{
int i;
double x, pi, sum = 0.0;
clock_t t1 = clock();
step = 1.0 / (double)num_steps;
#pragma omp parallel for num_threads(10) private(x) reduction(+:sum)
for (i = 0; i < num_steps; i++) {
x = (i + 0.5)*step;
sum = sum + 4.0 / (1.0 + x * x);
}
pi = step * sum;
clock_t t2 = clock();
printf("PI is %.20f\n", pi);
printf("Time: %.2f seconds\n", (float)(t2 - t1) / CLOCKS_PER_SEC);
}
CUDA并行计算圆周率
//在vs中新建CUDA程序,而不是普通程序
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h"
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <math.h>
static void HandleError(cudaError_t err,
const char *file,
int line) {
if (err != cudaSuccess) {
printf("%s in %s at line %d\n", cudaGetErrorString(err),
file, line);
exit(EXIT_FAILURE);
}
}
#define HANDLE_ERROR( err ) (HandleError( err, __FILE__, __LINE__ ))
#define HANDLE_NULL( a ) {if (a == NULL) { \
printf( "Host memory failed in %s at line %d\n", \
__FILE__, __LINE__ ); \
exit( EXIT_FAILURE );}}
const int N = 1024 * 1024 * 64; //积分时划分的份数
const int threadsPerBlock = 256; //block中的线程数
const int blocksPerGrid = 64; //grid中的block数
//缺省__host__,表明CPU运行,CPU调用
double function_for_cpu(double x) {
return 4 / (1 + x * x);
}
//__device__修饰,只能被内核函数调用,表明GPU运行,GPU调用
__device__ double function_for_gpu(double x) {
return 4 / (1 + x * x);
}
/**
* __global__修饰,内核函数,表明GPU运行,CPU调用
* 在GPU上使用积分法并行计算PI
* @param a 积分下界
* @param b 积分上界
* @param integral 存储积分结果
* @return
*/
__global__ void trap(double *a, double *b, double *integral) {
/**
* __shared__修饰,声明一个共享内存缓冲区,名字为cache
* 表示数据存放在共享存储器中,每个线程块都有该变量的一个副本;
* 只有在块内的线程可以访问,其它块内的线程不能访问;
*/
__shared__ double cache[threadsPerBlock];
/**
* 该步的目的是计算初始线程索引,其中threadIdx, blockIdx, blockDim都是内置变量
* threadIdx是存储线程信息的结构体,对于线程0来说,threadIdx.x=0;
* blockDim.x表示block在x维度的线程数量,本例中使用的是一维线程块,
* 因此只需用到blockDim.x
* blockIdx.x表示block的索引,对于第一个线程块来说,blockIdx.x=0;
* 对于第二个线程块来说,blockIdx.x=1...
* 在计算tid线程索引时,需要要在threadIdx.x 的基础上加上一个基地址,
* 实际上就是将二维索引空间转换为线性空间
*/
int tid = threadIdx.x + blockIdx.x * blockDim.x;
/**
* 共享内存缓存中的偏移就等于线程索引,线程块索引与该偏移无关,
* 因为每个线程块都拥有该共享内存的私有副本
*/
int cacheIndex = threadIdx.x;
double x, temp = 0;
while (tid < N) {
x = *a + (double)(*b - *a) / N * (tid + 0.5);
temp += function_for_gpu(x);
/**
* 在每个线程计算完当前索引上的任务后,需要对索引进行递增,
* 其中,递增的步长为线程格中正在运行的线程数量,
* 这个数值等于线程块中的线程数量乘以线程格中线程块的数量,
* 即 blockDim.x * gridDim.x
*
* 该方法类似于多CPU或多核CPU的并行,数据迭代的增量不是1,
* 而是CPU的数量;在GPU实现中,一般将并行线程数量看做处理器的数量
*/
tid += blockDim.x * gridDim.x;
}
//设置cache中相应位置上的值
cache[cacheIndex] = temp;
/**
* 对线程块中的线程进行同步,该操作用于确保
* 所有对共享数组cache[]写入操作在读取cache之前完成
*/
__syncthreads();
/**
* 对于归约运算来说,以下代码要求threadsPerBlock必须是2的幂,
* 因为每次合并,要求分成的两部分数组的长度要一致
* 基本思想:
* 每个线程将cache[]中的两个值相加起来,然后将结果保存回cache[]
* 由于每个线程都将两个值合并为一个值,那么在完成这个步骤后,
* 得到的结果数量就是计算开始时数值数量的一半。接着,对这一半
* 进行相同操作,直到cache[]中256个值归约为1个值
*/
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
//将这个值保存到全局内存后,内核函数结束
//这里使用了索引为0的线程将cache[0]写入全局内存
if (cacheIndex == 0)
integral[blockIdx.x] = cache[0];
}
/**
* 在CPU上使用积分法串行计算PI
* @param a 积分下界
* @param b 积分上界
* @param integral 存储积分结果
*/
void trap_by_cpu(double a, double b, double *integral) {
int i;
double x, temp = 0;
for (i = 0; i < N; i++) {
x = a + (double)(b - a) / N * (i + 0.5);
temp += function_for_cpu(x);
}
temp *= (double)(b - a) / N;
*integral = temp;
}
