







硬盘结构及原理
计算机可选的数据存储介质有很多,包括:硬盘、U盘、软盘、DVD等,最常见的就是硬盘,硬盘分为机械硬盘和固态硬盘,这里我们主要介绍机械硬盘。那么硬盘是如何存储数据的呢?
硬盘组成
硬盘主要是由圆形磁盘、机械手臂、磁盘读取探头、主轴马达组成,如下:

圆形盘片
一个磁盘可以包含一个或多个盘片,每个盘片包含一个或两个存储面,这就是保存数据的介质,盘片是圆的,首先按照一定的规则将盘片划分出一圈圈磁道(track)。每个磁道又分段切割。每一段就是一个扇区(sector)扇区又称作盘块或数据块。扇区就是磁盘的最小物理单位,各个扇区间保留着一定的间隙。由于磁盘中可能有多个磁盘片(如上图层叠放置),所有盘片的同一个磁道组成磁柱(cylinder)
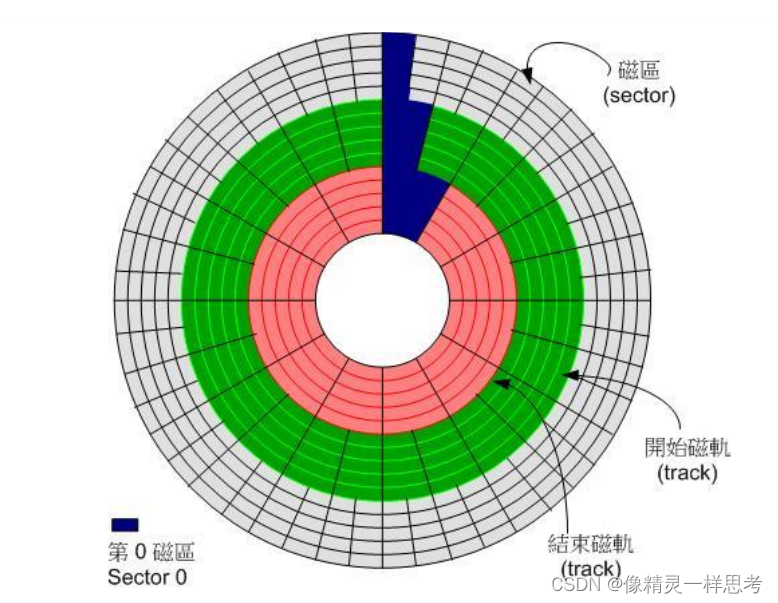
由于盘片中心部位和边缘部位直径不同,因此外圈的磁道占用面积大,为了合理利用空间,一般来说外圈的一个磁道扇区数量更多,磁盘转一圈外圈磁道包含的数据更多,效率也更高。因此硬盘一般默认由外圈开始数据写入依次向内。
早期硬盘的扇区都是设计成512byte,但是因为硬盘的容量越来越大,为了减少数据分割,提高效率现在硬盘的扇区也有所提高。
数据读写
磁盘在机械主轴马达的带动下快速旋转,机械臂上的磁头根据按照旋转的规则寻找特定的扇区,并借助磁头读写其中的数据。也因如此机械硬盘又称作磁盘。
固态硬盘
机械硬盘需要通过旋转来实现磁头的寻址,因此效率较低。如果数据存储比较离散(某个文件可能在最外圈一个扇区,和最内圈一个扇区那)那么会对读写效率有很大的影响。因此现在很多厂商拿闪存做成高容量的存储设备,这种设备不需要旋转寻址,而是通过内存地址直接读写,因此效率很高。缺点是:读写次数有限制,寿命有限。
硬盘分区
如上所述我们了解了硬盘的结构,一个硬盘中最重要的是第一个扇区,这个扇区中保存了磁盘的分区表及开机管理程序。
目前分区表分为两种格式 MBR(MSDOS) 和GPT(GUID partition table)
MBR
早期Linux为了兼容windows磁盘,使用了支持windows 的 MBR(master boot record)的方式来处理开机管理程序和分区表。开机管理程序和分区表保存在磁盘的第一个扇区,通常是512bytes大小
开机管理程序占用446bytes
分区表占用64bytes
由于分区表只占用64bytes,因此只能保存四组记录,代表四个分区,每条记录记录了一个分区的开始和结束磁柱号。(旧的硬盘以磁柱为分区的最小单位,新的磁盘基本采用扇区作为分区最小单位)加入我们有一个硬盘有400个磁柱,分为四个区,示意图如下:
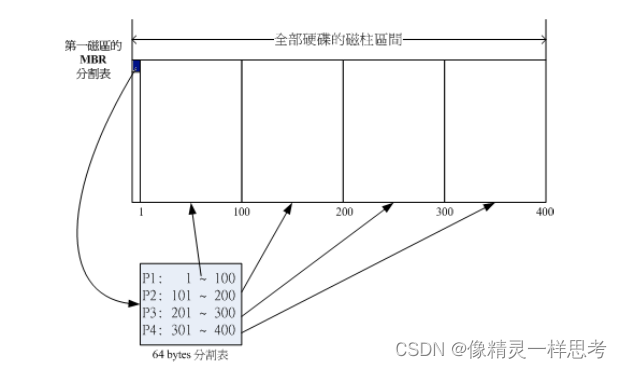
在linux系统中,假设上述磁盘装置文件为 /dev/sda 那么上述四个分区分别是:
