







提到juc,很多人会觉得陌生又熟悉,因为这个包在一般情况下用不到,但是在逛博客、面试、阅读书籍的时候又很容易看到他们的身影,因为这个包几乎和java的并发编程牢牢的绑在了一起,提到并发编码就必定会谈到Doug Lea的juc包,而并发编程又是java编程的重难点之一,总而言之,使用java,你就绕不开并发编程,也绕不开juc,无论你用或者不用,它就在这里,让你时而明白,时而困惑,今天我们就一起来探究构起java.util.concurrent大厦中关于锁最重要的基础类AbstractQueuedSynchronizer。
1、AbstractOwnableSynchronizer
进到AbstractQueuedSynchronizer,我们首先看到,该类继承了另一个抽象类AbstractOwnableSynchronizer

进到AbstractOwnableSynchronizer,我们可以发现,AbstractOwnableSynchronizer并没有太多的内容,只是定义了一个用来保存当前锁拥有者的属性exclusiveOwnerThread,这个类没有太多可看的,还是回到AbstractQueuedSynchronizer吧
2、内部类Node
AbstractQueuedSynchronizer翻译过来就是队列同步器,那我们自然大致能明白这个类的主要功能了,所以在接入逻辑方法学习前,首先来看看AbstractQueuedSynchronizer中定义的队列的数据结构Node。
2.1、属性
//共享模式
static final Node SHARED = new Node();
//独占模式
static final Node EXCLUSIVE = null;
/**
*用来保存节点是共享还是独占锁的模式类似于mode
*在使用condition是用来指向下一个节点,所以这个
*字段相当于将mode和nextWaiter合并到了一起
*/
Node nextWaiter;
//取消状态、表面不参与进行锁竞争
static final int CANCELLED = 1;
//标明在释放锁时,是否需要唤醒后续节点
static final int SIGNAL = -1;
//标明线程在等待条件队列
static final int CONDITION = -2;
//标明下一个获取锁使用共享的模式,并且可以无条件的往下传播
static final int PROPAGATE = -3;
//等待状态
volatile int waitStatus;
//对前一个节点的引用
volatile Node prev;
//后一个节点的引用
volatile Node next;
//节点所包含的等待行程信息
volatile Thread thread;
上面即为Node的全部属性、为了更方便的说明,对某些属性的位置做了调整,并且每个属性都给你对应的中文说明,相信大家一看就能明白,这是我再补充一些简单的说明,
1、SHARED、EXCLUSIVE用来说明获取锁的模式是独占式还是共享式的,在获取node对象时,通过将SHARED或者EXCLUSIVE赋值给nextWaiter来标记该节点获取锁的方式
2、CANCELLED、SIGNAL、CONDITION、PROPAGATE是waitStatus的取值范围,他们的含义也已经标明了,可能单看注释还不能完全理解,后面我们在方法中就能看到这四个值对处理逻辑的影响
3、prev、next分别是对前一个和后一个节点的引用,通过这两个字段完成各个节点之间的链接,形成队列。如下图:
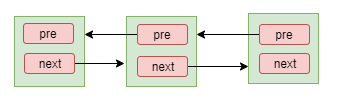
2.2、方法
//是否是共享模式
final boolean isShared();
//获取前一个节点
final Node predecessor() throws NullPointerException
//默认构造器
Node() ;
//指的获取锁模式的构造器mode:SHARED/EXCLUSIVE
Node(Thread thread, Node mode);
//指的等待状态的构造器,在使用Condition时初始化调用
Node(Thread thread, int waitStatus)
Node提供的方法只有两个,作用也很清晰,这里不再赘述,让我们继续往下看
3、AbstractQueuedSynchronizer属性
在了解了队列的数据结构后,接下来就可以开始进行重要属性的了解了,先看Node,也是为了清除在理解属性时的障碍。
//指向队列的首节点
private transient volatile Node head;
//指向队列的尾结点
private transient volatile Node tail;
//锁状态
private volatile int state;
//等待超时的最小时间,在指定等待超时时间时使用
static final long spinForTimeoutThreshold = 1000L;
属性简简单单只有四个,不知道这是不是侧面说明了Doug Lea的牛逼,这么重要的一个基类,只定义了简简单单3个属性,既然是队列同步器,那整个过程肯定就是对队列的操作了,这里通过head、tail完成AbstractQueuedSynchronizer对整个队列的控制,如下图
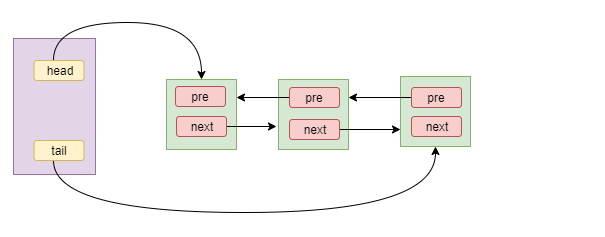
4、AbstractQueuedSynchronizer方法
了解完基本的属性后,就可以开始咱们的正菜了,属性只是基本,对这些属性的操作才是真的干货,这里就不像属性那样一个个的进行注释说明了,这里我先列出最主要的几个方法,然后咱们一起来一个一个的研究,学习。
//独占式获取锁
public final void acquire(int arg);
//独占式获取锁,响应中断
public final void acquireInterruptibly(int arg);
//独占式获取锁,支持设置超时时间
public final boolean tryAcquireNanos(int arg, long nanosTimeout);
//释放独占式锁
public final boolean release(int arg);
//共享式获取锁
