






一、本文说明:
本文为自己学习的笔记,用来记录数分的相关知识,方便记录查阅。
二、指标体系建设与数据分析:
1、指标体系概念:
①:什么是指标体系: 企业指标的集合
②:好的指标体系的特征:
1、科学性: 指标必须符合业务状况、计算方式要符合行业标准;
2、系统性:体现各指标的逻辑关系;
3、代表性:选取的指标能突出反应业务的现状;
4、统一性:要保证各个部门口径的统一;
③:为什么要建设指标系统:
- 不知道口径,数据平台出去的指标,用户甚至数据研发自己都不知道具体的口径,需要翻代码
- 指标耦合,不方便下线和口径调整,现有报表都是需求驱动,一个sql中可能对应了多个指标的计算,导致指标下线,逻辑调整都要相互影响
- 指标重复计算,不同报表用到同一个指标,需要重复的写同样的逻辑,加重集群的计算压力,且指标口径一调整,需要多处调整
- 指标血缘无法跟踪,数据团队交付的报表时间久了不知道谁提的,不知道用到了哪些表,不知道最终被用到了哪些团队
2、指标体系的作用:
1、更好的看清业务现状(用数据说话,意见减少歧义)
2、找出业务痛点,确立分析主体(梳理关键指标)
3、智能指导业务(预测、预警、异常归因—找到异常的原因)
4、帮助 优化产品/业务逻辑
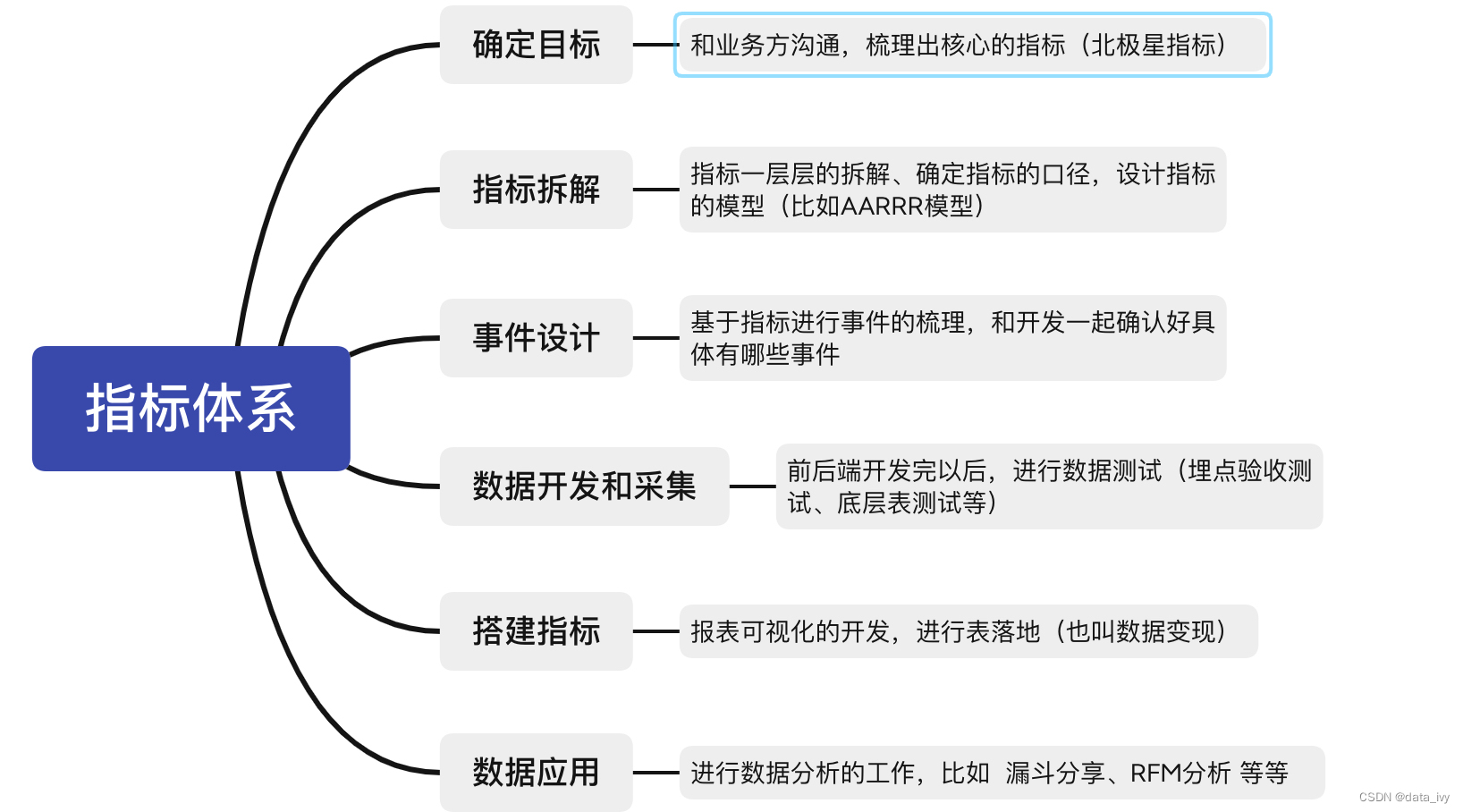
3、怎么进行指标体系建设:
1、确定目标:和业务方沟通,梳理出核心的指标(北极星指标)
2、指标拆解:指标一层层的拆解、确定指标的口径,设计指标的模型(比如AARRR模型)
3、事件设计:基于指标进行事件的梳理,和开发一起确认好具体有哪些事件
4、数据开发和采集:前后端开发完以后,进行数据测试(埋点验收测试、底层表测试等)
5、搭建指标:报表可视化的开发,进行表落地(也叫数据变现)
6、数据应用:进行数据分析的工作,比如 漏斗分享、RFM分析 等等
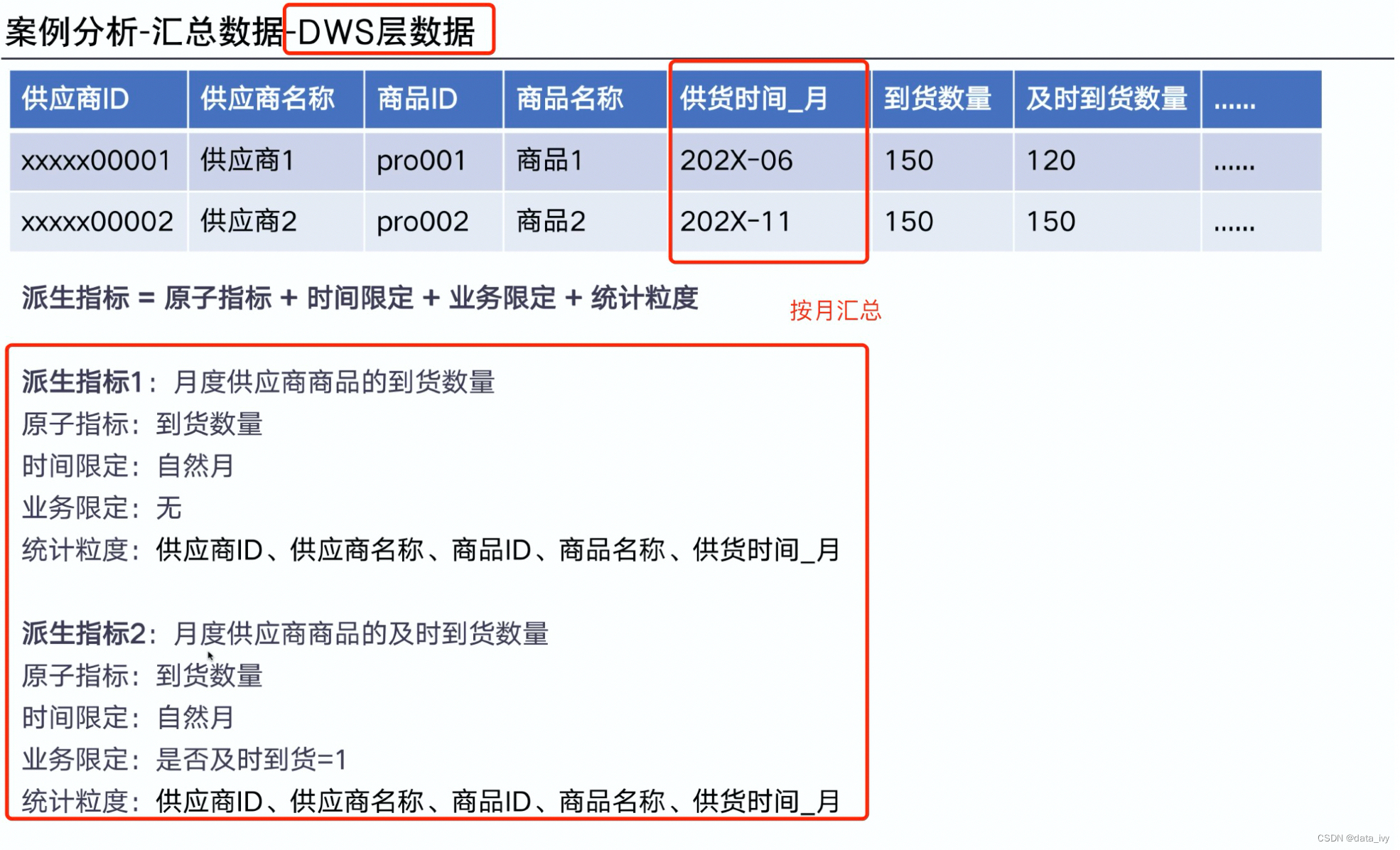
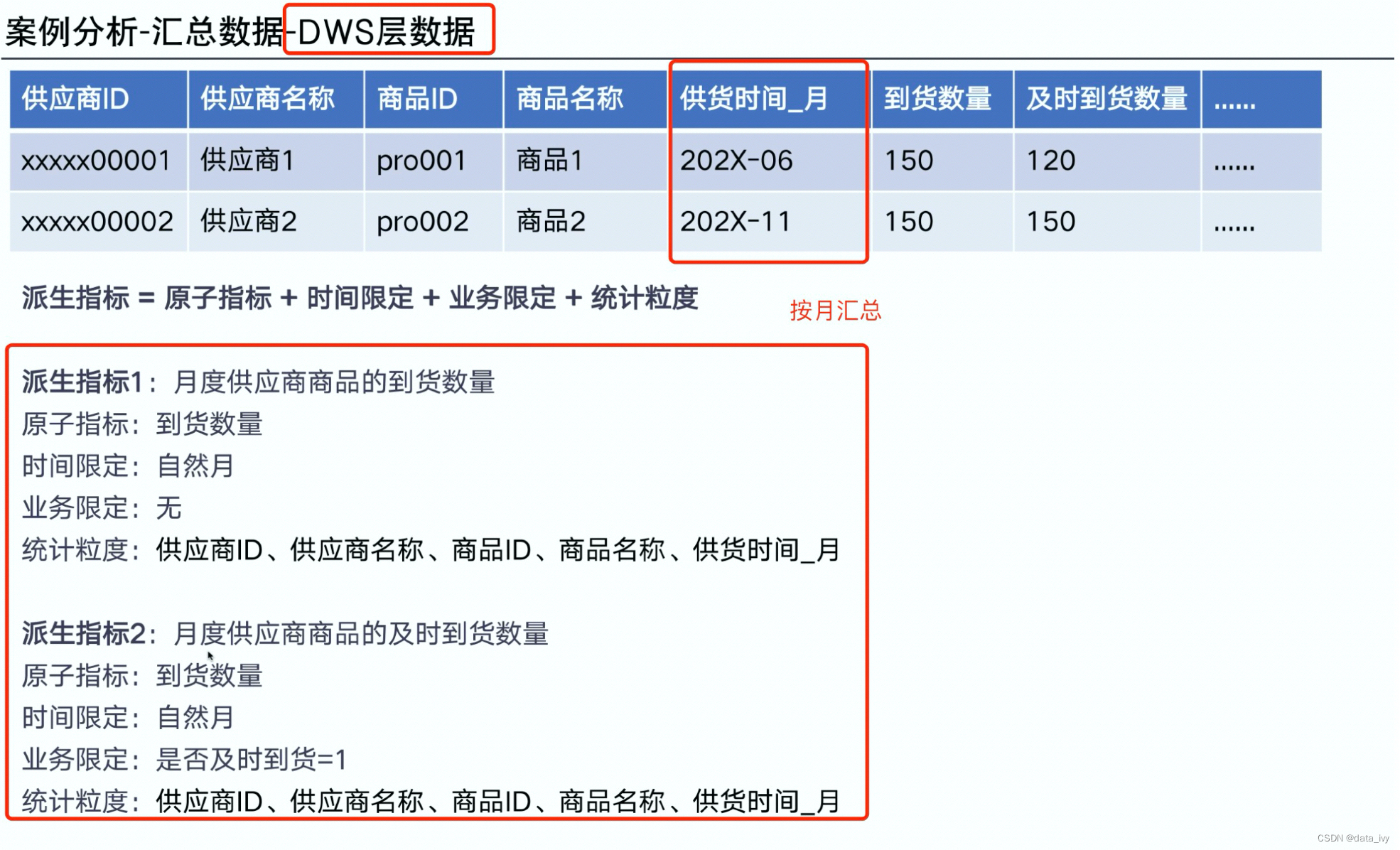
4、指标分类: 原子指标、派生指标、复合指标
DWS层数据:
ADS层数据:里面也是存在DWD层的字段

三、数仓介绍:
1、为什么需要数仓:
1、解决数据孤岛,统一数据出口(避免多指标问题)
2、解决查询数据慢的问题,数据量大,可以提前做汇总
2、数据分层的好处:
清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径
复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
3、数仓分层:
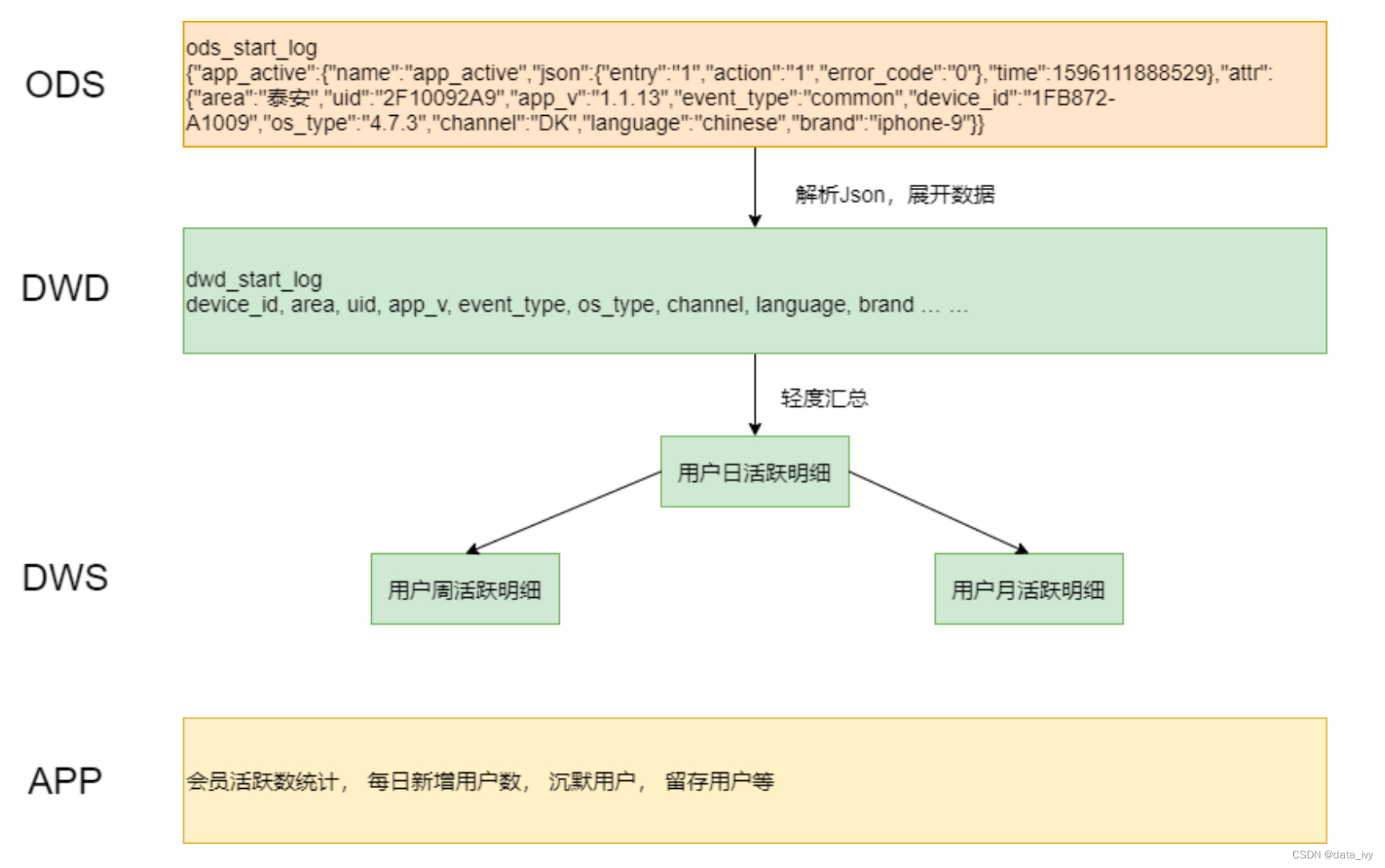
1、ODS层:贴源层,将原始数据原封不动的同步到ODS中。
作用:计算任务时,可以以ODS层的数据为基础进行计算,不给业务库增加负担。
2、DIM层:DIM层存放的是一个个的维度数据,比如年月、地区、客户端类型 等等

3、DWD层:(数据明细层)(去除掉不需要的列,维度退化、ETL)
①:ETL (去除空数据、去除脏数据、去超过值域范围的数据等等);
②:事实表关联维度表,产生明细数据

4、DWS层:汇总层,计算派生指标、复合指标等。一个DWD可以生成多个DWS。 按不同的主题(不同的统计粒度)
派生指标:原子指标+时间限定+业务限定(相当于where)+ 统计粒度
该层数据:
5、ADS(DM)数据集市层 :数据挖掘、自定义查询(应用集市)
4、业务板块、数据域、业务过程:作用(将对应的数据进行分级分类)
业务板块:财务、人力、供应链(10大领域)
数据域(主题):员工域、假勤域、薪资域
业务过程:浏览、下单、支付、退货、售后等等(不同的业务过程对应不同的表) 分析业务找到相应的业务过程

5、建模的方式: OLAP、OLTP
OLAP: OLAP的建模的方法有 ER建模、维度建模
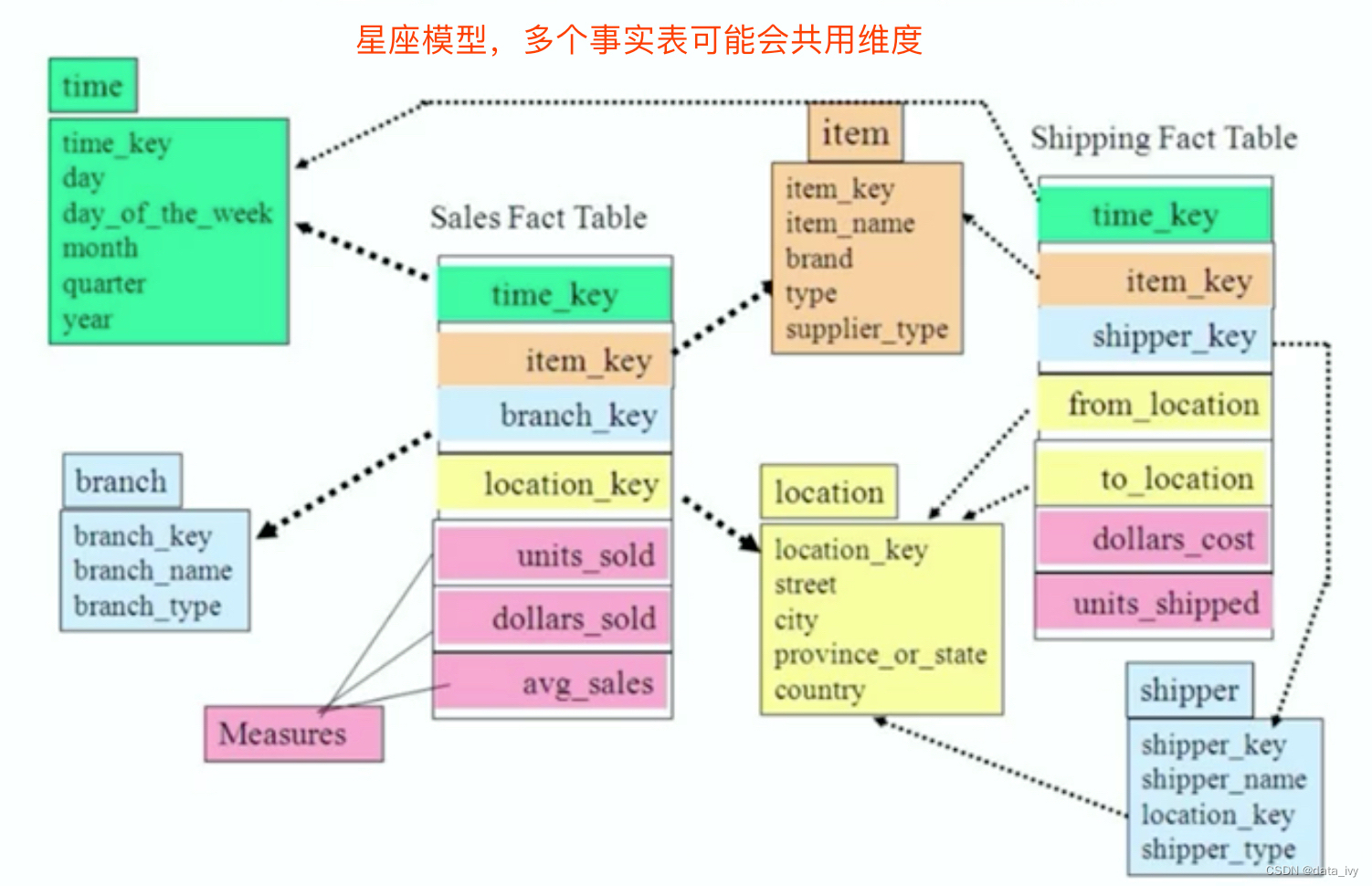
在维度模型,表被分为事实表、维度表。 建立的维度模型又分为星型模型、雪花模型、星座模型。