P1: /dev/sda1 P2: /dev/sda2 P3: /dev/sda3 P4: /dev/sda4
虽然分区表中最多只能有四套记录但是不代表一个硬盘最多只能有四个分区,确切的说一个硬盘最多只能有四个主分区和扩展分区。但是一个扩展分区可以包含多个逻辑分区。如下我们为硬盘装置创建一个主分区P1和一个扩展分区P2,扩展分区P2又拆分为5个逻辑分区L1~L5
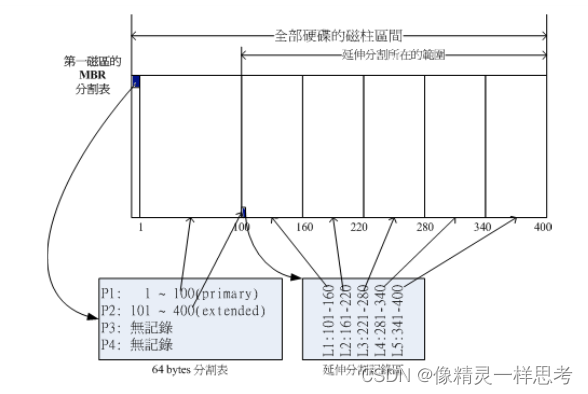
还是假设装置为 /dev/sda 7个分区名称分别如下(逻辑分区从5开始,1-4只能是主分区和扩展分区)
P1:/dev/sda1 P2:/dev/sda2 L1:/dev/sda5 L2:/dev/sda6 L3:/dev/sda7 L4:/dev/sda8 L5:/dev/sda9
扩展分区最多只能有一个,且不能格式化,最终用户能使用的分区就是主分区和逻辑分区。扩展分区的第一个扇区用来保存逻辑分区数据,逻辑分区的数量不通的操作系统限制也不同,Linux 系统中 SATA硬盘已经突破了63 个以上。
MBR每个分区数据只有16Bytes因此记录的信息有限,有以下限制:
- 操作系统无法支持2.2T以上的容量
- MBR第一个扇区很重要,没有备份,若损坏很难救援
- MBR开机管理程序只有446bytes,容纳的程序代码较少
GPT
GPT了按照LBA(Logical Block Address)(预设512bytes) 来划分,和MBR使用一个扇区不同的是,GPT使用前34个LBA来记录分区信息,同时使用最后33个LBA来备份分区信息,这样就解决了MBR容量小和不安全的问题。如下:
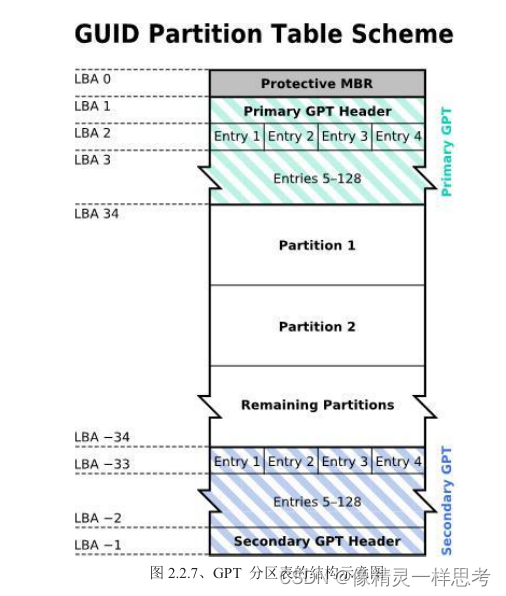
LBA0
又称为MBR兼容区块,与MBR模式相似,446bytes存储了开机管理程序,而在原本分区记录表内保存了一个特殊标志,用来表明磁盘采用的是GPT分区,不能识别GPT分区的管理程序就无法使用磁盘。
LBA1
记录了分区表本身的位置与大小,同时记录了备份用的GPT分区的位置,同时存放了分区表校验码,操作系统可以根据这个来判断GPT是否正确
LBA2-33
从LBA2开始,每个LBA记录四笔分区记录 总共可以记录432=128个分区。因为每个LBA大小为512bytes 所以每个分区表记录占用 512/4=128byte,其中64bytes记录标识符等数据,另外64bytes 记录开始/结束扇区号,分区的大小限制也明显变大。最大容量限制为:2 的64次方512bytes=8ZB (疑问:如果要记录开始和结束的位置那岂不是每个位置只能占用 32bytes 每个bytes是8位 32 bytes =256位 就是2的256次方个数字啊 为什么是2的64次方?)
文件系统