public final void acquireShared(int arg);
//共享式获取锁,响应中断
public final void acquireSharedInterruptibly(int arg) throws InterruptedException;
//共享式获取锁
public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException
//释放共享式锁
public final boolean releaseShared(int arg);
4.1、acquire独占式获取锁
public final void acquire(int arg) {
//尝试获取锁
if (!tryAcquire(arg) &&
//获取锁失败,加入获取锁的队列
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
首先第一步就是获取锁,这里我们进入到tryAcquire,看看实现逻辑
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
what,直接抛了一个异常?这是什么鬼!其实这就体现了AbstractQueuedSynchronizer作为基础类的设计了,对于获取锁,AbstractQueuedSynchronizer只是提供了一个模版方法,对应的实现细节由具体的子类进行实现,这样就能够通过不同的子类实现,设计出不同的锁特性,比如读写锁、可重入锁,而AbstractQueuedSynchronizer负责处理复杂的队列管理,我们来简单看看ReentrantLock中对tryAcquire的实现:


从截图可以看出,ReentrantLock的内部类sync继承了AbstractQueuedSynchronizer,而内部类NonfairSync继承了sync,在NonfairSync中完了了对tryAcquire的重写
static final class FairSync extends Sync {
protected final boolean tryAcquire(int acquires) ;
}
这里我们先不探究tryAcquire的实现细节,我们只需要明白tryAcquire的实现细节在其子类,AbstractQueuedSynchronizer只是帮助子类完成了复杂的等待队列管理,那么我大致梳理一下使用ReentrantLock进行锁操作的整个调用链,来帮助读者进行框架的了解。
ReentrantLock使用示例:
public class UseReenTrantLock {
private ReentrantLock reentrantLock=new ReentrantLock();
private void method(){
reentrantLock.lock();
try {
System.err.println("当前线程"+Thread.currentThread().getName()+"进入。。。");
Thread.sleep(2000);
System.err.println("当前线程"+Thread.currentThread().getName()+"退出。。。");
} catch (InterruptedException e) {
e.printStackTrace();
}finally{
reentrantLock.unlock();
}
}
}
以上面使用reentrantLock为例,我们通过reentrantLock.lock()获取锁,然后通过reentrantLock.unlock()释放锁,我们来看下获取锁的调用链
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
这里if部分的逻辑是非公平锁的体现,与整体调用逻辑无关,我们假设if里面的逻辑失败,这时就会调用acquire(1),这个acquire正是AbstractQueuedSynchronizer中定义的那个方法,我们已经知道了,acquire的第一步就是调用tryAcquire去获取锁,由于子类ReentrantLock中有对tryAcquire的重写,所以这时就会进入到子类的tryAcquire方法中进行锁的调用,如果锁获取失败,回到acquire方法中,会通过acquireQueued进行队列逻辑处理,所以整个的调用逻辑如下
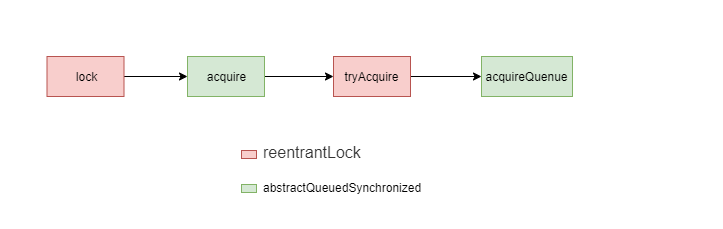
简要说明了一下获取锁时子类与父类之间方法的调用链,我们回到主题上,继续分析acquire方法,避免大家要来回滚动,我这里再复制下代码
public final void acquire(int arg) {
//尝试获取锁
if (!tryAcquire(arg) &&
//获取锁失败,加入获取锁的队列Node.EXCLUSIVE,说明是独占式
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
tryAcquire获取锁,假设失败,这时便会进入acquireQueued方法,这里我们需要先看下addWaite方法。
private Node addWaiter(Node mode) {
//将当前队列封装为一个node
Node node = new Node(Thread.currentThread(), mode);
//获取最后节点的指向
Node pred = tail;
//如果最后节点不为空,则将新节点放到最后,并将tail指向新节点
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//如果尾结点为空,说明这是第一个节点
enq(node);
return node;
}
private Node enq(final Node node) {
//循环处理,直到插入成功
for (;;) {
Node t = tail;
//如果尾结点为空,初始化队列,插入空队列
if (t == null) {
//使用compareAndSetHead方法,防止并发
if (compareAndSetHead(new Node()))
tail = head;
} else {
//将node插入到空队列后面