6、ER实体关系模型:数据库 设计的理论模型

7、实时数仓:Flink+kafka (以前流行 SparkStreaming)
1、离线数仓都是存储在 HDFS 中,但是实时数仓,数据一般会存在 Kafka 里面。但是同时也会归档一份到 HDFS,因为要保存历史数据进行回算或者补数据;
2、 数仓减少层数的好处:实时处理数据的时候,每建一个层次,数据必然会多产生一定的延迟;(所以好多没有DWD、DWS);
3、DIM 层维度数据主要使用 MySQL、Hbase等存储;
四、数据库介绍:
1、数据库的类型:
关系型数据库:MySQL、Oracle、postgreSQL、DB2 …
非关系型数据库:Hbase、MongoDB、Redis ……
2、数据库存储方式:
①:列存储数据库:BigTable、HBase、clickhouse(即席查询)、hive等
(有可能缺失一列,缺失的这一列是真没有而不是为空)
②:键值存储数据库: Redis(K/V型 键值存储:name:zhangsan)面向高并发的缓存存储:
③:文档数据库: MongoDB
④:图存储数据库:Neo4J
⑤:内存数据网格:Hazelcast
3、数据类型:
int:整型 double/decimal:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值为999.99;
char:固定长度字符串类型;
char(10) 如果不足10位则会自动补足10位:'abc '
varchar:可变长度字符串类型;varchar(10) 如果不足10位不会补足:'abc',性能不如char高
text:字符串类型;适用于大文本内容。
blob:字节类型; (最大 65K)
date:日期类型,格式为:yyyy-MM-dd;
time:时间类型,格式为:hh:mm:ss
timestamp:时间戳类型 yyyy-MM-dd hh:mm:ss 会自动赋值
datetime:日期时间类型 yyyy-MM-dd hh:mm:ss

4、索引介绍:
索引的概述:
- 直接找到哪一页去检索,避免全表扫描。提高查询速度,会影响where 和 order by
- 索引是针对于字段的,需要添加到字段上
常见索引分类:主键索引、唯一索引、普通索引、复合索引
主键索引(了解): -- 创建主键字段的时候会自动创建主键索引
唯一索引(了解):特点: 索引列的所有值都只能出现一次(不能重复)
// 创建表的时候直接添加唯一索引
CREATE TABLE 表名( 列名 类型(长度), UNIQUE [索引名称] (列名));
// 使用create语句创建: 在已有的表上创建索引
create unique index 索引名 on 表名(列名(长度))普通索引:(重要)
概述:普通索引没有非空、唯一等等要求普通索引的唯一作用是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHERE column=)或 排序条件(ORDER BY column)中的数据列创建索引。
-- 创建普通单列索引,使用create index
create index index_name on test (name) -- create index 索引名 on 表名(列名[长度])
-- 创建普通复合索引 (可用于where有多个条件的场景 where name =''and id ='')
create index index_name_age_id on test (name,age,id)
-- 删除索引
alter table test drop index index_name -- alter table 表名 DROP INDEX 索引名;5、视图:(也叫虚表)
作用:
1、权限控制: 如果直接将表给用户,那么用户能查询表的所有的字段。 我们可以将权限允许访问的字段生成视图供用户访问,将表对用户进行隐藏;
2、简单性:可以将一次复杂的查询 构建成一张视图, 用户只要查询视图就可以获取想要得到的信息 (不需要用户再编写复杂的SQL)
create view view_name as select XXX … // 创建好的视图能在from后面使用 from 视图名6、事务:
概念:
事务就是完成同一个业务的多个DML操作(例如转账,需要操作两次DML,小明-1000,小王+1000)
特性:
①:原子性:要么同时成功,要么都失败
②:一致性:事务执行前后,数据库前后的数据是一致的(转账-1000,对方只能是增加1000不能是别的金额)
③:隔离性:数据库允许多个事务同时执行,但是并行的事务之间不能相互影响(隔离的)
7、存储过程: (了解用的不多了)
概念:将一段SQL指令进行封装,编译之后存储在服务器上,并且定义个名字(比如test1),当下次需要时,直接调用名字即可(就是 function),适用于业务固定,且访问量不是很大的场景。

定义的存储过程会跑到函数里面
优点:
①:防止拦截SQL篡改;
②:无需重复的编写、编译操作,提升性能
缺点:
①:如果高并发访问,存储过程会增加数据库的连接时间(因为将复杂的业务交给了数据库来处理)
②:换数据库时(MySQL=>Oracle)需要重新编写
五、SQL:
1、SQL的常用的分类:
DDL: 数据定义语言, 用于对数据库对象(视图、索引、数据库、数据表)的创建、删除、修改等操作;
DML: 数据操作语言,用于完成对数据表中的数据进行增加、删除、修改;
DQL: 数据查询语言,用于完成对数据表中的数据进行查询;
DCL: 数据控制语言,用于管理事务管理等操作,比如回滚操作等;
2、DDL语法: 数据库操作:
// 创建数据库
create database 数据库名称 -- create database bd_test character set utf8
// 删除数据库
drop database 数据库名称
// 修改数据库,例如修改编码
alter database 数据库名称 charset = 编码格式
//修改数据库名
rename database olddbname to newdbname
// 查看数据库列表
show databases
// 切换数据库
use 数据库名称3、表操作:
// SQL 约束:
主键约束:primary key // 非空且唯一;
alter table tmp add primary key (eid) -- 给已经存在的表增加主键约束
alter table tmp drop primary key -- 删除主键
主键自增长:auto_increment // 从1开始,步长为1;
非空约束:not null // 不允许某列的内容为空;
设置列的默认值:default
唯一约束:unique // 该列的内容必须唯一,不算 null ;
外键约束:foreign key // A表中的外键指向了B表的主键,外键所在的表叫从表,指向的B表叫主表,主外键字段类型要一致!
-- CONSTRAINT 从表 FOREIGN KEY (外键字段名) REFERENCES depart (主键字段名)
-- alter table 从表 ADD 【CONSTRAINT】【外键约束名称】FOREIGN KEY (外键字段名) REFERENCES depart (主键字段名) ##从已有表添加外键
-- alter table 表 drop FOREIGN KEY 外键字段 删除外键
// 创建表
DROP TABLE IF EXISTS 't_student'; ## 如果表存在就移除;
create table t_student (
id bigint primary key auto_increment,
naem varchar(25) unique,
email varchar(25) not null,
age int default 18,
sid int,
CONSTRAINT emp_dept_fk FOREIGN KEY (dept_id) REFERENCES depart (id) -- CONSTRAINT 从表 FOREIGN KEY (外键字段名) REFERENCES depart (主键字段名)
)
// 复制表结构,创建出一个新表 (不复制数据)
create table newTable like oldTable;
// 查看有哪些表
show tables;
// 删除表
drop table 表名
// 修改表
alter table 旧表名 to 新表名 ## 修改表名
alter table 表名 add stu_qq varchar(25) ## 添加字段 alter table test add column 字段名 char(10) null (char类型 默认值是null)
alter table 表名 modify 字段名 vachar(200) ## 修改表中字段的数据类型或长度(本例就是长度修改为200)
alter table 表名 change 旧字段名 新字段名 vachar(10) #修改表中字段的数据类型或长度(本例就是替换字段名,同时修改字段长度)
alter table 表名 drop 字段1,drop 字段2 ## 删除多个字段
alter table 表名 character set utf8 ## 修改表的字符集4、DML语法: 数据表的增、删、修改操作;
// 插入指定字段数据,其他字段默认为null
insert into 表名 (列2) value (值2)
// 插入全部数据
方法一:insert into 表名 (列1,列2) values (值1,值2)
insert into 表名 (name,age,email) values ('xiaoming',18,'xx@qq.com') ## 插入完整数据
方法二:
insert into 表名 values ('xiaoming',18,'xx@qq.com') ## 插入完整数据
// 修改字段数据
update 表名 set 字段名 = 值
## update student set address = '成都' where name = '王五'
## update student set address = '成都',sex ='女' -- 没有where这一列所有的数据都会修改
// 删除数据
delete from 表名 [ where 条件] ## 没有where,全表的数据都会被删除
## delete from where id = 1;
truncate table 表名 ## 删除所有数据,会直接删除整个表,然后在创建字段效率很高,删除以后逐渐也没了5、DQL语法: 数据的查询语句
// distinct 消除重复
select distinct 列名 from 表名
select distinct 列名1,列名2 from 表名 ## distinct 放在2个字段前,是说2个字段组合后才去判断是否重复,如果重复才去重
-- select distinct dept_name from emp
// 算数运算符(+,-,*,/)
select id,salaPrice * disCount from 表名 ## 查询所有货物的id 和折扣价(折扣价=销售价*折扣)
-- select ename,salary+1000 from emp
// as别名
select 列名 as 别名 from 表名 where 条件 ## 写法一 select 列名 别名 from where 条件 ## 写法二
-- select ename as '姓名',salary as '工资' from 表名
-- select ename '姓名',salary '工资' from 表名
// concat 按格式输出
select concat (productName,"商品的零售价为:", salePrice) from product
// 比较运算符(=, >, >=, <, <=, !=)
select * from product where productName = '罗技鼠标'
select *,salePrice * discount from product WHERE salePrice * discount > 350; ## 查询批发价大于350的货品信息(批发价 = 销售价*折扣)
// 逻辑运算符(AND、OR、NOT)
select * from product where dir_id = 2 or dir_id = 4;
select * from product where not dir_id = 2;
// 范围 between and 集合 in
select * from product where not salePrice between 300 and 400 ## 售价不在 300 - 400 之间的货品信息
select * from product where name in ('王五','赵六') ## 查询名称为王五和赵六 两个人的信息
// 判空 ( is null ) 用法: where 列名 is null
select * from product where productName is null ## 查询商品名为NULL的所有商品信息
select * from product where productName = '' ## 查询商品名为NULL的所有商品信息
// 模糊匹配 ( like % _ ) 语法: where 列名 LIKE "%M_"
## % 表示任意多个的字符 【张%】 查询姓张的人
## _ 表示任意一个字符 _o% 查询第二个字符为o
select * from product where productName LIKE '%鼠标__' ## 查询任意品牌的鼠标型号,例如罗技鼠标M9
// 排序 asc升序 desc降序,默认升序
select * from product order by dir_id desc,salePrice asc ## 组合排序,先按编号,如果分类编号相同再按工资 升序排序
// 聚合函数 count 统计数量、sum 求和、max、min、avg
select sum (salePrice) from pruduct ## 销售价求和
select count(*) from product ## 等于select count(1) from product -- 1和* 都是占位符
// UNION 数据汇总在一个表里面
select * from stu_table where stu_id = 1 UNION select * from stu_table where stu_id = 2 ## 数据合并到一起
//分页查询 limit
select * from 表 limit 2 ## 只返回前两条数据
select * from 表 limit 2,5 ## 从索引为2开始,返回5条数据(2也叫偏移量)
// 分组查询 , having 是对【聚合后的“结果”】进行的过滤
select gender, avg (salary) from table_name group by gender; // 求男和女员工的平均工资
select dept_name, avg (salary) from table_name where dept_name is not null group by dept_name; // 求每个部门的平均工资(不为null)
select dept_name, avg (salary) from table_name where dept_name is not null group by dept_name having avg(salary)>6000 ##求每个部门的平均工资(不为null)且大于6000 ;
select product,buyer,sum(money) from 表 group by product,buyer ## 多个 group by, 每个用户在每种产品上花了多少钱
// 获得的结果
product buyer sum
-------------------------
PD001 Todd 36
PD002 Lily 24
// 多表联查 inner join(inner可以省略) 、left join 、right join(左右关联 就是哪个表的数据展示为 null 的区别)
select * from tableName1 join tableName2 on tableName1.cid = tableName2.class_id ## 链接一般都用on 而 不用where(效率慢)
// 子查询 (嵌套查询) 公司那种类型 where类型 from类型
select * from students where cid in ( select class_id from students where price <2000 ) -- where类型
select * from
(
select c.cname ,count(p .pname) from category c LEFT JOIN product p on c.cid = p.pid GROUP BY c.cname
) a -- from类型
// 合并查询 union (用于合并多个select 的结果集,并消除重复行)两合并表的数据类型需要一致(要不没法合并一个表啊)
select Aid,Aname from tableA
union
select Bid,Bname from tableB
-- union all 不去重
//表的别名
需求查询cid = 1 的班级中性别为男的学生信息
select * from ( select * from students where cid = 1 ) t where t.stu_gender = '男'; -- t 是个别名,这个例子没有别名报错
// DQL字句的执行顺序
1)FROM 字句:从哪张表中去查数据;
2)JOIN table:先确定表,在确定关联条件;
3)ON 条件:表绑定条件;
4)WHERE字句:筛选需要的行数据;
5)GROUP BY子句:分组操作;
6)HAVING:对分组后的记录进行聚合;
7)SELECT字句:筛选需要显示的列数据;(对字段 AS 起别名是在这时候,所以 WHERE 中不能用字段的别名,ORDER BY 中可以使用别名);
8)DISTINCT:去重;
9)ORDER BY子句:排序操作;
10)LIMIT子句:限制条件;6、SQL普通函数说明:

六、窗口函数:
1、概述:
窗口函数又叫分析函数,用于解决相对复杂的报表统计分析场景 (Oracle、MySQL8.0以上都支持),每一条数据都要在此窗口集合(数据集)里面执行数据
2、基本用法:
函数 (expr) over(子句) -- over 用来指定窗口的范围
函数名 (expr) over(partition by <要分列的组> order by <要排序的列> rows between <数据范围> )
数据范围示例:
rows between 2 preceding and current row # 取当前行和 当前行的前面两行
rows between unbounded preceding and current row # 包括本行和本行之前所有的行
rows between current row and unbounded following # 包括本行和之后所有的行
rows between 3 preceding and 1 following # 当前行的前面三行和当前行的下面一行,总共五行
# 当order by 后面缺少窗口从句条件(写了order by 后边就不写了),窗口规范默认是rows between unbounded preceding and current row (当前行及以上的所有数据)
# 当order by 和窗口从句都缺失(写了partition by后边就不写了), 窗口规范默认是rows between unbounded preceding and unbounded following( 分组内的所有数据 )3、窗口函数分类:
专有窗口函数: rank dense_rank row_number
聚合类窗口函数:sum count max min avg
4、聚合类窗口函数和普通场景下的聚合函数,二者区别:
普通场景下的聚合函数是将多条记录聚合为一条(多条合并一条);
窗口函数是每条记录都会执行,有几条记录执行完还是几条(多条到多条)
5、窗口函数的应用:
①:累计求和 sum() over()
// 查询出2019年每月的支付总额和当年累积支付总额
SELECT
a.MONTH,-- 月份
a.pay_amount,-- 当月总支付金额
sum( a.pay_amount ) over ( ORDER BY a.MONTH ) -- 就是2019年的数据,所以不用分组
-- --此时没有使用rows指定窗口数据范围,默认当前行及其之前的所有行
FROM
( SELECT MONTH ( pay_time ) MONTH, sum( pay_amount ) pay_amount
FROM user_trade
WHERE
YEAR ( pay_time ) = 2019 GROUP BY MONTH ( pay_time )
) a
// 查询出2018-2019年每月的支付总额和当年累积支付总额
SELECT a.year,
a.month,
a.pay_amount,
sum(a.pay_amount) over(partition by a.year order by a.month) -- 基于year进行了分组
FROM
(
SELECT year(pay_time) year,
month(pay_time) month,
sum(pay_amount) pay_amount
FROM user_trade
WHERE year(pay_time) in (2018,2019)
GROUP BY year(pay_time),
month(pay_time)
)a;②:移动平均金额 avg() over() --考察操作rows窗口范围的能力
SELECT a.month,
a.pay_amount,
avg(a.pay_amount) over(order by a.month rows between 2 preceding
and current row)
FROM
(
SELECT month(pay_time) month,
sum(pay_amount) pay_amount
FROM user_trade
WHERE year(pay_time)=2019
GROUP BY month(pay_time)
) a;③:最大/小值:max()/min() over()
// 查询出每四个月的最大月总支付金额
SELECT a.month,
a.pay_amount,
max(a.pay_amount) over(order by a.month rows between 3 preceding
and current row)
FROM
(
SELECT substr(pay_time,1,7) as month,
sum(pay_amount) as pay_amount
FROM user_trade
GROUP BY substr(pay_time,1,7)
) a;④:排序函数
- row_number() over() -- 排序相同时不会重复,会根据顺序排序 (纯粹杭斌好)
- rank() over() -- 排序相同时会重复,总数不变,即会出现1、1、3这样的排序结果;
- dense_rank() over() -- 排序排序相同时会重复,总数减少,即会出现1、1、2这样的排序结果;
// 先把各个用户所购买商品涉及的品类数给统计出来
SELECT user_name,count( DISTINCT goods_category ) category_count,
row_number() over(order by count( DISTINCT goods_category ) ) order1, -- row_number生成了行的编号从1开始
rank() over(order by count( DISTINCT goods_category ) ) order2,
dense_rank() over(order by count( DISTINCT goods_category ) ) order3
FROM user_trade
WHERE substring( pay_time, 1, 7 ) = '2020-01'
GROUP BY user_name;⑤:ntile 分组切片(平均分组)
ntile(n) over(partition by ...A... order by ...B... )
n: 切分的片数
A: 分组的字段名称
B: 排序的字段名称
不支持rows between
// 查询出将2020年2月的支付用户,按照支付金额分成5组后的结果
SELECT user_name, sum(pay_amount) pay_amount,
ntile(5) over(order by sum(pay_amount) desc) level
FROM user_trade
WHERE substr(pay_time,1,7)='2020-02'
GROUP BY user_name;
// 查询出2020年支付金额排名前30%的所有用户
SELECT a.user_name,a.pay_amount,a.level
FROM
(
SELECT user_name, sum(pay_amount) pay_amount,
ntile(10) over(order by sum(pay_amount) desc) level
FROM user_trade
WHERE year(pay_time)=2020
GROUP BY user_name
)a
WHERE a.level in (1,2,3);⑥:偏移分析函数
- lag 向下偏移 ( 偏移字段,偏移度, 找不到默认就取当前行字段的数据) over()
- lead 向上偏移 ( 偏移字段,偏移度, 找不到默认就取当前行字段的数据 ) over()
第三个字段不写的话,默认为null
// 查询出King和West的时间偏移(前N行) 可用于今天和明天的数据 进行对比 计算等等
SELECT user_name,pay_time,
lag(pay_time,1,pay_time) over(partition by user_name order by pay_time) lag1,-- 没有传入偏移量,那么默认就是1, 第三个参数不传的话找不到,此处也没有给默认值,为null
lag(pay_time) over(partition by user_name order by pay_time) -- 第三个参数不传的话找不到就展示null
lag1_s,lag(pay_time,2,pay_time) over(partition by user_name order by pay_time) lag2,
lag(pay_time,2) over(partition by user_name order by pay_time) lag2_s
FROM user_trade
WHERE user_name in ('King','West');
// King和West的时间偏移(后N行)
SELECT user_name, pay_time,
lead(pay_time,1,pay_time) over(partition by user_name order by pay_time) lead1,
lead(pay_time) over(partition by user_name order by pay_time) lead2,
lead(pay_time,2,pay_time) over(partition by user_name order by pay_time) lead3,
lead(pay_time,2) over(partition by user_name order by pay_time) lead4
FROM user_trade
WHERE user_name in ('King','West');
// 查询出支付时间 间隔超过100天的用户数
SELECT count(distinct user_name)
FROM
(
SELECT user_name,pay_time, lead(pay_time) over(partition by user_name order bypay_time) lead_dt
FROM user_trade
) a
WHERE a.lead_dt is not null and datediff(a.lead_dt,a.pay_time)>100;
// 查询出每年支付时间间隔最长的用户
SELECT years, b.user_name,b.pay_days
FROM
(
SELECT years, a.user_name,
datediff(a.pay_time,a.lag_dt) pay_days,
rank() over(partition by years order by datediff(a.pay_time,a.lag_dt) desc) rank1
FROM
(
SELECT year(pay_time) as years, user_name,
pay_time,
lag(pay_time) over(partition by user_name,year(pay_time) order by pay_time) lag_dt
FROM user_trade)a
WHERE a.lag_dt is not null
) b
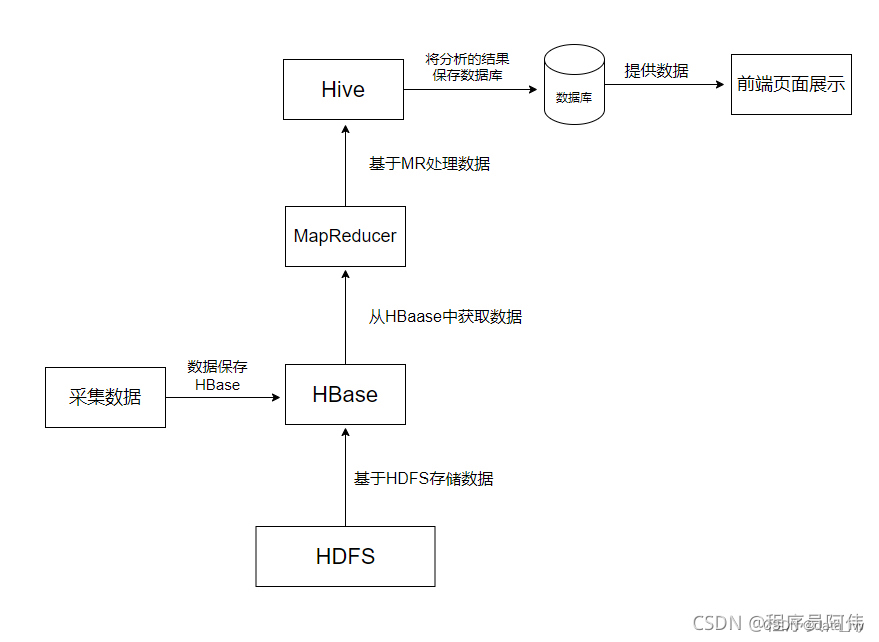
WHERE b.rank1=1;七、HIVE
1、概述:
Hadoop是一个开源的分布式存储和分析计算的平台,使用Java开发,是为了解决海量数据的存储和计算的工具。用户无需了解分布式的底层细节,就可以开发分布式的程序。
2、核心组件:
①:HDFS: 分布式文件存储系统,负责数据存储。
HDFS的存储特点:
- 把大的文件拆成128M的小数据块,HDFS会统一管理多台机器的存储空间(大小可以修改)
- HDFS不适合做小文件低延迟的存储,小文件存储查询比较慢(适合离线开发的场景,不能做实时开发)
- HDFS追加数据,只能在末尾追加,不允许任意位置的插取
②:MapReduce:分布式计算框架,负责数据的计算(提供了任务在多台机器上运算的框架)
(先map计算,等任务完成后reduce汇总)
③:Yarn: 分布式的资源调度框架,为Hadoop的 计算 提供统一的调度,例如计算需要的 CPU、
内存、宽带 等等,yarn除了支持MapReduce,也能支持spark、Tez等