int main(void) {
double integral;
double *partial_integral;
double a, b;
double *dev_partial_integral;
double *dev_a, *dev_b;
cudaEvent_t start, stop;
float tm;
clock_t clockBegin, clockEnd;
float duration;
a = 0;
b = 1;
//使用CPU计算PI的值
clockBegin = clock();
trap_by_cpu(a, b, &integral);
clockEnd = clock();
duration = (float)1000 * (clockEnd - clockBegin) / CLOCKS_PER_SEC;
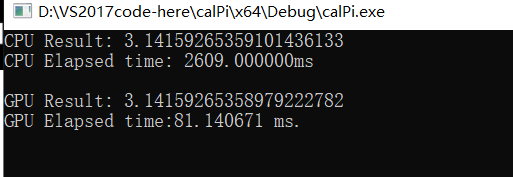
printf("CPU Result: %.20lf\n", integral);
printf("CPU Elapsed time: %.6lfms\n", duration);
getchar();
//使用GPU+CPU计算PI的值
//使用event计算时间
cudaEventCreate(&start); //创建event
cudaEventCreate(&stop); //创建event
cudaEventRecord(start, 0); //记录当前时间
// 申请CPU存储空间
partial_integral = (double*)malloc(blocksPerGrid * sizeof(double));
// 申请GPU存储空间
HANDLE_ERROR(cudaMalloc((void**)&dev_a, sizeof(double)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, sizeof(double)));
HANDLE_ERROR(cudaMalloc((void**)&dev_partial_integral,
blocksPerGrid * sizeof(double)));
//将'a'和'b'复制到GPU
HANDLE_ERROR(cudaMemcpy(dev_a, &a, sizeof(double), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, &b, sizeof(double), cudaMemcpyHostToDevice));
//启动内核函数,启动的线程块的数量是64个,每个线程块的线程数量是256
trap << <blocksPerGrid, threadsPerBlock >> > (dev_a, dev_b, dev_partial_integral);
//将计算结果数组'dev_partial_integral'从GPU复制到CPU
HANDLE_ERROR(cudaMemcpy(partial_integral, dev_partial_integral,
blocksPerGrid * sizeof(double),
cudaMemcpyDeviceToHost));
//在CPU上进行归约操作,得到最终的计算结果
integral = 0;
for (int i = 0; i < blocksPerGrid; i++) {
integral += partial_integral[i];
}
integral *= (double)(b - a) / N;
cudaEventRecord(stop, 0); //记录当前时间
cudaEventSynchronize(stop); //等待stop event完成
cudaEventElapsedTime(&tm, start, stop); //计算时间差(毫秒级)
printf("GPU Result: %.20lf\n", integral);
printf("GPU Elapsed time:%.6f ms.\n", tm);
//释放GPU内存
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_b));
HANDLE_ERROR(cudaFree(dev_partial_integral));
//释放CPU内存
free(partial_integral);
getchar();
}
openMP并行归并排序
#include<iostream>
#include<ctime>
#include<omp.h>
#define N 100000
using namespace std;
int tmp[N];
//并行归并排序
void MergeSortParallel(int p[], int n)
{
int *tmp = (int*)malloc(sizeof(int) * n);
for (int i = 1; i < n; i *= 2)
{
#pragma omp parallel for
for (int left_min = 0; left_min < n - i; left_min += 2 * i)
{
int temp = left_min;
int right_min = temp + i;
int left_max = temp + i;
int right_max = left_max + i;
if (right_max > n)
right_max = n;
//int next = 0;
int next = left_min;
while (temp < left_max && right_min < right_max)
tmp[next++] = p[temp] > p[right_min] ? p[right_min++] : p[temp++];
while (temp < left_max)
p[--right_min] = p[--left_max];
while (next > left_min)
p[--right_min] = tmp[--next];
}
}
free(tmp);
}
int main()
{
clock_t start_time1, end_time1;
srand((int)time(0));
int a[N];
// 生成随机数
for (int i = 0; i < N; i++) {
int num = rand() % N;
a[i] = num;
}
// 计算并行算法时间
start_time1 = clock();
MergeSortParallel(a, N);
end_time1 = clock();
for (int i = 0; i < N; i++) {
printf("%d ", a[i]);
}
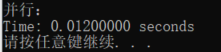
printf("\n并行:\n");
printf("Time: %.8f seconds\n", (float)(end_time1 - start_time1) / CLOCKS_PER_SEC);
system("pause");
return 0;
}















 2171
2171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