硬盘分区后一般我们会进行格式化,格式化后系统才能使用这个分区,格式化的时候有很多格式可以选择,其实每种格式就代表一种文件系统。格式化成操作系统支持的文件系统就能够被系统使用。
每种操作系统支持的文件系统种类并不相同,例如:win98以前微软操作系统使用的是FAT,win 2000以后支持NTFS。linux正统的文件系统是EXT2,默认情况下windows操作系统是不识别EXT2的。
以下以ext2为例来说明文件存储的原理
文件存储原理
我们知道一个文件元数据(包括文件名、权限、属性等) 和文件内容(文件中实际存储的内容)。
文件系统一般会将文件元数据存放在inode ,将文件内容存放在data block 。将整个文件系统的使用信息(inode 和data block的总数、剩余数量等)保存在super Block
在文件系统格式化时,会将inode和data block 规划好,ext2 在格式化时,将文件系统划分为多个区块分组(避免文件系统容量过大导致效率问题),每个区块分组都有独立的 inode/block/superblock,如下:
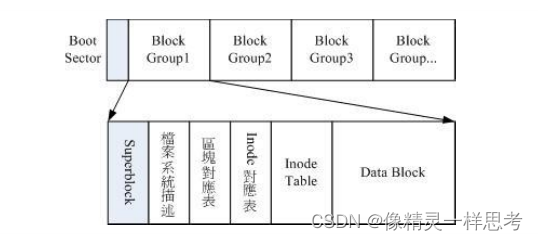
说明如下:
Boot sector
文件系统最前面有一个启动扇区,可以用来安装开机管理程序。有了这个扇区我们就可以将不通的开机程序安装在不通文件系统的最前端,从而实现多重引导。
data block
用来存放文件数据,ext支持的block大小只有1k 2k 4k,格式化后就固定了。且每个block都有编号,方便inode记录。block的大小会影响单个文件的大小,如下

原则上 block的大小和数量在格式化后就不能再改变了,每个block 只能放置一个文件的数据,如果文件容量小于一个block的大小,则剩余空间浪费,如果文件太大可以占用多个block 存储。
如果系统要存储的都是1~2k 的小文件,这个时候 格式化的时候选择 block 的大小为 4k 那么显然会浪费很多空间。
inode table
inode 存储文件的元数据及文件内容存放的 data block 号码具体如下:
- 文件存储模式
- 拥有者和群组
- 文件大小
- 文件修改时间
- 最近读取时间
- 文件特性标识 如:SetUID
- 内容指向(存放文件内容的 data block 的号码)
inode的数量和大小也是在格式化时确定,每个inode固定为128bytes(ext4和xfs可以设定为256 bytes),每个文件只占用一个inode,系统读取文件时先找到inode,并分析权限是否允许,如果允许则找到对应的 data block 读取内容。
这里分析一下ext2 inode 和block 与文件大小的关系。inode 记录一个block 需要消耗4byte,假设每个block 大小为4K,如果要存储一个400M 的文件那么需要10万个block,inode只有128bytes 如何存储这么多block地址呢?