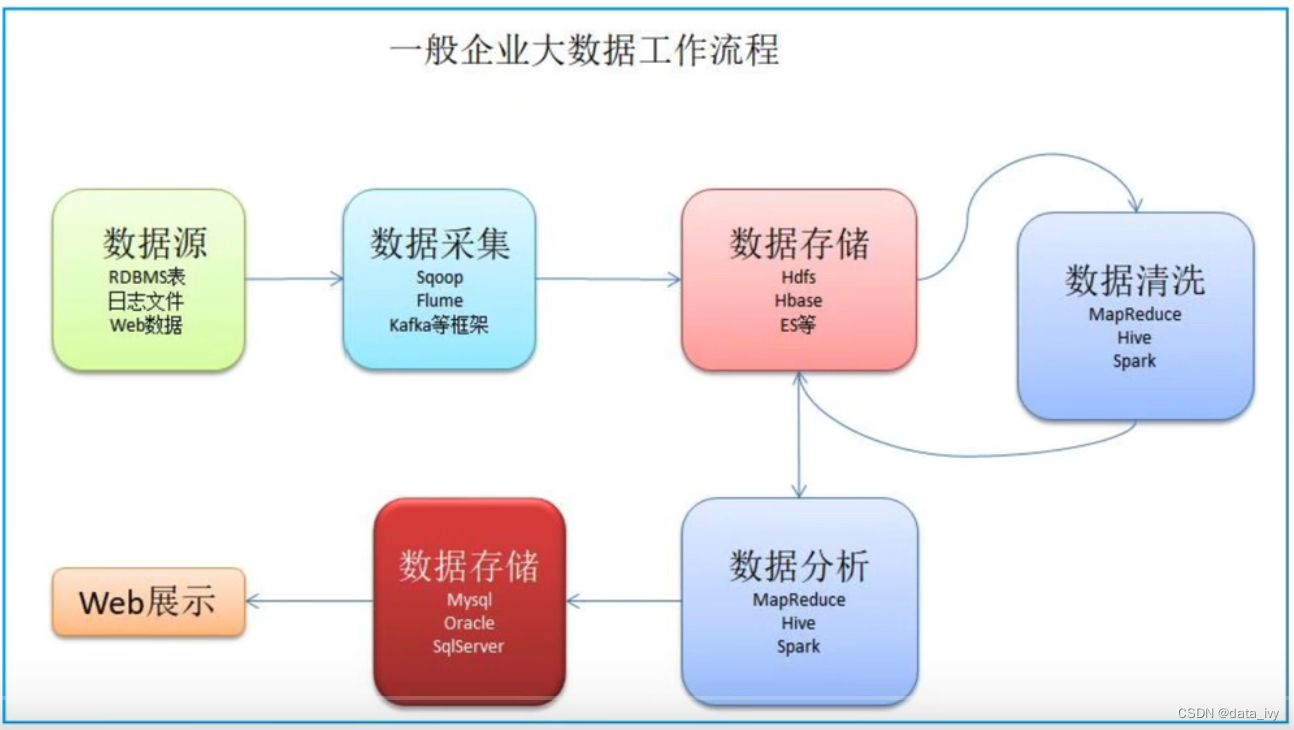
3、Hadoop的生态圈:
4、Hive介绍:
①:Hive概述 :
Hive 把HQL翻译成MapReduce的程序,然后再计算,这是它最大的价值。
②:为什么使用Hive? 不用Hive是否能够处理HDFS上那些结构化的数据呢?
不用Hive,直接写 MapReduce,也可以操作数据。但是MapReduce 学习成本太高, 开发难度也大。
③:Hive的特点:
- Hive 本身并不支持数据存储和处理,只是一个面向用户的编程接口
- Hive 依赖分布式文件系统HDFS存储数据
- Hive 依赖分布式并行计算模型MapReduce 处理数据(也可以是spark等其他引擎)
- 借鉴SQL语言设计了新的查询语言HiveQL
- Hive将元数据存储到源数据库中,元数据一般存储在derby 或者 MySQL源数据库上。(元数据一般包括 表名、表类型、存储空间、分区、表所在目录等等);
5、HBase概述:
由于Hive 只支持查询,而HBase正是为此而诞生的。HBase是用来修改数仓数据的,一般公司数仓不允许修改,所以不用Hbase,但是有特殊场景需要修改数仓的话可以使用Hbase(增删改查)。
Hbase是列存储,又有主键,修改数据的效率很高,所以使用他。 kudu 和 Hbase作用是一样的。
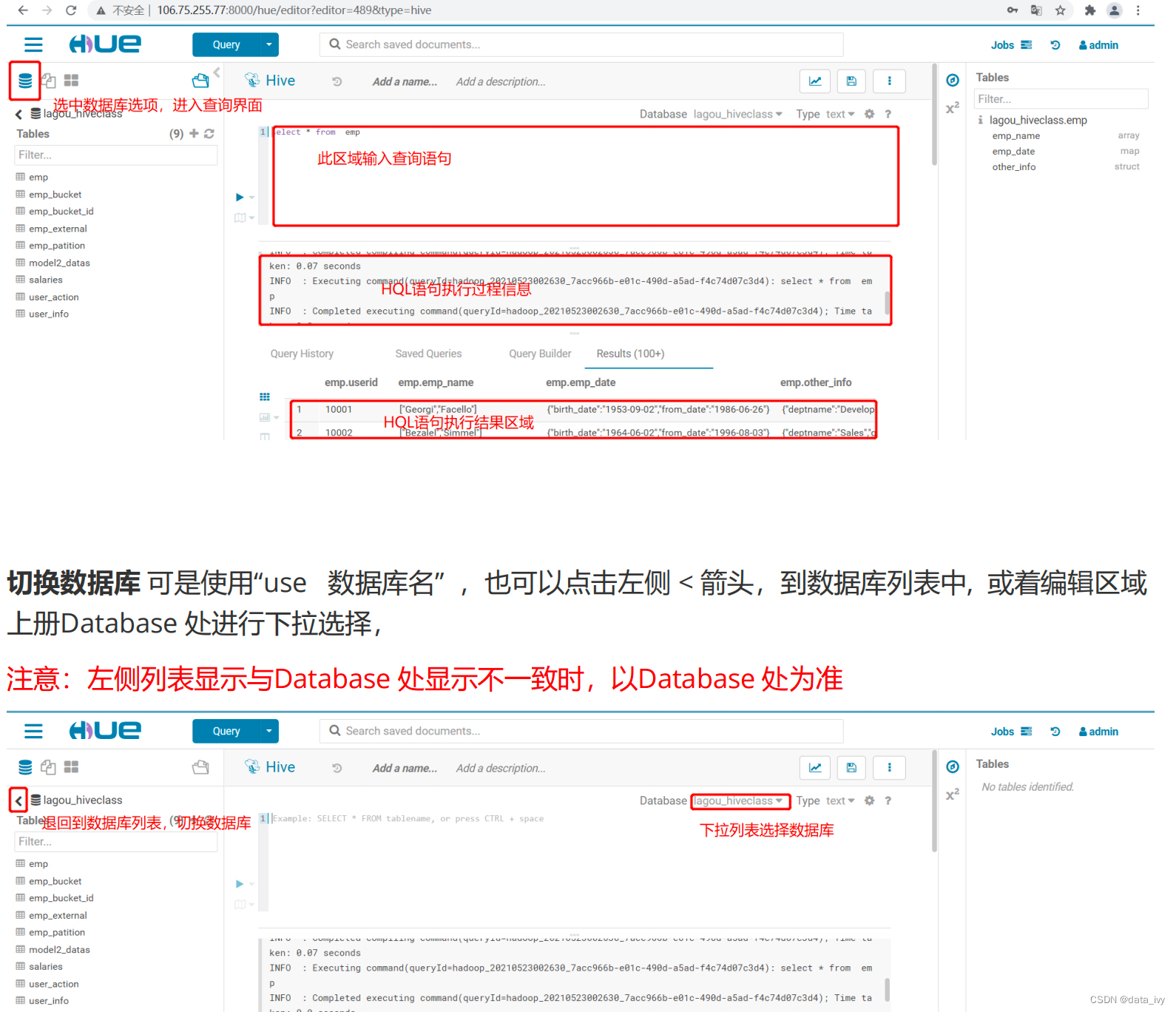
6、Hue
①:概述:
HUE相当于是Navicat,是一个网页端的操作界面UI系统,有了它就不用通过使用 Linux命令进行HDFS的访问和文件浏览,可以写HQL
②:Hue能做什么:
访问HDFS和文件浏览
通过web调试和开发hive以及数据结果展示
Hive的元数据(metastore)查询
数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
……
输入:http://113.31.147.119:8888/hue (各个公司可能不一样)
7、HIve 和MySQL的技术差异点:
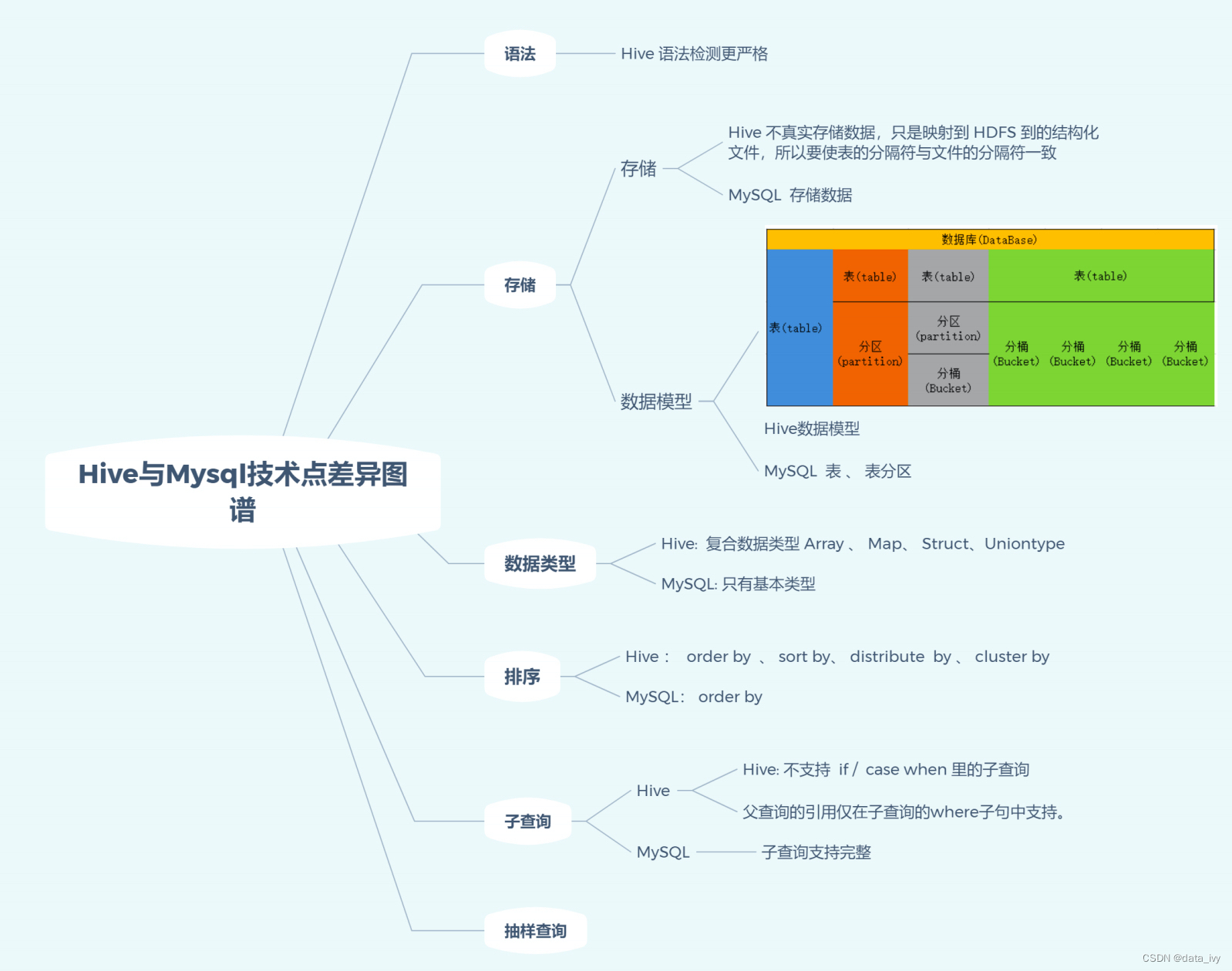
1、排序 Hive分 分区排序、分桶排序 等等,MySQL只有order by;
2、hive有 抽样查询,MySQL没有
3、Hive的子查询支持的不太好,老版本不支持 if/case when里面嵌套子查询;
4、MySQL只有基础类型,hive有复合类型 array(数组)、map(键值对)等等;
8、Hive复合类型的数据查询:
-- 访问数组 最后一个名字以W开头的 访问数组
select * from emp where emp_name[1] rlike "^W"
-- 访问map
select * from emp where emp_date["birth_date"] between to_date("1950-1-1") and to_date("1959-12-31")
9、Hive 内部表和外部表的区别:
1、两者的区别:
Hive表创建时要做的两件事,第一,在hdfs下创表。 第二,在元数据库mysql创建相应表的描述(元数据)。
但是在drop删除表的时候,内部表把元数据和具体数据都删除,而外部表只删除元数据。默认创建的是内部表。
内部表: 平时用来测试或者少量数据,并且自己可以随时修改删除数据。
外部表:使用后数据不想被删除的情况使用外部表(推荐使用),整个数据仓库的最底层的表一般都是使用外部表
2、外部表的创建:外部表需要使用关键字"external"
10、Hive的表分区:
我们在建表的时候,可以将整张表存放在不同的目录中,这个目录就叫分区(按年、按省份等等)
避免查询的时候Hive做全目录扫描,提高查询效率。分区的本质其实就是创建目录
partitioned by 按……分区
分区分为静态分区和动态分区,静态分区是手动指定,而动态分区是通过数据来进行判断

分区操作:
分区查询:select * from part1 dt = '2020-05-05' //只会查询2020-05-05 分区的数据
查询所有分区: show partitions tableName
删除分区: alter table part3 drop partition(year='2020',month='05',day='07');

