







一、应用安装启动
1、软件准备
alertmanager-0.24.0.linux-amd64.tar.gz
blackbox_exporter-0.22.0.linux-amd64.tar.gz
node_exporter-1.4.0.linux-amd64.tar.gz
prometheus-2.40.0-rc.0.linux-amd64.tar.gz
2、配置文件
cat /data/prometheus/prometheus.yml #根据自己情况更改
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
alerting:
alertmanagers:
- static_configs:
- targets:
- 这里填写alertmanagers的ip:9093
# - alertmanager:9093
rule_files:
- "rules/*.rules" #这里定义rule文件
# - "second_rules.yml"
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: '定义一个名称'
metrics_path: /probe
params:
module: [blackbox_exporter里面的module名称]
static_configs:
- targets:
- http://api的ip/api
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 这里填写blackbox_exporter的ip:9115
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
cat /data/prometheus/rules/node.rules #这是一个node 的rules配置,可以直接使用,无需更改
groups:
- name: 主机状态-监控告警
rules:
- alert: 主机状态
expr: up == 0
for: 1m
labels:
status: 非常严重
severity: warning
annotations:
#summary: "服务器宕机"
description: "服务器延时超过5分钟"
- alert: CPU使用情况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 80
for: 1m
labels:
status: 一般告警
severity: warning
annotations:
#summary: "CPU使用率过高!"
description: "CPU使用大于80%(目前使用:{{$value}}%)"
- alert: 内存使用
expr: round(100- node_memory_MemAvailable_bytes{instance!="10.152.120.25:9100"}/node_memory_MemTotal_bytes{instance!="10.152.120.25:9100"}*100) > 80
for: 1m
labels:
status: 一般告警
severity: warning
annotations:
# summary: "内存使用率过高"
description: "内存使用率{{ $value }}%"
- alert: 25-内存使用
expr: round(100- node_memory_MemAvailable_bytes{instance=~"10.152.120.25:9100"}/node_memory_MemTotal_bytes{instance=~"10.152.120.25:9100"}*100) > 95
for: 1m
labels:
status: 一般告警
severity: warning
annotations:
#summary: "内存使用率过高"
description: "内存使用率{{ $value }}%"
- alert: IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: 严重告警
severity: warning
annotations:
# summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 网络
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
severity: warning
annotations:
# summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
severity: warning
status: 严重告警
annotations:
# summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 90
for: 1m
labels:
status: 严重告警
severity: warning
annotations:
# summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于90%(目前使用:{{$value}}%)"
cat /data/prometheus/rules/blackbox_http.rules #这是自定义的api监控rules,需要根据自己情况更改
groups:
- name: 接口状态 #组的名字,在这个文件中必须要唯一
rules:
- alert: http-api #告警的名字,在组中需要唯一
expr: probe_success{job="这里要对应job里面的名称"} == 0 #表达式, 执行结果为true: 表示需要告警
for: 1s #超过多少时间才认为需要告警(即up==0需要持续的时间)
labels:
status: 非常严重
severity: warning #定义标签
annotations:
description: "Job {{ $labels.job }} 中的接口 {{ $labels.instance }} 已经down掉."
summary: '接口 {{ $labels.instance }} down ! ! !'
cat /data/alertmanager/alertmanager.yml #定义告警配置
global:
resolve_timeout: 5m #每5分钟检测一次是否恢复
templates:
- '/data/alertmanager/wechat.tmpl' # Alertmanager微信告警模板
route:
group_by: ['alertname']
group_wait: 5s # 初次发送告警延时
group_interval: 1m # 距离第一次发送告警,等待多久再次发送告警
repeat_interval: 5m # 告警重发时间
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'ww8f28' # 企业微信中企业ID
to_party: '42' # 企业微信中创建的接收告警的告警部门ID
# to_user: 'zhai' # 企业微信中创建的接收告警的单个人唯一ID
agent_id: '100' # 企业微信中创建应用的AgentId
api_secret: 'wiZIFkuo' # 企业微信中,Prometheus应用的Secret
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']cat /data/blackbox_exporter/blackbox.yml
modules:
http_2xx:
prober: http
http_post_2xx:
prober: http
http:
method: POST
tcp_connect:
prober: tcp
pop3s_banner:
prober: tcp
tcp:
query_response:
- expect: "^+OK"
tls: true
tls_config:
insecure_skip_verify: false
grpc:
prober: grpc
grpc:
tls: true
preferred_ip_protocol: "ip4"
grpc_plain:
prober: grpc
grpc:
tls: false
service: "service1"
ssh_banner:
prober: tcp
tcp:
query_response:
- expect: "^SSH-2.0-"
- send: "SSH-2.0-blackbox-ssh-check"
irc_banner:
prober: tcp
tcp:
query_response:
- send: "NICK prober"
- send: "USER prober prober prober :prober"
- expect: "PING :([^ ]+)"
send: "PONG ${1}"
- expect: "^:[^ ]+ 001"
icmp:
prober: icmp
icmp_ttl5:
prober: icmp
timeout: 5s
icmp:
ttl: 5
##################以上都是默认配置无需更改##############
http_api: #定义模块名称,和prometheus的module一样
prober: http
timeout: 18s
http:
method: GET
headers:
token: 3579333KX4abK04i5
Content-Type: application/json
3、服务启动
#prometheus
/data/prometheus/prometheus --config.file=prometheus.yml --log.level=debug &
#备注 开启debug日志,方便差错
#alertmanager
/data/alertmanager/alertmanager --config.file=alertmanager.yml --log.level=debug &
#blackbox_exporter
/data/blackbox_exporter/blackbox_exporter --config.file=blackbox.yml &
#node_exporter
/data/node_exporter/node_exporter &
二、企业微信配置
企业ID