inode记录block 号码的区域分为12个直接区域,一个间接区域,一个双层间接区域和一个三层间接区域,如下:
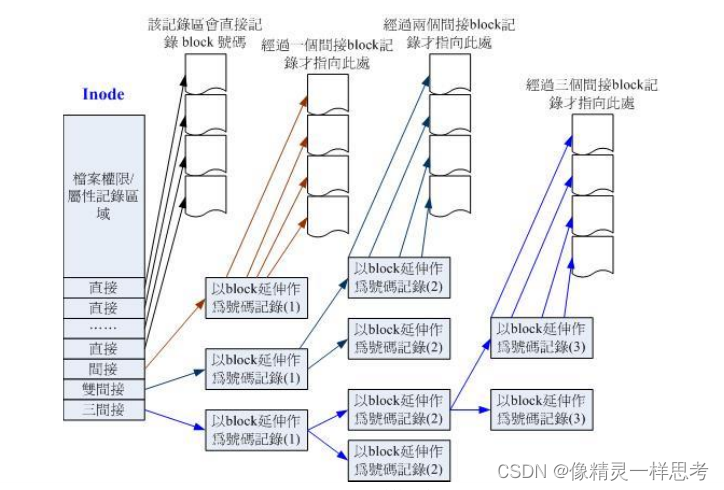
12个直接区域直接保存block号码,一级间接区域就是该区域记录的不是文件内容存储的区块号码 而是记录存储了[文件内容]区块号码的区块的号码。二级间接区域和三级间接区域 类似。这样,假设一个block大小是1k,我们来计算inode支持的文件大小是多少?
12个直接指向:121k =12k
一个间接指向:可以记录一个block 1k, 1k / 4byte =256 个block 因此可以记录 2561k=256k
一个二级间接指向:第一层记录1k 记录256 个block,每个block 又记录 256个 block 因此 :256256 1K
一个三级间接指向:同上256256256* 1K
以上四者相加 等于16Gb 和上文的限制表一致。
super block
记录整个文件系统 的使用情况,包括:
- block 和 inode 的总量 已使用量 剩余量
- block 和inode 的大小
- 文件系统的挂载时间 最近一次写入数据的时间,最近一次磁盘检验时间等
- 挂载状态 valid bit 为0 表示已挂载 为1 表示未挂载
super block 大小一般为1024 bytes,
每个block group 都可能含有super block ,但是以第一个block group 的super block 为准,其他group 中的super block 一般是第一个group 中super block 的备份。
FileSystem Description
描述每个group 的开始和结束 block 号
block bitmap
block bitmap 中记录了哪些block 是空的,方便在新建文件时快速找到可以使用的空间
当一个block 被使用时 在block bitmap 中就会被表示为 使用中,同样当文件删除时会将对应的block bitmap 位置修改为未使用。
inode bitmap
和block bitmap 功能类似,标识哪些inode是空的,随着文件的创建和删除,更改对应inode的使用状态。
dumpe2fs
通过该命令可以查询ext 的superblock信息,后续补充
目录存储原理
当我们新建一个目录时,文件系统会分配一个inode和至少一个data block 给这个目录,inode 记录该目录的元数据(包括:权限、属性等)并记录data块的号码,data 块中记录目录下的文件名及文件占用的inode号码,如下:

可以使用 ls -i 来看目录内文件占用的inode 号码,我们使用ll 查看目录信息时,会看到目录一根都是1024 的倍数,这就是因为data 块一般都是1024/2014/4096的倍数。
如果一个目录下的文件太多,一个 inode无法存储时,会再记录一个block号码来继续记录文件数据
如此 文件和目录的存储关系便明确。文件名称及inode号都是存储在 目录的data block 中的。
文件的读取过程
假如我们读取 /etc/passwd 这个文件
[root@host10 etc]# ll -di / /etc /etc/passwd
64 dr-xr-xr-x. 18 root root 264 May 11 2021 /