11、创建普通表 :(即没有分区,没有分桶)
create table tableName(
id int,
name string,
emp_date map<string,date>
)
partitioned by (dt string)
row format delimited -- 分隔符的写法
fields terminated by '\t' -- \t作为一个分隔
map keys terminated by ':'; --map类型 的分隔符12、分桶表:
单个分区中数据量越来越大,当分区不能更细粒度划分数据时,采用分桶技术将数据更细力度的划分和管理 (表A的每个桶就可以和表B对应的桶直接join,而不用全表join )
13、抽样查询:
select * from emp order by rand() limit 10; --随机抽样(rand()函数)
select * from emp tablesample(10 percent) --10% tablesample()函数
SELECT * FROM emp TABLESAMPLE(10 ROWS);八、元数据
1、元数据管理的作用:
1、做数据补偿,比如数据库里面的元数据存储的不全,可以再元数据管理节点里面去补充
(但是补偿的数据不会回写到库里面,不能操作客户的库,只是我们自己存储了)
2、我修改了一个字段的类型,但是我也不知道会不会影响下游,可以基于元数据去做血缘追溯,以免影响下游业务
3、一个企业有几百万张表,可以通过元数据去做检索
4、定版元数据会记录每一个元数据的信息,会记录版本号,谁什么时候修改了,我们都能追溯
2、元数据管理着哪些信息:
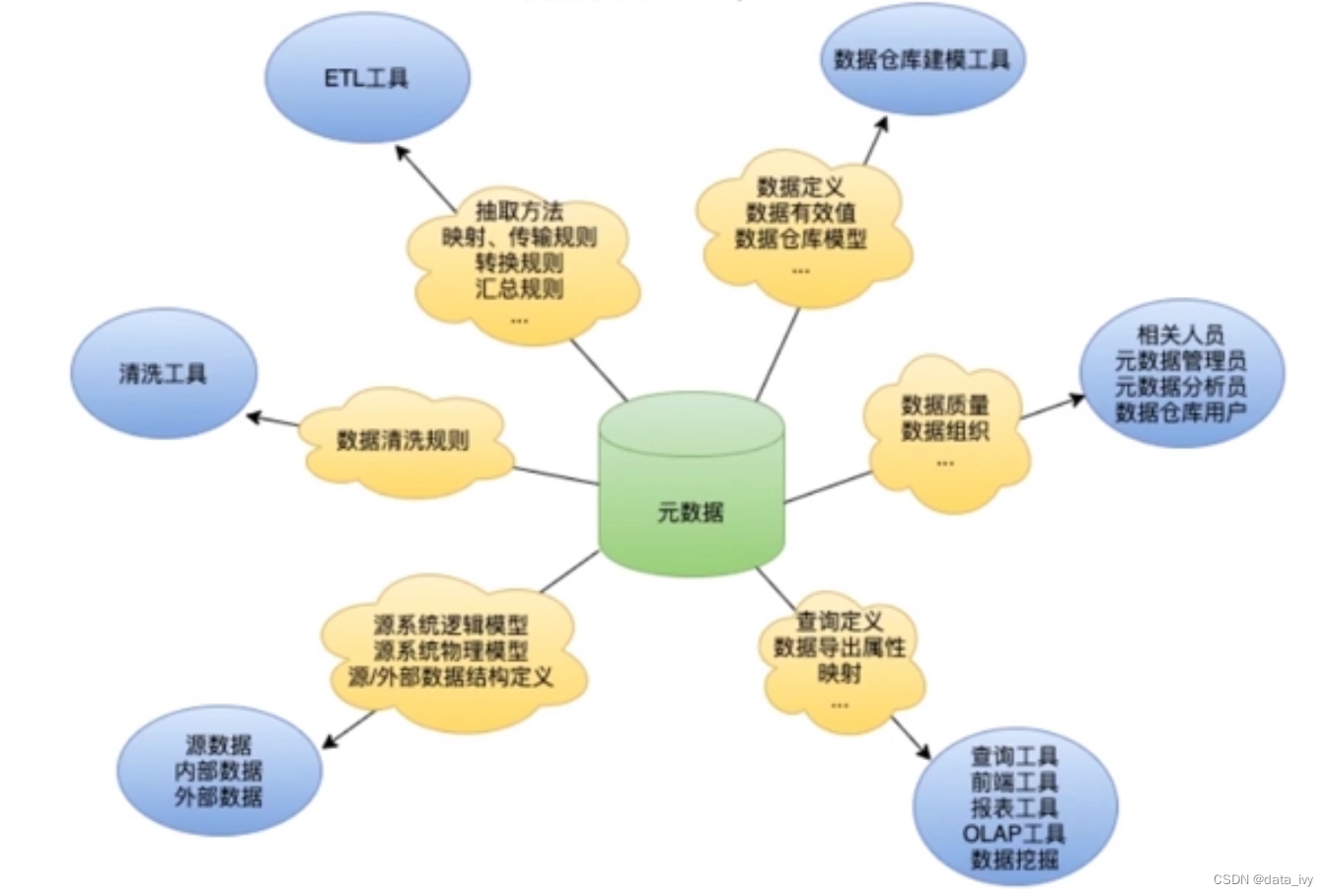
数仓中的元数据,主要记录着主题的定义、不同层级间的映射关系、监控数据仓库的数据状态及 ETL 的任务运行状态。一般会通过元数据资料库来统一地存储和管理元数据,其主要目的是使数据仓库的设计、部署、操作和管理能达成协同和一致。
3、为什么数仓要进行元数据管理?
- 建设数据仓库所必须
数据仓库是由外部数据、业务数据以及文档资料通过某些 ETL 工具得到的,如果没有一个明确、清晰的规则,根本不可能实现这个过程。
- 帮助快速理解数仓系统
一方面,数据仓库本质上是一个部门甚至一个公司的重要项目,开发时间冗长。中间不可避免的会产生人员流动,如果没有清楚的元数据,那会对整个系统乃和整个项目造成重大影响;
另一方面,数据仓库做为整个部门、公司的分析数据出口,并不仅仅对数据人员服务。DM 层对业务人员, DIM 对其他开发人员都是不可避免的。如果有清楚的元数据来说明数仓系统,就会节约双方大量的沟通时间。
- 高效精准沟通
元数据中的管理元数据会记录不同用户、角色、部门的数据权限。如果有数据需要进行通知,则可以快速查询系统进行群发邮件等方式进行沟通,从而避免了沟通环节过多造成的缺人和多人情况发生。
另一方面,在与产品、业务、研发沟通接口时,可以根据业务元数据,确认彼此沟通的指标、维度含义。从而在根源上避免交流的歧义。提高沟通效率。
- 保证数据质量
理想的元数据做到了对数据仓库结构的描述,仓库模式视图,维,度量,层次结构,到处数据库的定义,以及数据集市的位置和内容。
因此,我们可以很确定的判断哪些数据是肯定准确无误的、哪些数据是可能有问题的、哪些数据是肯定有问题的。
简单的说就是每一个字段都应该有它的取值范围、业务定义等信息,元数据定义好了自然就可以应用到数据质量检测、评估等方面,进而通过数据质量管理流程真正提高企业的数据质量。
- 快速分析变更影响
因元数据被集中维护并管理引用关系,当发生变更时,可以通过元数据管理系统以实时分析出其所影响的业务功能、应用系统、涉及人员、是否涉及监管等影响信息。
- 为未来做好准备
大数据、人工智能、数据湖、数据中台、商业智能等企业的战略级应用系统能够依赖良好的元数据管理而发挥出其应有的效果。
4、元数据的组成类型:
元数据贯穿整个数据仓库,可以分为三种:业务元数据、技术元数据、管理元数据。
①:业务元数据:
主要描述 ”数据”背后的业务含义,包括业务术语和业务规则。
- 主题定义:每段 ETL、表背后的归属业务主题。
- 业务描述:每段代码实现的具体业务逻辑。
- 标准指标:类似于 BI 中的语义层、数仓中的一致性事实;将分析中的指标进行规范化。
- 标准维度:同标准指标,对分析的各维度定义实现规范化、标准化。
业务元数据,在实际业务中,需要不断的进行维护且与业务方进行沟通确认。
②:技术元数据:指技术细节相关的概念和规则,包括对数据结构、数据处理方面的描述。以及数据仓库、ETL等信息
技术元数据
- 数据源元数据: 数据源的 IP、端口、数据库类型;数据获取的方式;数据存储的结构;
- ETL元数据:根据 ETL 目的的不同,可以分为两类:数据清洗元数据;数据处理元数据。
数据清洗元数据:数据清洗,主要目的是为了解决掉脏数据及规范数据格式。因此此处元数据主要为:各表各列的"正确"数据规则;默认数据类型的"正确"规则。
数据处理元数据:数据处理,例如常见的表输入表输出;非结构化数据结构化;特殊字段的拆分等。源数据到数仓、数据集市层的各类规则。比如内容、清理、数据刷新规则。
- 数据仓库元数据:
数据仓库结构的描述,包括数据仓库模式、视图、维、层次结构及数据集市的位置和内容;业务系统、数据仓库和数据集市的体系结构和模式等。
- BI 元数据:
汇总用的算法、包括各类度量和维度定义算法。数据粒度、聚集、汇总、预定义的查询与报告。
③:管理元数据:
包括管理流程、人员组织、角色职责等。
5、元数据的应用场景
1、影响分析
在开发中,我们经常会遇到以下问题:如果我要改动某个表、ETL,会造成怎样的影响?
如果没有元数据,那我们可能需要遍历所有的脚本、数据。才能得到想要的答案;而如果有成熟的元数据管理,那我们就可以直接得到答案,节省大量时间。
2、血缘分析
血缘分析是一种技术手段,用于对数据处理过程的全面追踪,从而找到某个数据对象为起点的所有相关元数据对象以及这些元数据对象的关系。此处的关系特指的是这些元数据对象的数据流输入输出关系。
在元数据管理系统成型后,我们便可以通过血缘分析来对数据仓库中的数据健康、数据分布、集中度、数据热度等进行分析。
3、ETL 自动化管理
在数仓中,很大一部分 ETL 都是枯燥重复的步骤。
例如:源系统——ODS 层:表输入——表输出。
又比如 ODS——DW:SQL 输入——数据清洗——数据处理——表输出。
以上的规则其实就属于一部分元数据。那理论上完全可以实现,写好固定脚本,然后通过前端选择——或 api 接口。进而对重复的 ETL 实现自动化管理,降低 ETL 开发的时间成本。
4、数据质量管理
数据清洗的逻辑,简单的说可以分为不同的数据类型和指定的特殊处理列。
我们只需指定不同数据类型的默认清洗规则,和部分特殊列的特殊处理逻辑,即可实现智能快捷的数据清洗。数据质量管理,属于 数据治理 与 元数据管理 交集,更偏向数据治理方面。
5、数据安全管理
在数据中台中,一切数据接口指标,都会从数据仓库中出口。因此理论上,我们只需在此处的元数据中对管理元数据的权限进行配置,即可实现全公司的数据安全管理。
九、埋点
1、埋点作用:
帮助业务人员来分析业务的用户使用情况,是后续进行业务分析、数据挖掘的基础
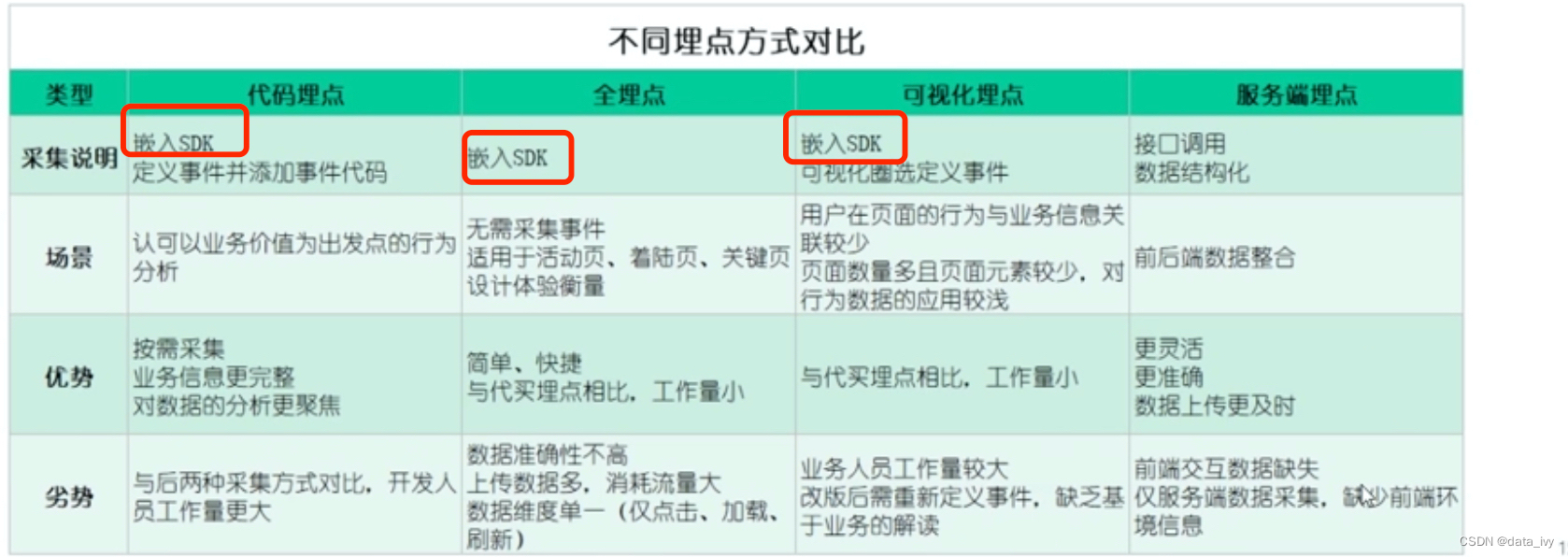
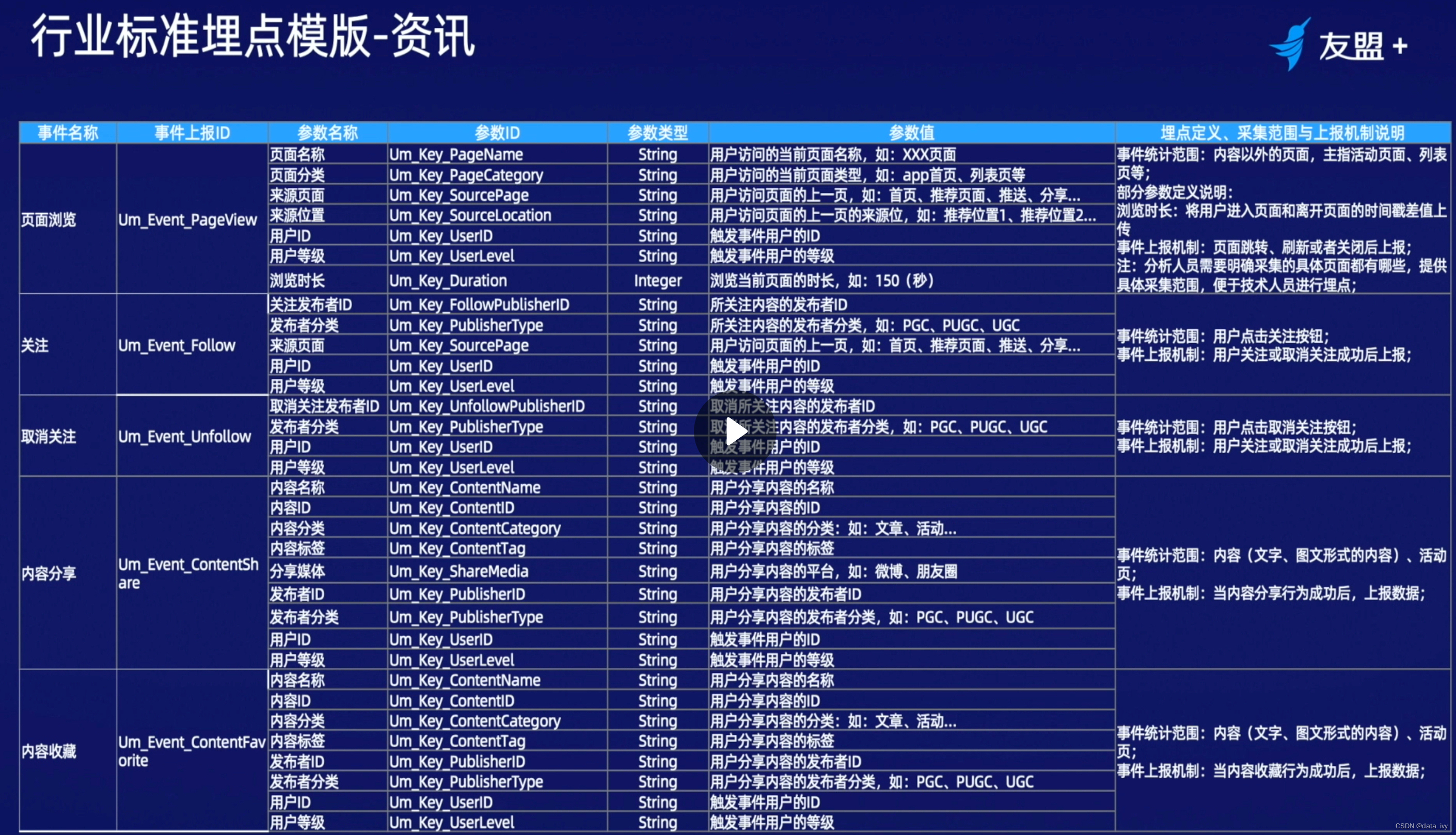
2、埋点方式( 数据采集方式 ):
①:SDK全埋点(也叫无埋点和第三方公司合作) ②:前后端代码埋点 ③:可视化埋点
1、SDK全埋点:
概述:与第三方合作,三方公司会提供SDK,前端完成SDK的引入,就可以在第三方公司的后台查看数据
优点:无需开发,部署简单,省事;
缺点:只做了最基础的页面和按钮埋点,不能采集到产品线的业务数据(例如要分析转化率就不行,缺失交易额)
2、代码埋点:(代码埋点是在全埋点的基础上进行的—在基础代码的基础上还要添加事件代码)
概述:
市场有很多开源的数据采集软件,这些软件不但能节约开发成本,另一方面用统一采集标准,有利于后期数处理。市场还有开源的SDK,可以把公共字段(手机型号、省市区、时间等)封装到SDK当中,剩下的前端再做少量的开发,比较省力。 有的只能后端埋点,比如用户“加入购物车”以后,隔几天才会下单,当几天后用户从购物车直接下单时,很难通过前端埋点去判断这个商品到底是从哪里加购的,这种只能后端埋点。当用户加购时后端可以将来源信息记录到数据库,当用户下单时,将商品来源信息取出来放入订单中。
优点:埋点灵活,可设置自定义属性、自定义事件;
缺点:开发繁琐,工作量大,前端埋点需要客户更新;(及时性不好)
3、可视化埋点:(也是是在全埋点的基础上进行的—可视化圈选定义事件)
概述:可视化埋点依赖前端,可视化埋点解决了这个问题,可视化埋点是让产品、运营人员通过可视化页面的配置,自定完成页面和按钮的埋点配置。可视化埋点有很多成熟开源的SDK,只需要前端将可视化配置的SDK进行导入即可。只需要提供可视化埋点的SDK给各条产品线,并且定义好哪些页面和按钮是需要埋点的即可。
优点:进一步降低了埋点的开发成本。
缺点:和“全埋点”一样同样也是只做了最基础的页面和按钮埋点,不能采集到产品线的业务数据
十、Python的基本语法
1、安装下载:
Python下载:https://www.python.org/downloads/
Python编辑器pycharm下载:https://www.jetbrains.com/pycharm/
2、基本语法:
①:变量:
money = 50 print(money) # 50
money = money - 10 print(money) # 40
a = b = c = 1 # 都是1
a,b,c = 1 #定义三个变量
a,b = b,a # 变量值交换
del a # 删除变量(销毁)②:数据类型: str、int、float、bool、list、tuple、set、dict、None
print(type('黑马')) # <class 'str'> 字符串
print(type(666)) # <class 'int'> 整数,不带小数点
print(type(11.2)) # <class 'float'>浮点数,带小数点
print(type(7>5)) #<class 'bool'> 布尔值
a = [] print(type(a)) # <class 'list'>
b=() print(type(b)) # <class 'tuple'> 和list 差不多的元组
my_set = {'a','b','c','a'} print(type(my_set)) # <class 'set'>
my_dist3 = dict() print(type(my_dist3)) #<class 'dict'>
a = None print(type(a)) #<class 'NoneType'> 类似于null③:类型转换:
print(float(11)) # 11.0
print(str(True)) # 'True' 字符串
print(1 + int(11.6)) # 12
print(bool(1)) # true
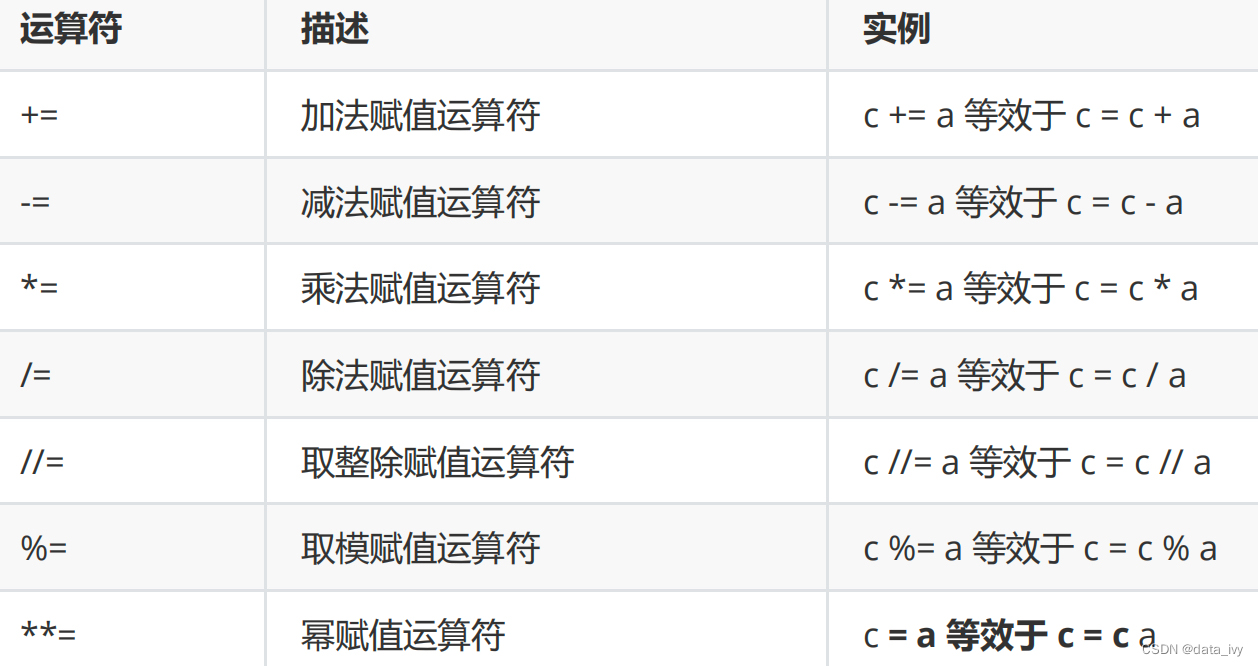
print(round(9.1)) #四舍五入 print(round(3.1415926,2)) #3.14④:赋值运算符:
⑤:if 判断:
age = 30
if 30>age>18:
print('18-30')
elif 60>age>=30:
print('30-60')
else:
print('未成年')⑥:while循环 for循环:
# while循环
lap = 0
while lap < 10:
lap += 1
print("我跑完了第" + str(lap + 1) + "圈")
# for循环
name = 'itcaseaS'
count = 0
for x in name:
if x == 'a':
count+=1
print(f"共有{count}个a") # f "{}"}
# continue # 中断本次循环,直接 进入下一次循环,进入到循环判断的地方
# break # 直接结束循环
for i in range(1,6):
print('语句1') # 打印5次语句1
continue
print('语句2') # 不执行
for i in range(1,6):
print('语句1') # 打印一次语句1
break
print('语句2') # 不执行3、字符串的操作:
①:字符串格式化:
#占位符— %d 整数、 %f 浮点数 %s字符串 %.f 指定精度的浮点数
let lap = 3
print("我跑了%d圈" % lap) #我跑了3圈
report = '%d年%s公司营收增长%2.f%%' % (2019,'腾讯',20.28)
print(report) #2019年腾讯公司营收增长20.28%
#format 函数
report = '{0}年{1}公司营收增长{2}%'.format (2019,'腾讯',20.28) #012分别代表是哪个参数
print(report) #2019年腾讯公司营收增长20%,当我们需要在字符串输出一个百分比,就需要用到%%
print("%.2f" % 3.14)
print("%.2f" % 3.1415926) #两行代码输出都是"3.14"
report = '{0}年{1}公司营收增长{2:,}元'.format (2019,'腾讯',10000000) # :,会将金额进行格式化②:字符串索引和切片:
s = 'CHINA'
s[0] #C s[-1] #A s[0:3] #CHI s[:3] #CHI 不写就是默认开头
a = "CHINA"[0:3] # CHI 等于 "CHINA"[:3]
"CHINA"[:] # 从头到尾
s[::2] #CIA 每隔两个字符取一个
print( 'asdfghyuiojkerty'[8:16:2] ) # 8-16个字符里面 每个两个字符取一个 ③:字符串函数:
s.strip() # 去除首尾空格
print( 'china'.upper() ) #变成大写
print( 'china'.lower() ) #变成小写
print( 'i have a dream'.title() ) #首字母大写
print( 'china'.startswith ('ch') ) #true #以什么…开始
a = '123' b='456123789' print(b.find(a)) #3 #find 查找该字符串的索引 等于index
b='456123789' print( b.count('1') ) # 1 #字符串出现的个数
b='456123789' print( len(b) ) #9 # 字符串长度
'abba'.replace('a','b') #bbbb #字符串替换
'apple orange'.replace('apple','orange') #orange orange #字符串替换
print("abba".count('a')) # 2 字符串一共出现了几次4、数组的操作:
①:数组示例
b = list() # 等于 b = []
c = [[1,2,3],[4,5,6]]
print(c[0]) #[1,2,3]
print(c[0][1]) # 2②:数组的内置方法
# extend append 后面追加
lis.append('h') #append 后面追加一个
lis.extend(['f','g']) #extend 追加多个
['a','b','c'].insert(2,'我被插入') #在 任意索引的位置 插入元素
list(range(num)) #得到的是从0开始,到num结束的一个数组(不含num) range(2,5,3) #2开始,5结束,步长是3
# 删除 del pop remove clear
a = ['a','b','c','d','e']
del a[1] # del 只是删除
['a','b','c','d','e'].pop() # 删除最后一位(返回被删除的元数)
['a','b','c','d','e'].remove('a') # 删除指定名称的元素
['a','b','c','d','e'].clear() #清空数组
lis.count('a') #出现的次数
lis.reverse() #反转
lis.sort(reverse = True) #从大到小排序
[('1月',56),('2月',48),('3月',62)].sort(reverse = True,key = lambda x:x[1]) #对第二项从大到小排序,key 后面接函数 x[1]是说用每个元素的第二项去排序
lis2 = lis1.copy() # copy函数 不copy 直接写 lis2 = lis1 lis1修改的话lis2也会修改