部门ID
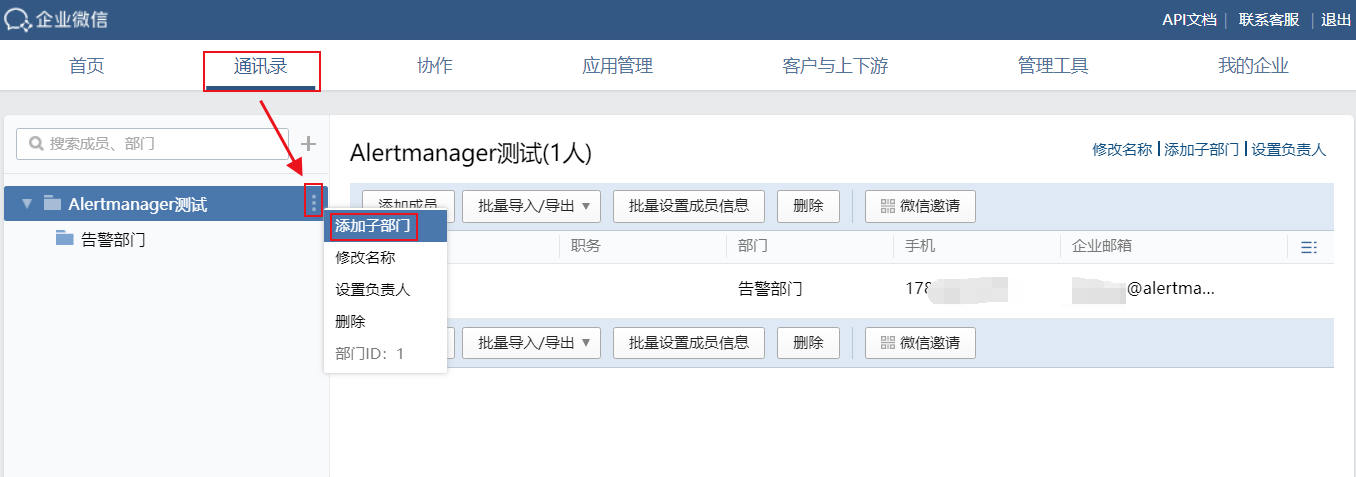
告警AgentId和Secret

配置可信ip(最新的必须加,否则连接失败)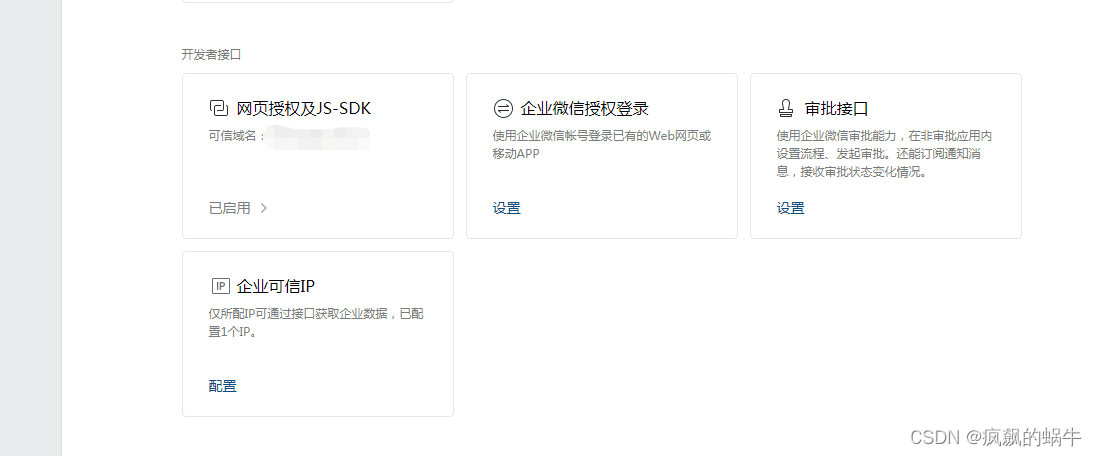
三、效果图

















 5923
5923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