16777281 drwxr-xr-x. 79 root root 8192 Jul 4 05:18 /etc
18895742 -rw-r--r-- 1 root root 881 Dec 9 2021 /etc/passwd
由于目录树都是从根目录开始,因此透过挂载信息,可以找到挂载点的inode号码,得到根目录的inode内容,然后从中找到 名称为 etc 的目录,读取到inode 号码,再到该目录的data block 中找到 passwd 文件的inode号码,从中可以找到文件内容存储的data block 号码,进而读取数据。具体如下:
- 读取根目录 / 的 inode,通过挂载信息找到inode号码为64的 inode,判断 用户对该目录是否有权限
- 从64 inode中找到,存放文件记录的block 并从中寻找名为 etc 的文件记录,找到对应的inode号(16777281 )
- 根据etc目录 inode号码 找到inode 验证当前用户是否有权限,如果有权限 则从inode 中读取到 数据保存的 block
- 从etc 的block 中读取到 passwd 文件的 inode 号码,并找到对应的 inode
- 读取 passwd 的inode 检查是否有相关权限,如果有权限 则 找到 block 号码,读取文件内容
文件写入过程
当我们新建一个目录或文件时,文件系统是如何操作的呢?
- 按照上文中的步骤,检查用户对目录是否有相应的权限,
- 从 inode bitmap 找到未使用的inode号码,并将新文件的属性/权限信息写入
- 从 block map 中找到未使用的 data block 号码,并将文件数据写入到对应的 block
- 数据写入到 inode 和 block后,同步更新 inode bitmap block map 中对应数据的使用状态.
碎片整理
如果一个文件系统很大一个文件inode中保存的 block号码非常离散时,可能会导致读写的效率降低。如果想解决这个问题那就得 复制出所有文件内容,重新写入到硬盘,写入过程中尽量保证一个文件的数据块的连续性。这个过程就是我们所说的碎片整理。
数据不一致及日志式文件系统
数据不一致问题
在一些极端情况下如停电宕机等原因,导致仅写入了inode table 和 data block ,还没有来得及更新 inode/block bitmap,这个时候就导致了系统硬盘数据的不一致。这种问题如何解决呢?
ext2解决方式
ext2中如果发生上述问题,那么系统重新启动的时候,就会根据super block 中的信息 valid bit (是否挂载) filesystem state (是否 clean )等,来判断是否强制进行 数据一致性检查。如果需要检查 则 通过 e2fsck 来进行检查。这种检查非常耗时,需要将整个文件系统的数据都对比一遍。 这就是我们以前不正常关机 时,开机检查执行的动作。
日志式文件系统
为了解决强制数据一致性检查耗时的问题,后续的一些文件系统都提供了日志记录功能,
当有文件写入时,先在文件系统的日志记录区记录要写入的信息,然后再开始文件信息的写入,更新文件元数据,都写入完成后,日志去删除本次操作的日志。如此,出现数据不一致时,只需要检查日志区的日志就能知道哪些文件出问题了。
后续的ext3 和 ext4 都有这种日志机制


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