5、元组的操作:
①:定义方式
t = ('My', 'age', 'is', 18)
t[0] # 'my'
t[-1] # 18
lst = ('a', 'b', 'c', 'd', 'e')
for i in lst:
print(i)6、字典的操作:( 存储的是键值对)
①:定义方式
my_dist = {'张三':90,'王四':50,'林俊杰':80} #方法1
lis = [('Tony',123),('王四',456),('林俊杰',678)]
dict(lis) #方法2②:字典内置方法
my_dist = {'张三':90,'王四':50,'林俊杰':80}
my_dist['李四'] = 90 # 修改和增加都是这个
my_dist['张三'] #查询不到会报错 my_dist.get('张三') #查询不到不报错
my_dist.keys() #输出所有的key
my_dist.values() #输出所有的value
del sales['mike'] # 删除
score = my_dist.pop('张三') # 删除最后一位(返回被删除的元数)
my_dist.clear() # 清空
sales['mike'] = 300 # 修改
for key in my_dist:
print(key) # 返回key值
for key,value in my_dist.items():
print(key,value) # 返回每一条的元组 王四 456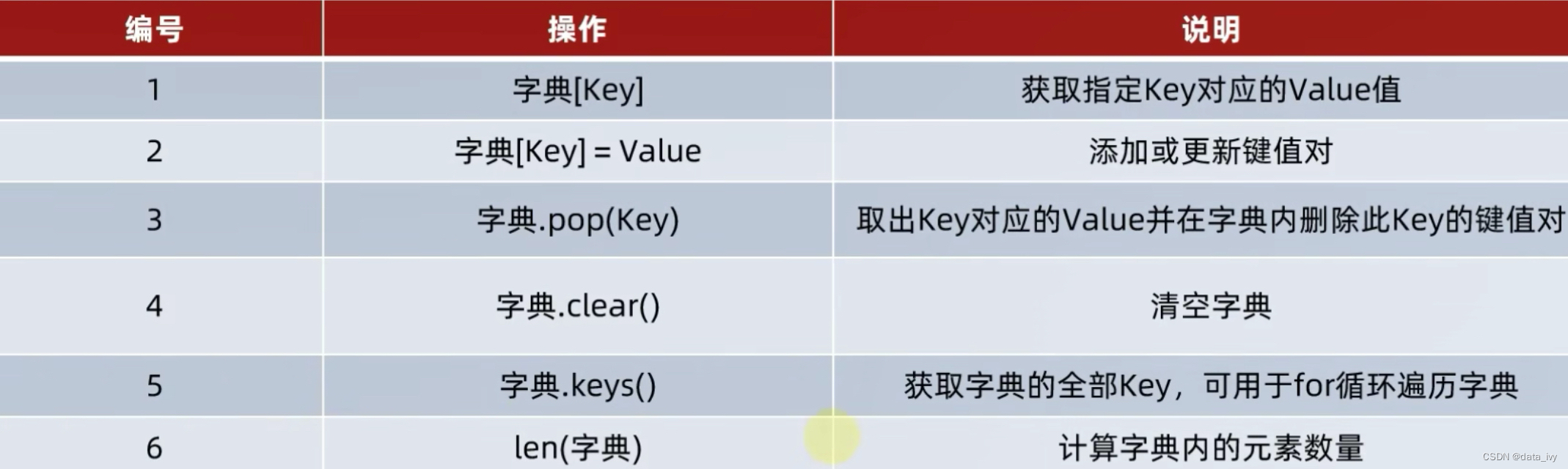
7、集合的操作(set):
用{}表示,不支持元素的重复(自带去重功能),集合是无序的,不支持下标访问
①:定义集合
my_set_empty = set() print(type(my_set)) # <class 'set'>
my_set = {'a','b','c','a'} print(my_set) # {'c', 'a', 'b'} 默认去除,返回的顺序是无序的②:集合内置方法
my_set = {'a','b','c','a'}
my_set.add('d') # add 增加 {'d', 'a', 'b', 'c'}
my_set.remove('d') # remove 删除 print(my_set) #{'a', 'c', 'b'} discard和remove一样,只是找不到不报错
print(my_set.pop()) # 删除一个(因为无序,随机删除一个)
set([1,2,3,1]) # 数组去重变成集合类型
len(my_set) #求长度
set1 = {1,2,3} set2 = {1,5,6}
set1.intersection(set2) # 求交集 {1}
set1.union(set2) # 求并集 # {1, 2, 3, 5, 6}
set1.difference(set2) # 取差集,set1里面有的,set2里面没有的 # {2, 3}
set1.issubset(set3) #true true表示set1是set3的子集
set3.issuperset(set1) #true true表示set1是set3的子集 set3是父集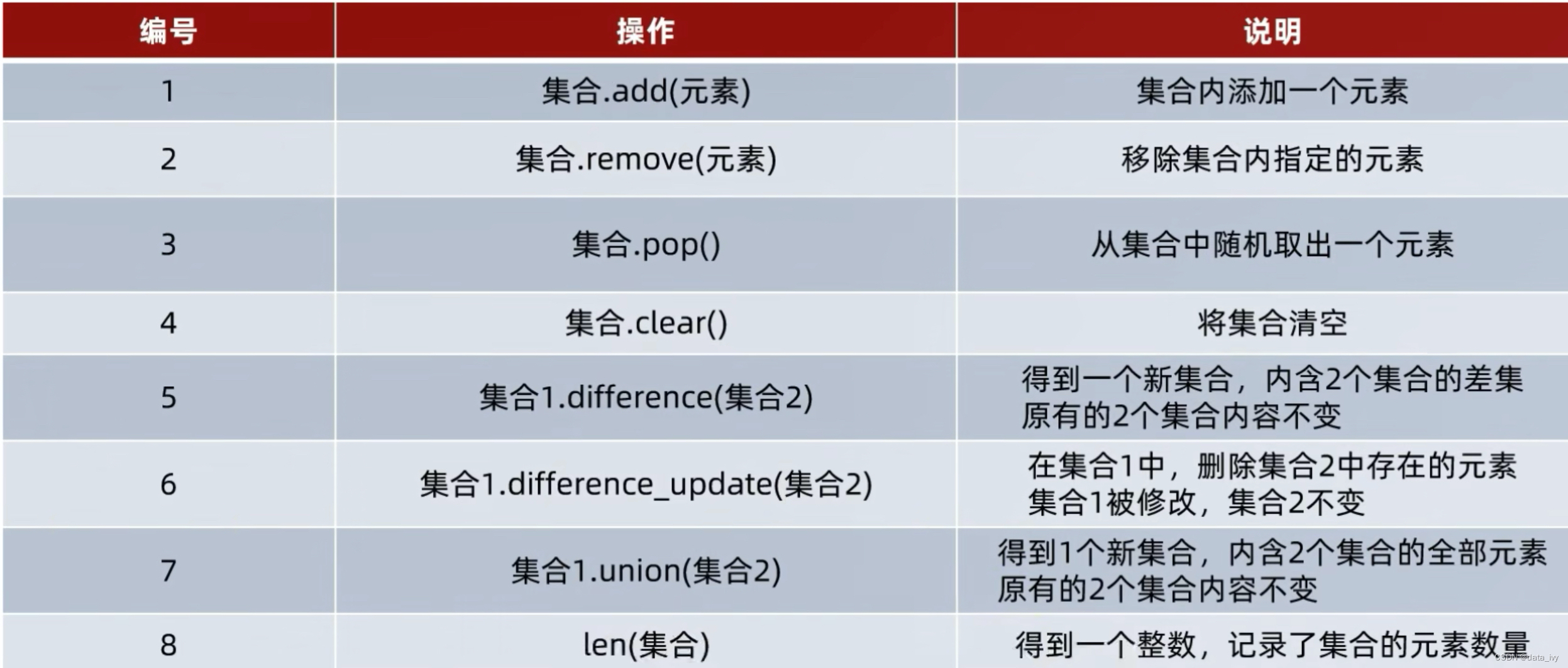
8、函数的操作:
①:定义函数
# 实名函数
def add (n,m):
return n+m
print(add(2,5)) #函数调用
def test_return (nums):
nums.sort()
return nums[0],nums[1] #最大最小值
x,y = test_return([1,6,3,2,5,9]) #接收函数返回 print(x,y)
# 匿名函数lambda
fn = lambda x,y:x+y # lambda匿名函数,:后面是函数体 ,相当于return x+y
fn(3,5) # 调用②:类、面向对象 (类是创建对象的模板分类封装, 对象是类的实例)
class Student:
name = None
gender = None
#__init__方法是构造函数,会自动执行,不用调用, 是初始化函数
def __init__(self,name,gender): # self 类函数专用,表示我的,用于获取成员变量,传参数时可以忽略
self.name = name
self.gender = gender
print(f'hi,我是{self.name}')
def eat(self):
print('我喜欢吃骨头')
stu = Student('张三','男') # 调用并传参
print(stu.name) # hi,我是张三
stu.eat(); # 我喜欢吃骨头
------------------
class Goods:
id_count = 0
#类方法 @ 符号的写法叫做装饰器 classmethod用来装饰函数定义类方法,声明了它是类方法,它的参数不再是self,而是cls,指向类本身
@classmethod
def generate_id (cls):
cls.id_count += 1 #自增长ID
return cls.id_count
def __init__(self):
self.id = self.generate_id() # 调用装饰器函数
self.name = ''
self.price = 0
self.discount = 1
g1 = Goods()
print(g1,id) 9、模块和包管理:
①:模块的导入
# 内置模块导入
import time # 相当于导入了time.py这个文件模块(内置)
time.sleep(5) # 调用:模块名.方法名() 或者 from sleep import time
from time import sleep as sp #也可以这么写 time.sp(5) # 模块名.方法名()
#自定义模块
def test(a,b): # 创建一个文件 my_model.py
print(a+b)
from my_model import test # 引用
test(1,2) # 3
__name__ 是特殊变量,会返回模块名。 如果__name__是在自己文件直接运行 返回的是"__main__" ,放在其他的文件会返回所在文件的模块名 ②:常用的内置模块:
# 日期模块 dateTime
import dateTime from xxx
nw = dateTime.now() # 返回当前时间 nw.strftime('%Y-%m-%d %H:%M:%S') 2023-03-30 18:06:01
# print(nw.year)
# nw.replace(year=2019).strftime('%Y-%m-%d %H:%M:%S') 去年的今天
# print(nw+180) 180天后的时间
dateTime.timestamp() #返回时间戳
# 时间模块 time
import time from xxx
time.time() # 也是返回时间戳
time.strftime('%Y-%m-%d %H:%M:%S') 2023-03-30 18:06:01
time.sleep(3) # 睡眠3秒
#随机数模块
import random from xxx
random.randint(1,100) #随机返回1-100的整数,包含1和10
random.random() #0-1的随机数,含0,不含1
#OS 文件操作模块
import os
os.getcwd() # 获取当前的工作目录
os.mkdir(os.getcwd()+'/test') #os.mkdir(path) 创建目录,只能创建一层目录
os.makedirs(os.getcwd()+'/abc/123') #os.makedirs(path) 创建多层目录
os.listdir('/') #返回一个列表,列出指定目录的所有文件 os.listdir( os.getcwd() )
os.path.isfile('/user/gux/xx.py') #判断文件是否存在
os.path.isdir ('/user/gux/xx.py') #判断目录是否存在10、文件的操作:
①:text、图片、csv的操作
# 打开
f = open('a.text','w') #open 是内置函数 w 等于write,默认是r read
f = open('a.text','w','a') #a 是append,默认f.write 会清空原文件内容重新写,但是加上a打开的就会在原文件后面追加了
f = with open('a.text','w') #加了with, close就不用写了
# 写信息 (会清空 原文件内容重新写),open的时候加上'a' 就是追加了
f.write('马云 1866666666\n')
f.write('马化腾 1888888888\n')
# 读取文件里面的信息 #read 预制函数
f.read()
#关闭文件
f.close()
------------CSV文件操作------------
读取方法一:
import csv
with open('./data.csv','r') as f:
reader = csv.reader(f)
for row in reader:
for col in row:
print(col,end ='\t')
读取方法二:
with open('./data_files/example1.csv', 'r') as f:
# 按⾏读取,每⼀⾏是个字典,字典的key就是每列的表头
reader = csv.DictReader(f)
for row in reader:
print(row['产品类⽬'], row['销售额'])
写入方法一:
sales = (
("Peter", (78, 70, 65)),
("John", (88, 80, 85)),
("Tony", (90, 99, 95)),
("Henry", (80, 70, 55)),
("Mike", (95, 90, 95)),
)
with open('./data_files/sales.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['name', 'Jan', 'Feb', 'Mar'])
for name, qa in sales:
writer.writerow([name, qa[0], qa[1], qa[2]]) # 等于 writer.writerow([name, *qa])
写入方法二:
# 合并数据
data = [{'name': name, 'amount': sum(qa)} for name, qa in sales]
# 先看⼀下合并后的数据
import pprint
pprint.pprint(data)
with open('./data_files/sales2.csv', 'w') as f:
fieldnames = ['name', 'amount']
writer = csv.DictWriter(f, fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)
-----------操作二进制文件----------------
f = open ('datafile/c.png','rb') #r是读取 b是二进制文件标志,表示binary
f1 = open ('datafile/c2.png','b') #w 是write
f1.write(f.read()) #把f图片复制到f1里面
f.close() f1.close()②:Excel读取
# xlrd:⽤于读取 Excel ⽂件; #xlwt:⽤于写⼊ Excel ⽂件; # xlutils:⽤于操作 Excel ⽂件的实⽤⼯具,⽐如复制、分割、筛选等;
#安装第三方Excel操作包
sudo pip install xlrd xlwt xlutil
# 读取 excel⽂件
import xlrd
wb = xlrd.open_workbook("data_files/test.xls") # open_workbook 读取Excel
# 获取 sheet 数量
print("sheet 数量:", wb.nsheets)
# 获取所有的sheets对象
sheets = wb.sheets() # print(sheets[0]) 打印出来的是sheet对象
#获取sheet的名称
print ( 'sheet名称:' wb.sheet_name() ) # ['指标1','指标2']
# 根据 sheet 索引获取 sheet
sh = wb.sheet_by_index(0) print (sh.name) # 根据索引 获取第一个sheet页的名称
# 根据 sheet 名称获取 sheet
sh = wb.sheet_names('我是sheet1页签名称') print (sh.name) # 根据名称 获取第一个sheet页的名称
# ⾏和列的读取
print("sheet %s 共 %d ⾏ %d 列" % (sh.name, sh.nrows, sh.ncols)) #xx sheet页共有7行6列
# 取整行或者整列的操作
print("第⼀⾏的值为:", sh.row_values(0)) #返回一个数组
print("第⼆列的值为:", sh.col_values(1)) #返回一个数组
# 单元格的操作
cell = sh.cell(1, 0) print("第⼆⾏第⼀列的值:", cell.value) # sh.cell_value(0, 1) 也可以这么写
# 单元格如果为日期的话,需要特殊处理
cell = sh.cell(1, 0)
if cell.ctype == 3: # ctype == 3时说明是⽇期时间格式 0是空值 1是字符串 2是数值 3是日期
value = xlrd.xldate_as_tuple(cell.value, 0) #xldate_as_tuple 参数里面一般都是写 0
print(value.strftime('%Y-%d-%m')) #对 value值的时间格式进行转换
③:EXCEL写入
import xlwt
wb = xlwt.Workbook() # 创建xls⽂件对象
sh = wb.add_sheet('第⼀季度',cell_overwrite_ok=True) #cell_overwrite_ok=True 如果不加同一个单元格只能写一次(不能修改)
sh1.write(0, 0, '姓名') # 在指定单元格写⼊数据
sh1.write(0, 1, '1⽉') # 在指定单元格写⼊数据
wb.save('./data_files/test_write.xls') # 最后,保存⽂件④:WORD 写入
pip install python-docx #安装处理word⽂档的库
import Document from docx
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT #对齐的话用这个类
from docx.shared import Mm,Inches #缩进使用 Mm毫米 Inches英寸
# 创建⽂档对象
doc = Document()
# 新增⽂档大标题
title = doc.add_heading('每⽇运营数据分析报告', 0) # 0代表标题的字号级别
# 标题居中对⻬
title.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 新增一个段落
doc.add_paragraph('此报告为Python脚本每⽇⾃动⽣成,共分为三部分:')
#创建有序列表 1、2、3这些
doc.add_paragraph('数据汇总', style='List Number') #style='List Bullet' 是无序
doc.add_paragraph('线上数据', style='List Number')
doc.add_paragraph('线下数据', style='List Number')
# 创建⼀级标题
doc.add_heading('数据汇总', 1)
#增加普通文本
online_sale = 292732
shop_sale = 1923837
graph = doc.add_paragraph('昨天⽇线上销售总额为{:,}元,线下销售额为{:,}元,总计销售⾦额为:{:,}元'.format (online_sale, shop_sale,online_sale + shop_sale))
graph.paragraph_format.left_indent = Mm(5) #缩进5毫米
# 再创建个⼀级标题
doc.add_heading('线上销售分析', 1)
# 创建段落,添加⽂档内容
paragraph = doc.add_paragraph("各渠道类型下渠道销售额分布如下")
# 段落中增加⽂字,并设置字体字号
run = paragraph.add_run('(免费渠道为292189元,付费渠道为283272元)')
# 增加图像
doc.add_picture('data_files/online_sale.png', width=Inches(5.5)) #5.5英寸
doc.add_paragraph('建议改进⽅案:')
# 创建表格
table = doc.add_table(rows=1, cols=3) #这是表格头
hdr_cells = table.rows[0].cells # 创建一行三列
hdr_cells[0].text = '城市'
hdr_cells[1].text = '销量'
# 这是表格数据
records = [['北京', '100'], ['上海', '120'], ['天津', '300'], ['河北', '200'],['⼴东', '400'], ['辽宁', '500'], ['江苏', '700'], ['湖南', '600']]
# 遍历数据并展示
for city, amount in records:
row_cells = table.add_row().cells
row_cells[0].text = city
row_cells[1].text = amount
# 设置中⽂字体
graph = doc.add_paragraph()
# 靠右对⻬
graph.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT #右对齐
graph.add_run('报告撰写⼈:').bold = True #加粗
graph.add_run('刘德华') ⑤:WORD 转PDF
pip install docx2pdf
convert('daily_report.docx', 'daily_report.pdf') #制定名称11、PIP包管理:
#安装pip
sudo easy_install pip
#包管理
pip install xxx #安装包,Mac需要加sudo: sudo pip install xxx
pip uninstall xxx #卸载 XX 包
pip install -U xxx #升级第三方包
#pip3改成pip #https://qastack.cn/programming/44455001/how-to-change-pip3-command-to-be-pip或者使用工具安装

12、异常处理:
# 功能说明
try:
# 可能发生的错误的代码
except Exception: #Exception 是所有异常的基类,可以不写
# 只有出现异常的时候才会执行
finally:
# 不管有没有报错都会执行,finally 可以省略不写,一般在这里写 close函数
#示例
try:
f = open('常见问答知识库-数据中台.xls','r')
except:
print('该文件不存在')
finally: # 可省略
print('无论如何,有没有异常我都执行')
f.close()13、爬虫示例:
①:request包 发请求
import requests #用于服务器请求
##---------- 基本使用--------------
response = requests.get('https://baidu.com') # 请求百度的服务器
print(response.status_code, response.text) # 响应状态码 和 响应内容(网页源码)
# 传参
params = {'product_id': '123', 'key': 'iphone'}
requests.get('https://item.jd.com/100008567426.html', params=params) # 也可以是post
## ---------------完整的写法---------------
headers = {
'Cookie': 'll="108288"; bid=v8-QyOSurlo',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6)'
}
url = 'https://baidu.com'
response = requests.request("GET", url, headers=headers)
if response.status_code == 200:
print("ok")
else:
print("error")②:解析HTML (beautiful soup来解析HTML)
from bs4 import BeautifulSoup #(pip install beautifulsoup4)
with open('./a.html') as f:
text = f.read()
bs = BeautifulSoup(text, 'html.parser') #html.parser 是固定写法 HTML解析器
print(bs.prettify()) # ⼯整的打印出所有HTML代码
print(bs.title.name) # title的名称
print(bs.title.text) #title的名称
print(bs.title.parent.name)# title节点的⽗节点名称
print(bs.p.parent.children)# 第⼀个p节点的⽗节点的所有⼦节点
print(bs.p['class']) # p节点的class属性
print(bs.a) # 第⼀个a标签节点
print(bs.find_all('a')) # 所有的a标签节点
print(bs.find(id='title1')) # 属性id为title1的第⼀个节点
bs.find_all('p', class_='paragraph')# 找出所有class属性为paragraph的p标签,注意class是Python中的关键字,所以在传参数时加了⼀个下划线。
print(bs.find('a')) # 第⼀个a节点
for a in bs.find_all('a'): # 找出所有的a节点,并打印他们的⽂本
print(a.text)
print(bs.get_text())# 获取⽂档内所有⽂字内容十一、Jupyter、NumPy
1、数据分析三剑客:
numpy:用来做多维数组的运算的,做一些数据运算的工作。
pandas:用来处理表格和复杂数据的,我主要用它在数据清洗这一步。
matplotlib:用来数据可视化
2、Jupyter、NumPy概述:
Jupyter概述:是一个开发工具,提供了UI界面,写代码可以在这写,启动jupyter,浏览器界面自动打开
NumPy概述:NumPy针对数组运算提供⼤量的数学函数库,包括数学、逻辑、形状操作、排序、选择、等等,可用于数据的各类清洗处理。
安装:
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple #-i https://pypi.tuna.tsinghua.edu.cn/simple 是清华的源
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
#报错的话参考,vim ~/.zshrc 按i进入编辑,退出 :wq
#https://www.jianshu.com/p/bdf6115339da 查看 Jupyter
# 安装 jupyter扩展插件,可用过这个插件更好的查看分组管理Jupyter
pip install jupyter_contrib_nbextensions -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jupyter_nbextensions_configurator -i https://pypi.tuna.tsinghua.edu.cn/simple
# 配置插件 复制粘贴到命令行
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user3、Jupyter的基本使用:
#启动 NumPy
jupyter notebook # 启动jupyter,浏览器界面自动打开
import numpy as np
# 创建数组:
-- 方法一
l = [1,3,5,7,9] # 列表
arr = np.array(l) # 将列表转换为NumPy数组
print(arr) #[1 3 5 7 9]
display(arr) # array([1, 3, 5, 7, 9]) NumPy数组的⽅法,功能更加强⼤ 等于 print
-- 方法二
nd2 = np.zeros(shape =(3,4),dtype = np.int16) #shape =(3,4) 3行4列 dtype数据的类型
arr3 = np.full(shape = [3,2,5], fill_value=3.1415926) # 创建 2行5列的3维数据,fill_value默认值
-- 其他方法
arr2 = np.full(shape = [2,3],fill_value=2.718) # 两行三列都填充成2.718
arr3 = np.arange(start = 0,stop = 20,step = 2) # 等差数列 在给定间隔内返回均匀间隔的值
arr4 = np.random.randint(0,100,size = 10) # 0-100 的随机数,size 生成的个数
arr5 = np.random.rand(3,5) #生成3行5列 0-1之间的随机数
arr6 = np.random.randn(3,5) # 生成3行5列的数据 正态分布,平均值是0,标准差是1
#如果要存多个数组,要是⽤savez⽅法,保存时以key-value形式保存,key任意(xarr、yarr)
np.savez("some_array.npz",xarr = x,yarr=y)
# 文件读写
x = np.random.randn(5)
y = np.arange(0,10,1)
np.save("./data",x) #save 把一个数据存到文件中(默认后缀保存成 npy)
np.load('./data.npy') # 把data.npy数据加载到文件里面
np.savez("./data.npz",x,y) #savez 把多个数据存到文件中,文件必须得是npz
data = np.load('./data.npz') # 把data.npz 数据加载到文件里面 (data默认是一个对象)
data['x'] #取对象里面的x数据
np.savez_compressed ("./data2.npz",x,y) # savez_compressed 方法可以压缩文件数据
np.load('./data2.npy') ['x']
np.savetxt(fname = "./data.txt",x = nd1 , fmt ='0.2f' delimiter=',') # ⽂件保存成txt,fmt是数据格式,nd1是数据,delimiter 分隔符
# NumPy的数据类型
int: int8、uint8、int16、int32、int64 #int 8 2**8(-128—127有数据)
float: float16、float32、float64
str
np.array([1,2,5,8,2],dtype = 'float32') # 输出 :array([1., 2., 5., 8., 2.], dtype=float32)
--- 改变数据类型
arr = np.random.randint(0,10,size = 5,dtype = 'int16') # 输出:array([6, 6, 6, 6, 3], dtype=int16)
--- 使⽤astype进⾏转换
arr.astype('float32') # 输出:array([1., 4., 0., 6., 6.], dtype=float32)
# 数据运算
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([2,3,1,5,9])
arr1 - arr2 # 减法
arr1 * arr2 # 乘法
arr1 / arr2 # 除法
arr1**arr2 # ** 幂运算
arr1 +=5 #所有的数据都加5
np.power(2,3) # 8 2的3此幂
#浅拷贝 深拷贝
b = a.view() # 或者b = a浅拷贝,a变化b也比我,是一体的
b = a.copy() # 深拷贝
# NumPy的索引和切片截取
-- 索引:
arr = np.random.randint(0,30,size=10)
arr[0] #取一个索引
arr[[1,3,5]] #取多个索引的值 [5,7,11]
-- 一维数组截取:【 )左闭右开
arr = np.array(0,1,2,3,4,5,6,7,8,9)
arr[5:8] #切⽚输出:array([5, 6, 7])
arr[2::2] # 从索引2开始每两个中取⼀个 输出 array([2, 4, 6, 8])
arr[::3] # 不写索引 默认从0开始,每3个中取⼀个 输出为 array([0, 3, 6, 9])
arr[1:7:2] # 从索引1开始到索引7结束,左闭右开,每2个数中取⼀个 输出 array([1, 3, 5])
arr[::-1] # 倒序 输出 array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
--⼆维数组截取
arr2d = np.array([[1,3,5],[2,4,6],[-2,-7,-9],[6,6,6]]) # ⼆维数组 shape(3,4)
arr2d[0,-1] #索引 等于arr2d[0][-1] 输出 5 第1行索引是0,最后一列索引是-1
arr2d[0,2] #索引 输出 5
arr2d[:2,-2:] #切⽚ 第⼀维和第⼆维都进⾏切⽚ 等于arr2d[:2][:,1:]
arr2d[3,[2,5,6]] #第四行数据,取索引是2,5,6 的值
arr2d[2:7,1::3] #行 从索引2到索引7—左闭右开, 列:从1开始,每三个去取一个数字
# NumPy的形状操作
-- 数组变形
arr1 = np.random.randint(0,10,size = (3,5))
arr1.reshape (5,3) #三行五列变成五行三列
-- 数组转置 (行列转换!!)
arr1 = np.random.randint(0,10,size = (3,5)) # shape(3,5)
arr1.T # 等于np.transpose(arr1,(1,0)) 行列转置!!T transpose的简写 从3行5列变成了5行3列了,但是这个和 数组变形是有区别的,这个是真正的行列转换
-- 数组堆叠
arr1 = np.array([[1,2,3]])
arr2 = np.array([[4,5,6]])
np.concatenate([arr1,arr2],axis = 0) # axis轴的意思0是横向追加,1是纵向追加
-- 数组拆分 split切片
arr= np.ranndom.randint(0,100,size=(15,10)) #15行10列
np.split(arr,indices_or_sections=3) # 平均分成3份,拆分成了3个 5行10列
np.split(arr,indices_or_sections=2,axis = 1) # ,axis = 1 表示你列,平均分成2份,2个 15行5列
np.split(arr,indices_or_sections=[1,5,9]) # 索引1切一刀,5切一刀,9切一刀
np.vsplit(arr,indices_or_sections=3) # 竖直方向分割成3份
np.hsplit(arr,indices_or_sections=[1,4]) # h是水平。 在⽔平⽅向,在索引1,4切两刀
#广播机制 当两个数组的形状并不相同,但是依旧能够实现相加、相减、相乘等操作,这种机制叫做⼴播
--示例见截图
arr1 = np.array([0,1,2,3]*3)
arr1.sort() # 排序,从小到大
arr1 = arr1.reshape(4,3)
arr2 = np.array([1,2,3])
arr1+arr2 # 他们两个 形状不对应,但是依旧能够计算,这是广播机制
#矩阵的乘积(线性代数) A的行 乘以 B的列
A = np.array([[4,2,3],[1,3,1]]) # shape(2,3)
B = np.array([[2,7],[-5,-7],[9,3]]) # shape(3,2)
np.dot(A,B) # A矩阵行长度必须和B列的长度⼀致,不然会报错 dot 矩阵乘法,点乘 等于 A.dot(B)
A @ B # 符号 @ 表示矩阵乘积运算横向广播:

纵向广播:

4、NumPy常用函数
# abs、sqrt、square、exp、log、sin、cos、tan,maxinmum、minimum、all、any、inner、clip、round、trace、ceil
arr1 = np.array([1,4,8,9,16,25])
np.sqrt(arr1) # 开平⽅
np.square(arr1) # 平⽅
np.clip(arr1,2,16) # 输出 array([ 2, 4, 8, 9, 16, 16])
x = np.array([1,5,2,9,3,6,8])
y = np.array([2,4,3,7,1,9,0])
np.maximum(x,y) # 返回两个数组中的⽐较⼤的值
arr2 = np.random.randint(0,10,size = (5,5))
np.inner(arr2[0],arr2) #返回⼀维数组向量内积
#min、max、mean、median、sum、std、var、cumsum、cumprod、argmin、argmax、argwhere、cov、corrcoef
arr1 = np.array([1,7,2,19,23,0,88,11,6,11])
arr1.min() # 计算最⼩值 0
arr.sum() #求和
arr.std() #标准差
arr.var() #方差 方差的开平方就是标准差
arr1.argmax() # 计算最⼤值的那个索引
arr1.argmin() # 计算最小值的那个索引
np.argwhere(arr1 > 20) # 返回⼤于20的元素的索引
np.cumsum(arr1) # 计算累加和
np.cumprod(arr1) # 计算累乘和
np.median(arr1) #求中位数
arr2 = np.random.randint(0,10,size = (4,5))
arr2.mean(axis = 0) # 计算列的平均值
arr2.mean(axis = 1) # 计算⾏的平均值
np.cov(arr2,rowvar=True) # 协⽅差矩阵
np.corrcoef(arr2,rowvar=True) # 相关性系数
#where函数
arr1 = np.array([1,3,5,7,9])
arr2 = np.array([2,4,6,8,10])
cond = np.array([True,False,True,True,False])
np.where(cond,arr1,arr2) # True 返回arr1数据,False返回arr2的值
# 输出 array([ 1, 4, 5, 7, 10])
arr3 = np.random.randint(0,30,size = 20)
np.where(arr3 < 15,arr3,-100) # ⼩于15返回⾃身的值arr3,⼤于15统一返回成成-100
#排序⽅法
arr = np.array([9,3,11,6,17,5,4,15,1])
arr.sort() # 直接改变原数组
np.sort(arr) #不改变元数组的排序
arr = np.array([9,3,11,6,17,5,4,15,1])
arr.argsort() # 从⼩到⼤排序,然后返回的是这些排好数据的索引 array([8, 1, 6, 5, 3, 0, 2, 7, 4])十二、Pandas
1、概述:
Pandas是基于Numpy的一个库工具, 是处理数据的理想⼯具。
2、基本使用:
#安装:
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
#引包
import numpy as np
import pandas as pd # pandas基于Numpy
#Series (⼀维数据)
a = np.array([1,2,3,6,9]) #Numpy 数组
b = pd.series(data=a) #Series 一维数组,Series 和 Numpy的区别在于,Series 多了一个索引!!!
test = [0,1,7,9,np.NAN,None,1024,512]# 在pandas中都以缺失数据NaN对待
s1 = pd.Series(data = test) # pandas⾃动添加索引,默认是从1开始
s2 = pd.Series(data = test,index = list('abcdefhi'),dtype='float32') # index 指定索引的名字
a = pd.Series(data = {'A':149,'B',130,'C':118,'D':99,'E':66}) # Series的数据也可以是键值对,ABCD就是索引值
# DataFrame (二维数组) 多个Series就构成了DataFrame
# 示例:会生成5行3列的一个表格
pd.DataFrame(data = np.random.randint(0,151,size = (5,3)), #data是固定写法,5行3列
index = ['A','B','C','D','E'],# ⾏索引
columns=['Python','Math','En'])# 列索引,也是3列的字段名称
# 示例:会生成3行3列的一个表格,key 作为列索引,不指定index,默认从0开始
pd.DataFrame(data = {'python':[66,88,69],'math':[53,86,74],'en':[76,66,89]})

# pandas查看数据
df.shape # 查看数据形状,⾏数和列数(10,3)10行3列
df.head(10) # 显示前10⾏数据,默认5个
df.tail(10) # 显示后10⾏数据,默认5个
df.dtypes # 查看数据类型
df.index # ⾏索引
df.columns # 列索引
df.values # 返回的是Numpy 数组
df.describe() # 描述信息 包括: 合计、平均值、标准差、最⼩值、四分位数、最⼤值
df.info() # 查看信息 数据类型、内存多大、有多少非空数据等等
### pandas csv 读写
df = pd.DataFrame(data = np.random.randint(0,50,size = [50,5]), columns=['IT','化⼯','⽣物','教师','⼠兵'])
-- to_csv 保存到文件中
df.to_csv('./salary.csv',sep = ';', header = True,index = True)
# sep⽂本分隔符,默认是逗号 header保存列索引 index保存行索引,不报错存储的就是纯数据
-- pd.read_csv 加载文件
pd.read_csv('./salary.csv',index_col = 0 ) #index_col 把第一列数据作为行索引(默认会自己加索引)
# pandas excel读写
--安装插件
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple
df1 = pd.DataFrame(data = np.random.randint(0,50,size = [50,5]),columns=['IT','化⼯','⽣物','教师','⼠兵'])
--to_excel 保存到文件中
df1.to_excel('./salary.xls',sheet_name = 'salary',header = True,index = False) # index header 和上面一样
-- read_excel读取数据
pd.read_excel('./salary.xls',sheet_name=0,header = 0, names = list('ABCDE'),index_col=1) # index_col 把第二列数据作为行索引
# Pandas 操作SQL读写
-- 安装操作库 和 导包
pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
from sqlalchemy import create_engine
-- 数据库连接
conn = create_engine('mysql+pymysql://root:12345678@localhost/pandas?charset=utf8') #pandas是库名,charset=utf8 是参数,root:12345678 账号密码,localhost是地址
-- 将数据插入MySQL当中
df.to_sql('score',conn,if_exists='append',index = False)
# 'score',数据库中表名 conn,上面数据库连接 index默认是true,是否存行索引 if_exists 如果表名存在,追加数据
-- 查询数据
pd.read_sql('select * from score limit 10', conn)
# Pandas 数据获取
df = pd.DataFrame(data = np.random.randint(0,150,size = [150,3]),columns=['Python','Tensorflow','Keras'])
-- 获取某列数据
df[['Python'] #获取一列数据 或者df.python
df[['Python','Keras']] # 获取多列数据
-- 获取标签 (行索引)
df.loc[['A','C']] # 获取A同学和C同学的成绩, lo是location的缩写
df.loc[['A','C'],'python'] #获取A和C同学 python的成绩
-- 位置选择
df.iloc[4] # 获取索引为4的数据(行索引)
--Boolean 索引
cond = df.Python > 80 # 获取Python大于80分的数据 等于 df[cond]
cond = df.mean(axis=1)>75 #平均分大于75的数据 df[cond]
--赋值操作
df['Python']['A'] = 100 #把A同学的Python成绩改成100分
df['Java'] = np.random.randint(0,150,size =9) #新增加一列字段
df.loc[['C','D','E'],'Math'] = 120 #把CDE 三个同学的数据成绩都改成 120
# pandas 数据集成 ( 从这开始自己测测 )
-- concat 链接
pd.concat([df1,df2],axis = 0) # df1和df2⾏串联, df2的⾏追加df1⾏后⾯ 等于 df1.append(df2) # 在df1后⾯追加df2的数据,相当于union(行追加)
pd.concat([df1,df2],axis = 1) # df1和df2列串联, df2的⾏追加df1⾏后⾯ 等于 df1.append(df2) # 在df1后⾯追加df2的数据
-- 指定位置插入
df.insert(loc = 1,column='Pytorch',value=1024) # 把 Pytorch这一列都改成 1024
-- join合并
pd.merge(df1,df2, how = 'inner',on = 'name') #join连接
pd.merge(df1,df3,how = 'left', left_on = 'name',right_on = '名字') # 如果左右字段名字不一样,可分别写出来
# 数据清洗
df = pd.DataFrame(data = {'color':['red','blue','red','green','blue',None,'red'],'price':[10,20,10,15,20,0,np.NaN]})
-- 重复数据过滤
df.duplicated() # 判断是否存在重复数据 返回的是true或者false
df.drop_duplicates() # 删除重复数据, 整行删除
-- 空数据过滤
df.isnull() # 判断是否存在空数据,存在返回True,否则返回False
df.dropna(how = 'any') # 删除空数据
df.fillna(value=1111) # 填充空数据
-- 指定⾏或者列删除
df.drop(labels = ['price'],axis = 1) # 直接删除某列 等于 del df['price'] # 直接删除某列
df.drop(labels = [0,1,5],axis = 0) # 删除指定⾏
-- 函数filter使⽤
df = pd.DataFrame(np.array(([3,7,1], [2, 8, 256])),index=['dog', 'cat'],columns=['China', 'America', 'France'])
df.filter(items=['China', 'France'])
df.filter(regex='a$', axis=1)# 根据正则表达式删选列标签
df.filter(like='og', axis=0)# 选择⾏中包含og
-- 正态分布的数据
df2 = pd.DataFrame(data = np.random.randn(10000,3)) # 创建一个正态分布的数据
# 数据转换
-- 重命名行和列的名称
df.rename(index = {'A':'AA','B':'BB'},columns = {'Python':'⼈⼯智能'})
-- 替换值
df.replace(3,1024) #将3替换为1024
df.replace([0,7],2048) # 将0和7替换为2048
df.replace({'Python':2},-1024) # 将Python这⼀列中等于2的,替换为-1024
# 数据重塑
-- 行列转置
df.T
-- 多层索引把指定的⾏旋转成列
df2 = pd.DataFrame(data = np.random.randint(0,100,size = (20,3)),index = pd.MultiIndex.from_product([list('ABCDEFHIJK'),['期中','期末']]), columns=['Python','Tensorflow','Keras'])
df2.unstack(level = -1)
-- 多层索引DataFrame数学计算
df2.mean() # 各学科平均分
df2.mean(level=0) # 各学科,每个⼈期中期末平均分
# 简单的统计指标
-- 基础指标
df.count() # ⾮NA值的数量
df.max(axis = 0) #轴0最⼤值,即每⼀列最⼤值
df.min() #默认计算轴0最⼩值
df.median() # 中位数
df.sum() # 求和
df.mean(axis = 1) #轴1平均值,即每⼀⾏的平均值
df.quantile(q = [0.2,0.4,0.8]) # 分位数
df.describe() # 查看数值型列的汇总统计,计数、平均值、标准差、最⼩值、四分位数、最⼤值
df['Python'].argmin() # 计算最⼩值位置
df['Keras'].argmax() # 最⼤值位置
df.idxmax() # 最⼤值索引标签
df.idxmin() # 最⼩值索引标签
df['Python'].value_counts() # 统计元素出现次数
df['Keras'].unique() # 去重
df.cumsum() # 累加
df.cumprod() # 累乘
df.std() # 标准差
df.var() # ⽅差
df.cummin() # 累计最⼩值
df.cummax() # 累计最⼤值
df.diff() # 计算差分
df.pct_change() # 计算百分⽐变化
-- ⾼级统计指标
df.cov() # 属性的协⽅差
df['Python'].cov(df['Keras']) # Python和Keras的协⽅差
df.corr() # 所有属性相关性系数
df.corrwith(df['Tensorflow']) # 单⼀属性相关性系数
#排序
-- 按索引 或 列名排序
df.sort_index(axis = 0,ascending=True) # 按索引排序,升序
df.sort_index(axis = 1,ascending=False) # 按列名排序,降序
--按属性值排序
df.sort_values(by = ['Python']) #按Python属性值排序
df.sort_values(by = ['Python','Keras'])#先按Python,再按Keras排序
--topN
df.nlargest(10,columns='Keras') # 根据属性Keras排序,返回最⼤10个数据
df.nsmallest(5,columns='Python') # 根据属性Python排序,返回最⼩5个数据
#分箱操作
-- 指定宽度分箱
pd.cut(df.Keras,bins = [0,60,90,120,150], right = False,labels=['不及格','中等','良好','优秀'])
df.Keras 分箱数据 bins = [0,60,90,120,150] 分箱断点 right = False 左闭右开 labels 分箱后分类
-- 等频分箱
pd.qcut(df.Python,q = 4, labels=['差','中','良','优']) # # 4等分 分箱后分类
# 分组
-- 将数字 映射成中文(维度退化)
df['sex'] = df['sex'].map({0:'男',1:'⼥'}) # 将0,1映射成男⼥
-- 单分组
g = df.groupby(by = 'sex')[['Python','Java']]
-- 多分组
df.groupby(by = ['class','sex'])[['Python']]
# map Series元素改变
# apply元素改变。既⽀持 Series,也⽀持 DataFrame
# 时间序列
十三、统计学、ABTest
1、统计分析的目的:
1、分析过去的变化规律,总结过去变化的原因
2、预测未来
2、统计值概念:
极差: 最大值—最小值
均值: 平均值
中位数: 从小到大排序,中间的那个数 ( 平均工资没意义,中位数能够更好的体现出来 )
众数: 一个数组中出现最多次数的那个值
标准差:(表示每个数值相当于平均值的离散程度) 各个数据减去平均值,然后平方,然后对各个值求和,然后再除以n,最后一起开根号。 公式可自己百度一下
ROAS:投入一块钱的广告费,能够获得多少营收(ROAS 一般大于2才算是可以)
ROI: 税前年利润/投资总额
3、两大定律
大数定律: 样本n越大,样本均值几乎必然等于均值
中心极限定律:当样本量N趋于无穷大时,N个样本的均值逐渐趋于正态分布
4、统计推断步骤:
1、抽样误差和标准误
抽样误差: # 抽一次样本,样本就不能完全代表总体,总会有误差,这个误差叫抽样误差 (抽样造成的误差)
标准误: # 样本抽样误差的统计量,用于表示抽样误差的大小 (有固定公式,自己百度)
2、选择分布方法 (t分布、正态分布) # 将整体数据,基于一定方法进行分布,来估计后面的流程
t分布只有一个参数,自由度v(简单理解成样本量) ,当自由度无穷大,t分布趋近于正态分布
3、参数估计 # 用样本的量,来推断总体参数的估计值
4、假设检验
操作思想: (小概率反证法) # 先根据我的数据提出一个假设,接下来用参数估计来验证我的假设是否成立
假设检验目的:# 判断总体与样本量的差异是哪一种原因导致的5、线性回归介绍:
概述:# 用线性方程式(如一元一次方程式Y=aⅹ+b)表示相关系数、应用于预测的方法。
示例:# 假设商品A的销售额为Y,广告播出次数为x,则 如下图 一次方程式Y=aⅹ+b a为斜率,b为截距
线性回归分类:#根据自变量个数 分为一元回归 和 多元回归 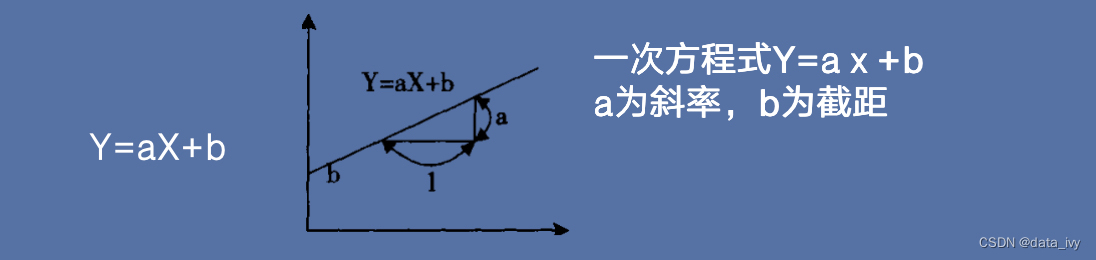
6、如何分析问题:
1、确定业务目标(从业务目标去分析,跳出问题本身)
2、将目标拆解成详细问题
3、对各问题做优先级排序(对问题的的紧急程度、投入成本等等进行综合排序)
4、制定问题解决方案 (对第三步的问题,制定解决方案)
5、搜集数据,分析重要问题 (分析数据,对方案 量化 其目标)
6、汇总研究成果,建立论据 (对方案结果进行汇总,分析方案的效果)
7、梳理论据逻辑,形成报告 (将准备的论据生成案例报告)
8、复盘 (收集各方反馈,对项目进行进一步复盘)
7、分析示例:
1、问题:9月份订单要占8月份的70%(往年都是50%)
2、流程图:
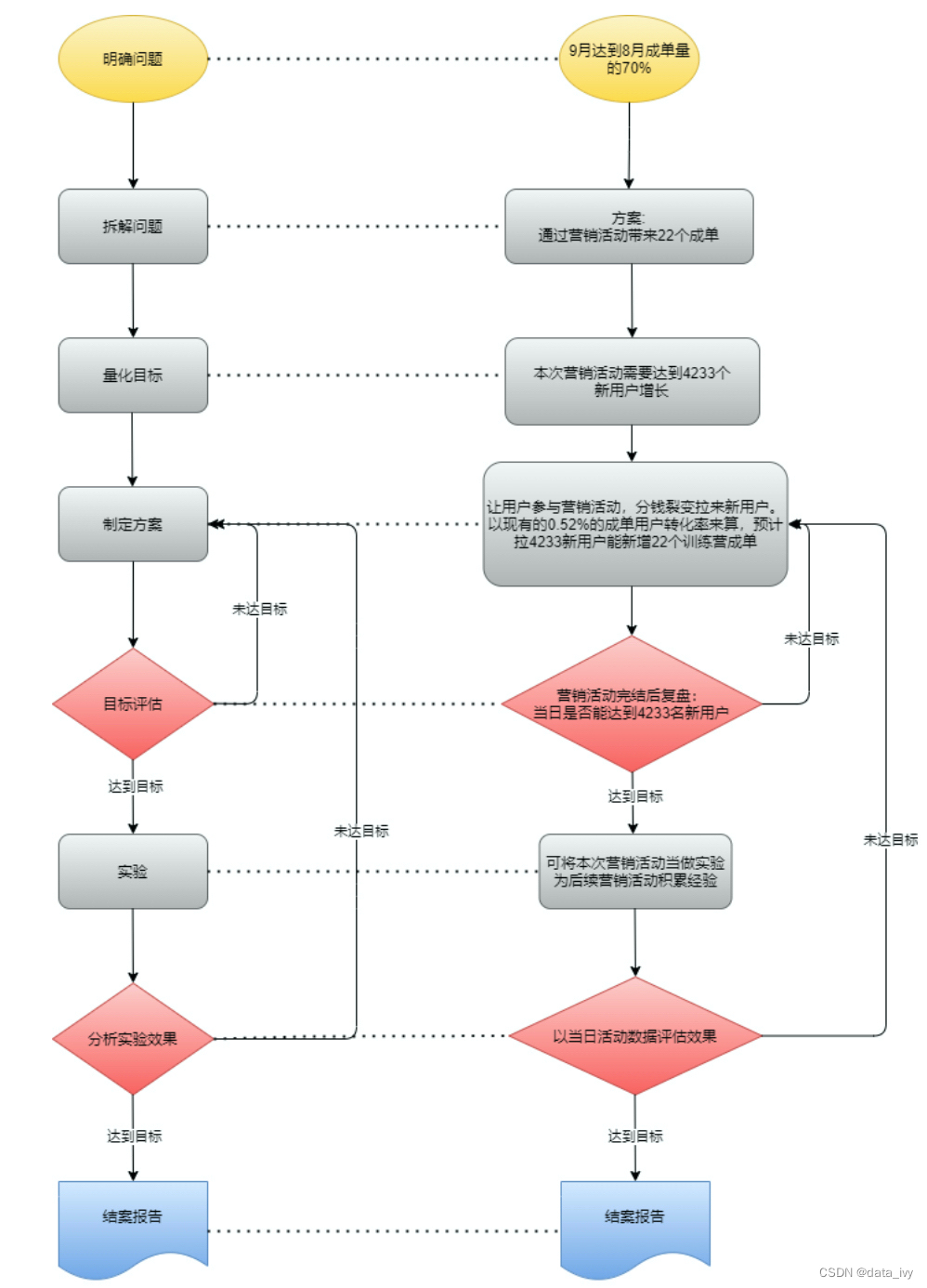
3、效果分析:(活动开始日期:9月23日)
阶段一:9月24日 汇报用户拉新情况(第二天)
汇报内容:活动新用户数、用户拉新情况(K因子)、活动支出、当日用户转化
汇报形式:简报+提前做好活动报表(活动效果直接报表呈现)
阶段二:10月1日汇报用户留存情况(第七天)
汇报内容:用户拉新&留存分析、用户转化分析
汇报形式:项目报告
阶段三:10月8日 汇报用户留存、转化(第15天)
汇报内容:用户留存、用户转化
汇报形式:简报
阶段四:10月13日 汇报项目结案报告 (第15天+5天,十一特殊再增加几天)
汇报内容:用户留存、用户转化
汇报形式:项目报告(特殊时期的结案补充)
8、什么是假设检验:
想证明一个事件 A 不成立的时候。可以先找到一件当事件 A 成立时很大程度不会发生的事件 B,当你发现事件 B 发生的时候,你就有很大把握证明A不成立。
在假设检验逻辑中,A成立一般会被我们选为“原假设” H0;A不成立,一般会被我们选择为“备择假设” H1(国外一般使用Ha)。 我们主要做的事情:当A成立时,证明B是一个小概率事件,从而证明备择假设H1成立。
H0: A事件成立 A
H1: A事件不成立
普通假设逻辑:
if A then not B (如果A成立B就不成立,反过来就是B成立的话A就不成立)
eg:如果我有钱,我就肯定不会买安卓手机。
假设检验逻辑:( 本质是反证法 )
if A then probably β not B (如果A成立,B大概率β 不成立,反过来就是B成立的话 A 大概率 β就不成立)
eg:如果我有钱,我大概率β 不会买安卓手机,当年看到我买安卓手机,我就大概率β 没有钱
9、在abtest的应用 p值的意义
p值: P,probability 的简写,概率的意思。
表示在原假设成立的情况下,统计结果证明原假设的可能性有多大。
P值越小,越能说明原假设不正确(拒绝原假设)
10、第一类和第二类错误的定义是什么?
第一类错误: 叫弃真错误,即原本假设是正确的被我们判定是错误的概率
(在ABTest中就是原假设无明显差异,但实验结果显示有明显差异)
第二类错误: 叫采伪错误,即原本是错误的被我们判定是正确的概率(在ABTest中就是原假设有明显差异,但被认为是无明显差异)
α:显著性水平 我觉得明天95%可能会下雨,α 为 0.05 = ( 1-0.95 )
一类错误:弃真错误,实际H0是真的,但是我把它拒绝了。 犯一类错误的概率为 α 。 要尽量避免第一类错误
二类错误:采伪错误,实际H0是假的,但是我没有拒绝H0。犯二类错误的概率为 β (默认是20% 0.2 )
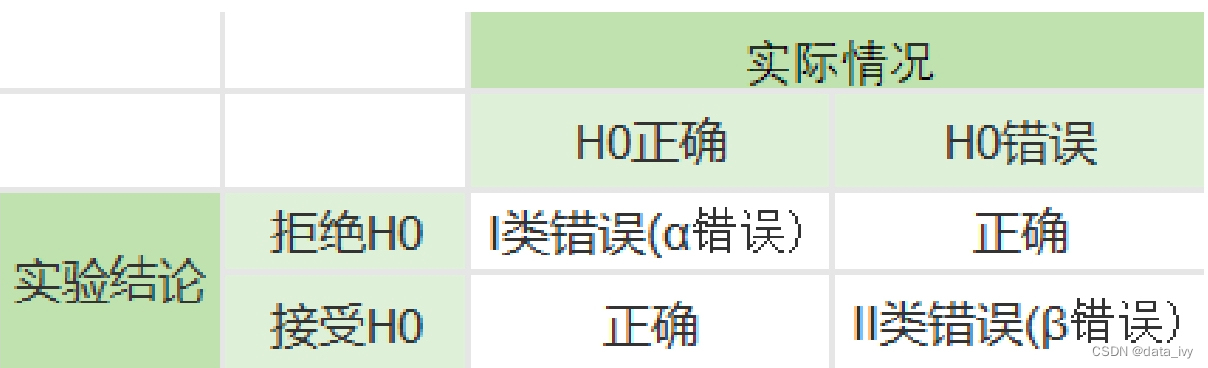
α怎么定:
犯一类错误后果越严重,显著性水平就需要定的越低
P值的计算:
方法一:根据不同的结果数据,利用正态分布来计算,由于公式比较复杂,可以借用统计工具来计算
![]()
算好以后,基于显著性水平的值可进行值域的选择(正面占比0.6,P值刚好大于α,也就是60次就是判断是不是小概率的阈值)
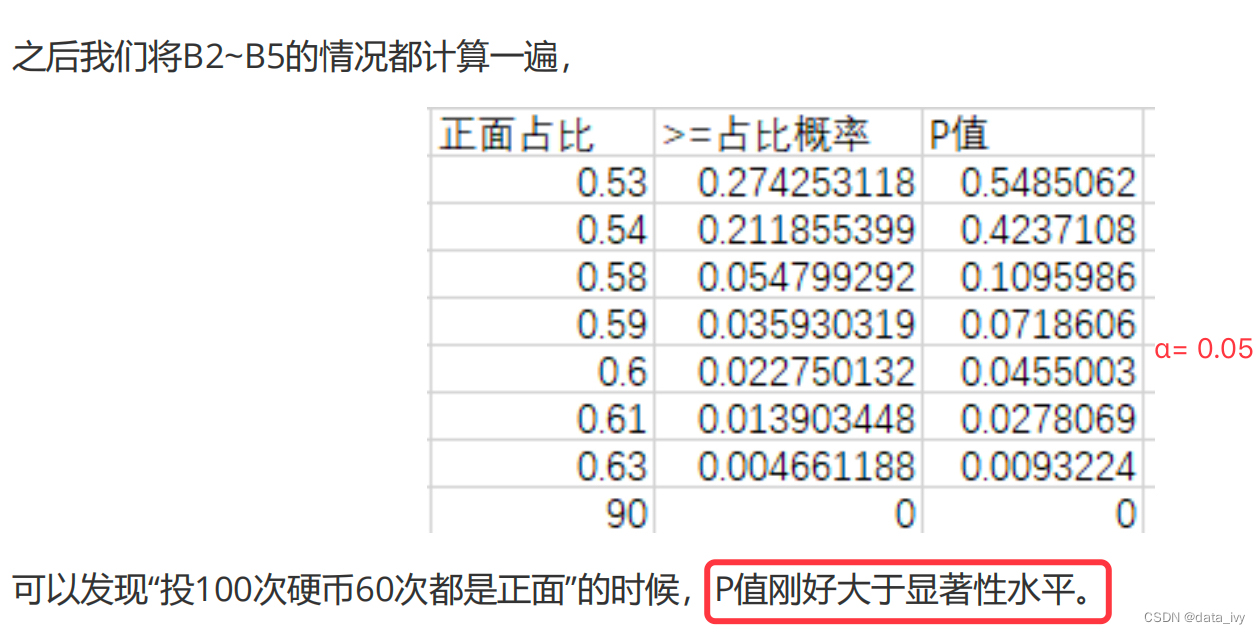
方法二: 使用Excel的函数NORM.INV(),可以直接求出显著性水平对应的阈值。(只要定出了显著性水平,做出了A成立时候的样本分布,那么就能找到小概率的阈值,P就能算出来)
这个图非常非常重要,这个会了就什么都会了

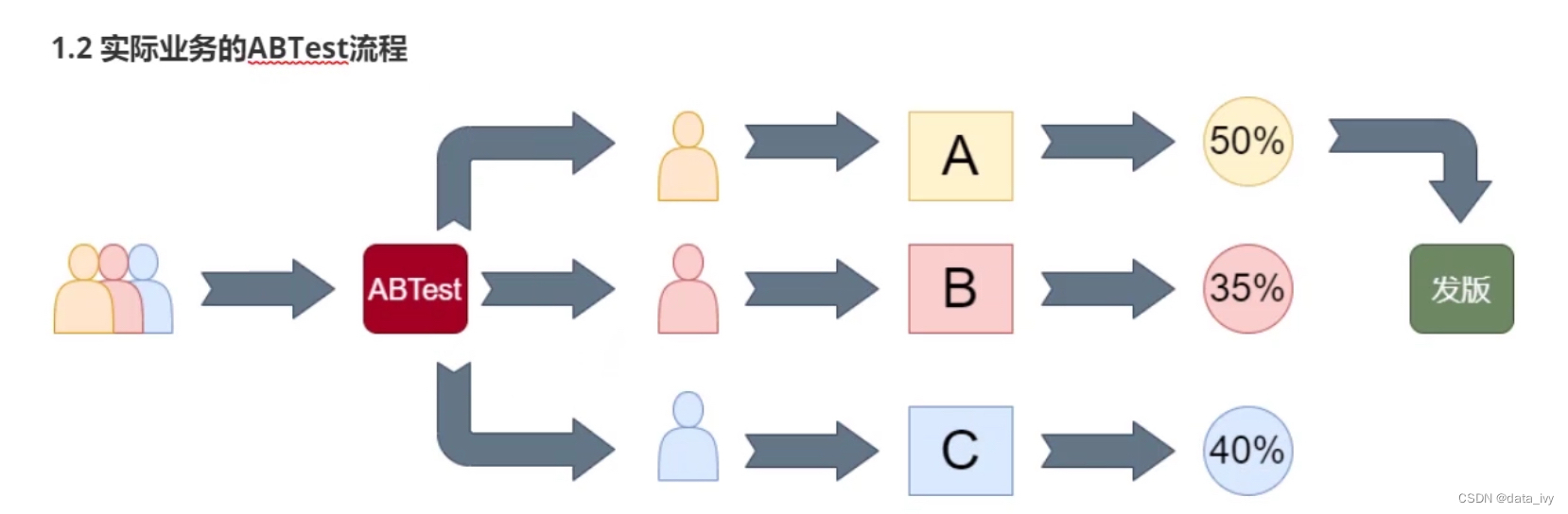
11、ABTest定义:
是对不同版本的产品特征 对比实验的方法(本质是 数据分流 + 灰度发布 )
灰度发布: 可以在不同的分流用户中上线不同的功能,可用于实验
12、ABTest的必要性:
1、风险控制(如果不能很好的预测版本,每天都会造成营收的降低,把对公司的影响讲到最小)
2、科学择优(实验验证不同产品方案的效果,收益最大化)
13、ABTest 实验的流程:
1、测试立项:设定目标,对实验方案、周期进行设计;
2、实验设计:确定指标,确定分流的策略 和 检验的策略;(分析师主导)
3、开发阶段:对不同的策略进行开发和埋点;
4、灰度测试:分配流量,执行用户分流,进入到测试;
5、数据收集:收集、存储、展示;
6、分析结果:分析每组的实验效果,选择最优方案;
7、发版推全:对最好的版本进行上线发版;

14、统计分布:Z分布、T分布、卡方分布

T分布与Z分布,都是标准正态分布,都是以0为对称的分布,T分布的方差大所以分布形态更扁平些
卡方分布是大于0的右偏分布,随着自由度的增加会趋近于正态分布(注意不是标准正态分布)

15、如何做一个好的ABTest
1、确定对照组和实验组,最好是做单变量的实验,一次只改变一个变量。
2、分流时尽量 排除混杂因素,一般情况下采用随机分流即可。如果随机分流无法保证样本分布于总体分布一致。可以采用手动的分层随机分流。
3、检查流量是否达到最小样本量要求,达不到要求则没法进行后续的分析,实验结果不可信。
4、准确收集 用户行为数据,这就要求埋点必须正确。
16、Test 的局限性:(缺点)
1、只知更优,不能知最优
2、产品版本发布后,无法增加或更改AB测试场景
3、只有现象,没有原因,不知道为什么好
4、制作AB版本的开发、数据收集的工作量较大,成本高
十四、机器学习
1、有监督学习和无监督学习:
监督学习: 有目标值。
无监督学习:没有目标值。
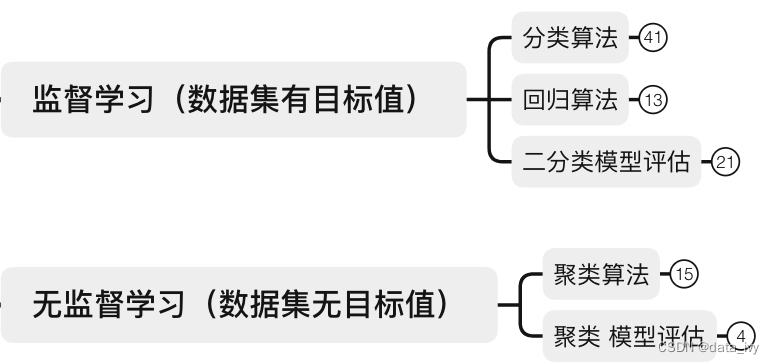
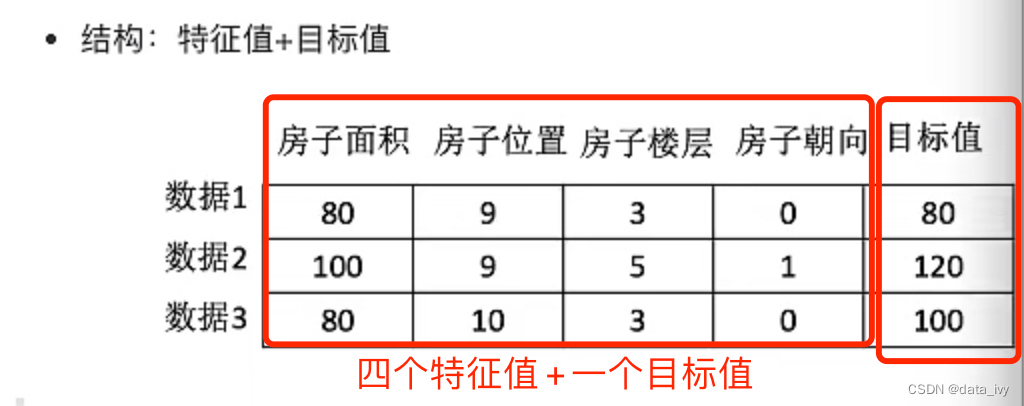
2、数据集介绍: 我们把机器学习要学习的数据称为数据集。
举例一:数据集由 特征值 + 目标值 构成 (有些数据集是没有目标值的)
举例二: 比如识别猫狗,猫狗图片就是特征值,目标值就是判断是猫还是狗
3、特征提取:
将数据(文本、图片、字符串等)转化为可用于机器学习的数字特征。(对计算有意义的都叫特征词)一般使用sklearn 来提取
4、过拟合、欠拟合:
过拟合:在训练集上表现得很好,但是在实际测试集中表现得却不好
解决方法: 加样本、减特征
欠拟合: 训练集合测试集效果都不好
解决方法: 加特征
最希望达到中间的效果:

5、归一化: (对数据进行 同等标准的缩放)
有的特征值数值很大,有的数值很小,差异化很大。 很值很小,计算的时候就显得不重要,可有可无了,这个在机器学习叫做量纲不统一,这种情况可对数据进行同等标准的缩放。
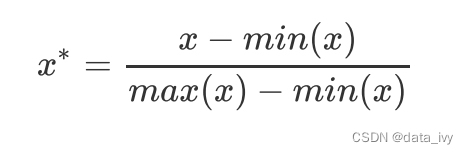
6、参数估计
用样本统计量去估计总体的参数
7、什么是正态分布:
拿小朋友班级的成绩表,每隔2分统计一下人数(小学一年级大家成绩很接近),画出钟形。然后说这就是正态分布,大多数的人都集中在中间,只有少数特别好和不够好

8、构建模型的过程:
1)获取数据
2)数据处理
3)特征工程:将数据处理成,能够被机器学习算法使用的数据结构 (所以数据集为什么叫特征值,是有原因的)
特征工程会直接影响机器学习的效果,一般使用sklearn 接口做特征工程,特征工程的接口也叫转化器
4)算法训练:数据集分成测试集(25%左右)和验证集
5)模型评估:(如果效果不好,返回2继续处理)

6)应用
9、聚类算法的模型评估指标:轮廓系数(如何衡量聚类算法的效果)
轮廓系数:通过衡量簇内的差异大小来衡量聚类的效果。 轮廓系数是固定公式,范围是(-1,1),结果越接近1越好
信息熵是不确定性的值。将原本模糊的信息概念进行计算得出精确的信息熵值
![]()
举例:
对于张三来说,小红喜欢这三个礼物的概率都是 1/3,所以此时 P(x) = 1/3,信息熵计算
H(x)=1/3*log(3)+1/3*log(3)+1/3*log(3)=1.56
当小明知道小红目前不需要口红时的信息熵为: H(x)=1/2*log(2)+1/2*log(2)=1
10、分类问题的评估方法(精确率、召回率):
①:精确率:
定义:预测结果为正例样本中,真实为正例的比例
说明:预测正确的数量占总预测样本的占比。 7个人离职,预测的是10个人离职,准确率就是 70%
②:召回率:
定义:真实为正例的样本中,预测结果为正例的比例(评估的是 对正样本的区分能力,适用于判断我查的全不全,有没有漏掉的)
示例:真正离职的人,能够被检测出来的概览。7个人离职,预测的是10个人离职,但是全部包含这7个人,那召回率就是100%
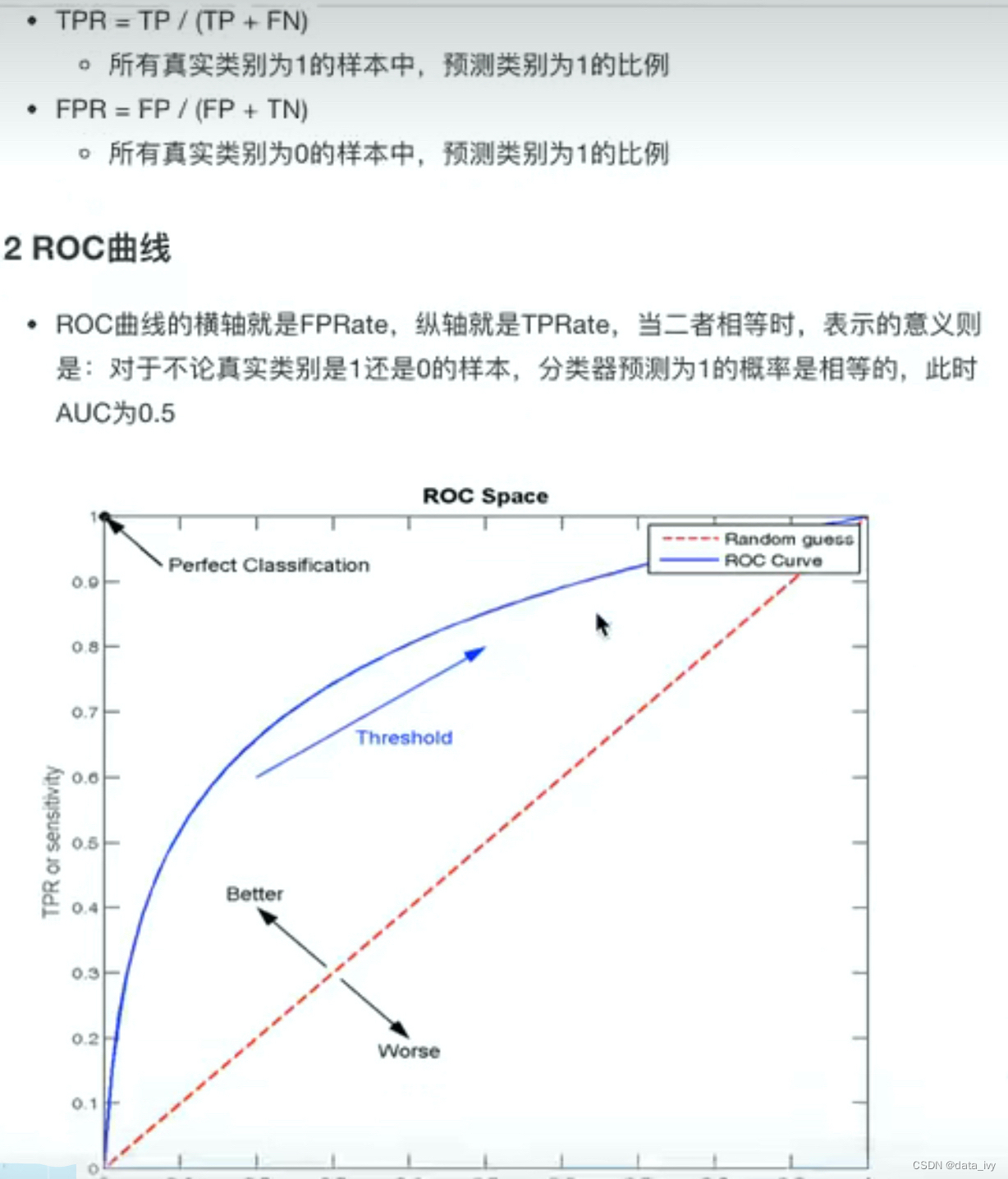
③:ROC曲线和AUC指标:
定义:用来解决样本不均衡的情况下,样本好不好的判定。只能用于评价二分类模型,别的都不行。精确率和召回率都高,不代表就是好模型。
说明:正样本太多的话,精确率和召回率 都会很高,导致预测不准。可以使用这个评估样本不均衡的情况下分类器的效果
蓝色的线是ROC曲线,X轴和Y轴包成的红三角面积是AUC指标,0.5<AUC<1,越接近1 证明模型越好

11、sklearn:
①:安装: pip install scikit-learn
②:内置方法说明:
估算器:fit() 主要用于训练数据集
转换器:transform() 对模型去做转化
预测器:predict() 对新数据进行预测
# sklearn— KNN 的写法 :
from sklearn.neighbors import KNeighborsClassifier # KNeighborsClassifier就是KNN的实例
clf = KNeighborsClassifier(n_neighbors = 3) #n_neighbors 就是K值,不写默认是5
clf = clf.fit(wine_data.iloc[:,0:2], wine_data.iloc[:,-1]) # 第一个参数X传入数据集进行 fit训练模型,第二个参数Y传入结果集,也就是分类的类型
result = clf.predict([[12.8,4.1]]) # 传入新的数据点进行预测 返回预测的值(也就是上面 Y的分组是哪个分组)
result #得到结果 array([0]) # 0 代表 “黑皮诺”,1 代表 “赤霞珠”
# 对模型进行一个评估,score方法 返回预测的准确率
score = clf.score([[12.8,4.1]],[0]) # 传入数据和结果
score # 返回的是准确率 1.0就是100%③:训练集和测试集的划分:
from sklearn.model_selection import train_test_split
# 划分训练集(Xtrain、Ytrain)和测试集(Xtest、Ytest) #20%数据作为训练集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=420) #random_state 随机种子 类似于 random.seed()
# 建立模型&评估模型
clf = KNeighborsClassifier(n_neighbors=4)
# 建立分类器
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score #得到结果④:学习曲线:K取几?
原理:把K值从1-20的范围都取值一遍,变换K值看模型的得分,把得分放到画布里面去,最后图画出来的就少学习曲线,取最优的值就行。
score = [ ] # 得分列表
K = range(1,20) # K的范围
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i) # K是变量
clf = clf.fit(Xtrain,Ytrain) # 训练数据
score.append(clf.score(Xtest,Ytest)) # clf.score得分
# 画图
plt.plot(K,score)
plt.show() 
12、交叉验证:(来解决模型稳定性不高的问题)
KNN 确定了 k 之后,我们发现一件事:每次运行的时候学习曲线都在变化,模型的效果时好时坏, 这是由于「训练集」和「测试集」的划分不同造成的。模型每次都使用不同的训练集进行训 练, 不同的测试集进行测试,自然也就会有不同的模型结果。因此用交叉验 证 n 次的结果求出的均值,是对模型效果的一个更好的度量。
可以使用学习曲线和交叉验证来综合判定 K取哪个
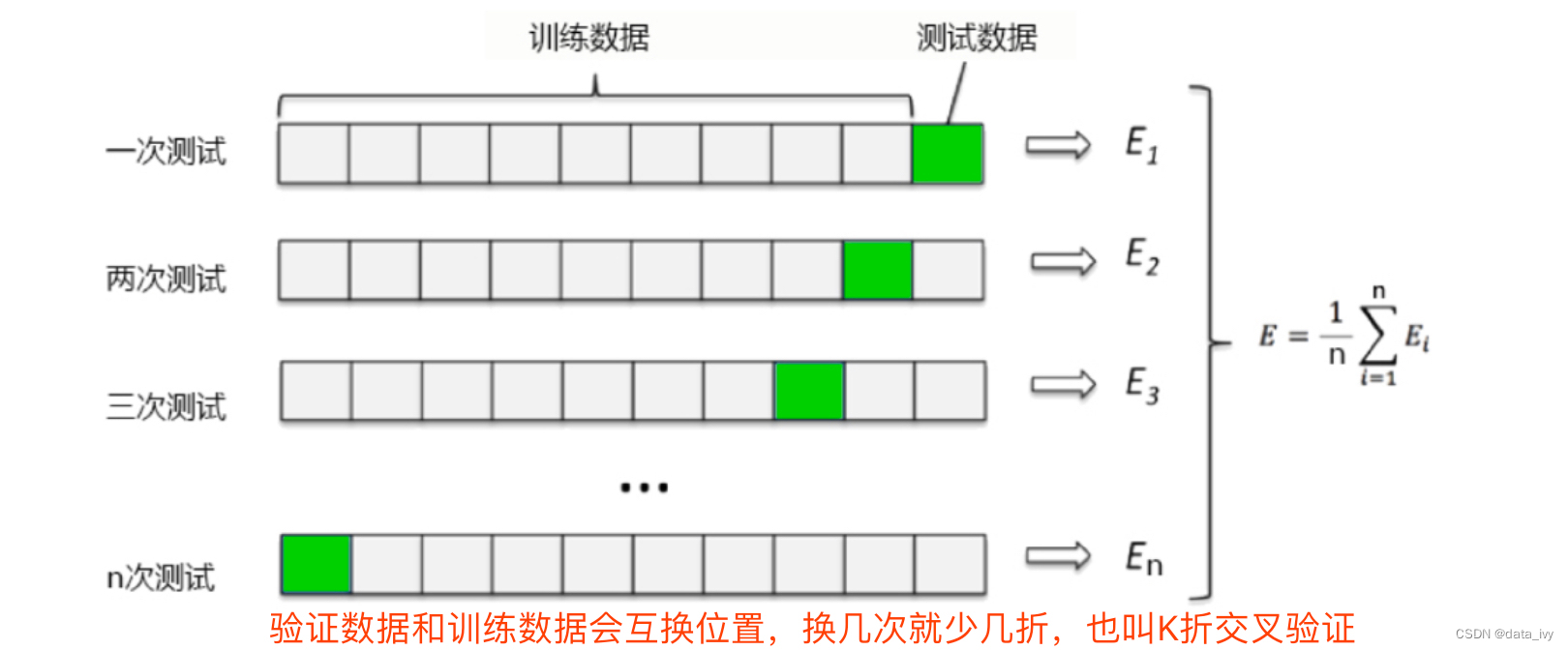
对于带交叉验证的学习曲线,我们需要观察的就不仅仅是最高的准确率了,而是准确率高且方差还相对
较小的点,这样的点泛化能力才是最强的。
# 带交叉验证的学习曲线
from sklearn.preprocessing import MinMaxScaler as mms
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X,y,test_size=0.2,random_state=420)
#归一化
MMS_01=mms().fit(Xtrain) #求训练集最大/小值
MMS_02=mms().fit(Xtest) #求测试集最大/小值
#转换
X_train=MMS_01.transform(Xtrain)
X_test =MMS_02.transform(Xtest)
score=[]
var=[]
for i in range(1,20):
clf=KNeighborsClassifier(n_neighbors=i)
cvresult=CVS(clf,X_train,Ytrain,cv=5) # 交叉验证的每次得分
score.append(cvresult.mean())
var.append(cvresult.var())
plt.plot(krange,score,color="k")
plt.plot(krange,np.array(score)+np.array(var)*2,c="red",linestyle="--")
plt.plot(krange,np.array(score)-np.array(var)*2,c="red",linestyle="--")
plt.show()
最终的到 k 最优值为 8
十五、分析报告的撰写
1、数据分析报告有什么特点?
1、 报告具有正式性

2、报告具有完整性(要符合数据报告的结构)
3、报告具有逻辑性、科学性(逻辑推演+数据支持+统计决策)
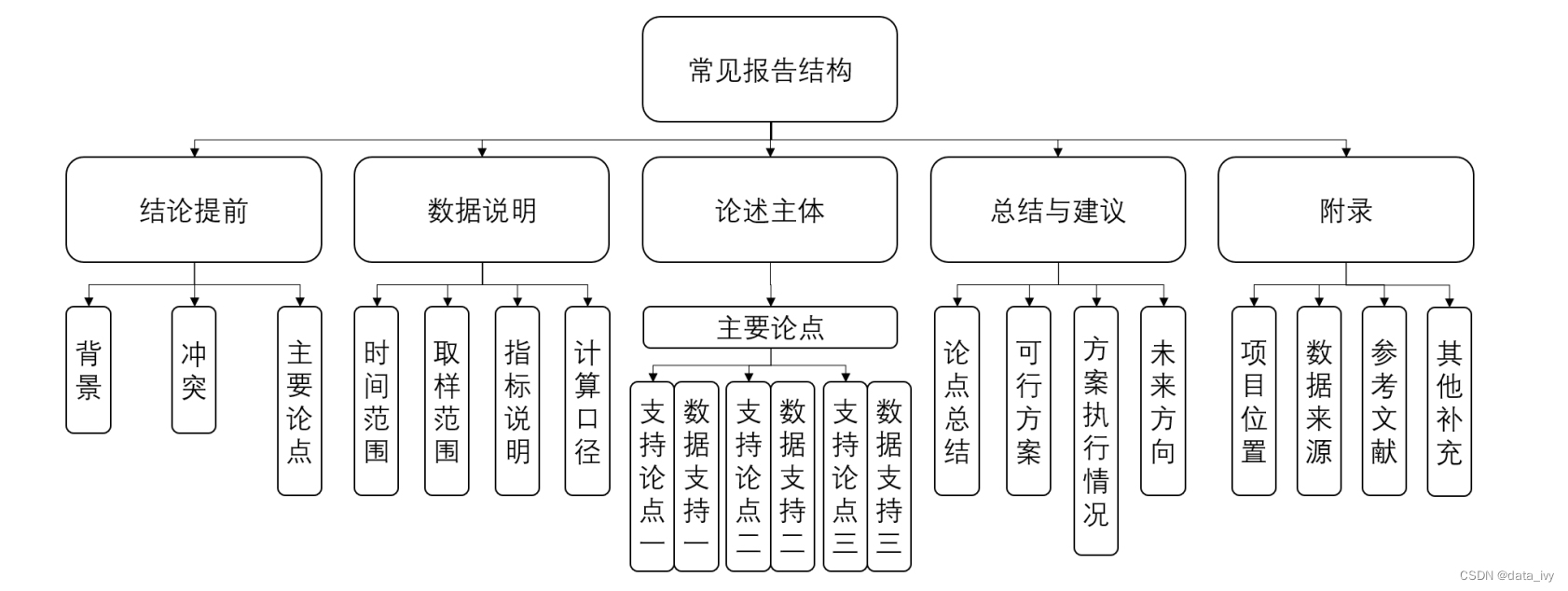
2、数据报告的结构:
3、数据分析报告的作用:
1、内部:解决内部的数据问题,提高产品、项目的内部认同
2、外部:解决客户的数据问题,可通过报告进行产品宣传,从而增加客户或用户
4、我们需要些什么类型的数据报告:

5、分析问题的标准流程:

6、分析师常见的报告有哪些:
监控报告:
①:项目运行是不是正常
②:项目能不能完成目标
专项报告:
①:分析问题类报告(找到原因)
②:后续增长类报告
③:推倒可行性分析报告
④:行业分析
⑤:需求分析(PRD)
7、在线旅游案例示例拆解:















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