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
这里没什么说的,根据注释就能明白,顺便提下在enq中,初始化队列的时候,为什么不是直接将新节点node1作为首节点进行初始化,而是new一个空队列作为首节点,然后将node1放在空节点后面?这是因为在锁释放时,当前锁线程会唤醒head后面的队列进行锁竞争,如果这里初始化等待队列的时候,直接使用node1作为首节点,那么在当前获取到锁的线程释放锁时,会去唤醒head后面的节点进行锁竞争,而head指向的是当前节点,那么结果就是node1直接被跳过。
acquireQueued方法:
final boolean acquireQueued(final Node node, int arg) {
//获取锁时候失败
boolean failed = true;
try {
//标记线程是否被中断
boolean interrupted = false;
for (;;) {
//获取当前节点的上个节点
final Node p = node.predecessor();
/**如果上个节点是head节点,那么尝试去获取一次锁
*获取锁成功,则设置当前节点为head节点,返回
*/
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
//是否需要将线程挂起,如果需要,挂起线程,等待唤醒
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
//如果自旋结束,未获取到锁,则取消线程获取锁,移出队列
if (failed)
cancelAcquire(node);
}
}
逻辑也不是很复杂,就是循环,自旋获取锁,当然不可能在获取不到锁的情况下一直自旋,这会消耗性能做无用功,所以在满足条件下,会挂起线程,先来看看什么情况下会挂起线程
shouldParkAfterFailedAcquire
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
/**前节点的等待状态为SIGNAL,说明在他释放锁的时候会唤醒我(当前节点线程)
*那我可以安心的挂起,等你唤醒就可以了
*/
if (ws == Node.SIGNAL)
return true;
/**
*ws > 0,说明ws为CANCELLED,那说明前节点处于取消状态,他不会去获取锁,那更不可能
*在释放锁的时候唤醒我,这就危险了,要是挂起了,那不是得永远挂起了
*怎么办呢,既然你不想获取锁了,那还在等待队列里面干啥,踢出去,一直往前踢
*直到碰到还有追求(想获取锁)的节点为止
*/
if (ws > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
//这里表示ws为PROPAGATE或者0(默认状态)那么就需要将他的状态设置为SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
好了,shouldParkAfterFailedAcquire也不复杂,跟着我的注释应该能看的很明白了,回到外层方法,如果返回true,就会通过将当前线程挂起,直到被唤醒,到此获取锁的整个流程基本上分析完了,还差最后一个方法,当线程被中断时,获取锁失败,在finally中会调用cancelAcquire,取消获取锁,既然只剩最后一个了,当然也不能放过了,一起看看吧
private void cancelAcquire(Node node) {
if (node == null)
return;
//将节点线程置空
node.thread = null;
// 获取当前节点的前节点
Node pred = node.prev;
//如果前节点的等待状态大于0(CANCELLED),向前扫码,清除掉所有已取消的点位
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
/**
*获取pred的下一个节点,这里看似获取的predNext等价于node,但是在多行程并行的情况下不一定
*因为有可能别的线程在后面的逻辑中替换了pred所指向节点的后节点
*/
Node predNext = pred.next;
//设置当前节点为已取消
node.waitStatus = Node.CANCELLED;
// 如果当前节点为尾结点,那么设置前节点为尾结点
if (node == tail && compareAndSetTail(node, pred)) {
//设置成功,则将前节点的后节点指向空,以此将node从等待队列中清除
compareAndSetNext(pred, predNext, null);
} else {
int ws;
//前节点不为头节点且 前节点为SIGNAL或者可以设置为SIGNAL 且线程不为空
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
//获取当前节点的后节点
Node next = node.next;
//如果后节点不为空且后节点不为已取消,将前节点的next指向后节点,以此将node移出队列
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
/**
*这里通过前面一系列的判断,可以断定他的前节点为head,那么就需要在此处唤醒后节点
*因为如果此处不做唤醒操作,当node节点被移出后,再也没有节点会去唤醒后节点
*后节点开始自旋后,会进入shouldParkAfterFailedAcquire,将node从等待队列中移除出去
*因为node的waitStatus被设置成了CANCELLED
*/
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
在获取predNext的时候,使用pred.next,而不是直接使用node,这是因为,在多线程的情况下,有可能其他线程在执行compareAndSetNext的时候,将pred.next的指向改变了,所以有可能pred.next并不是node
至此,独占式获取锁的acquire涉及的所有代码都过了一遍了,逻辑并不复杂,主要逻辑还是在acquireQueued中,获取锁的细节代码在子类实现中。整个流程如下
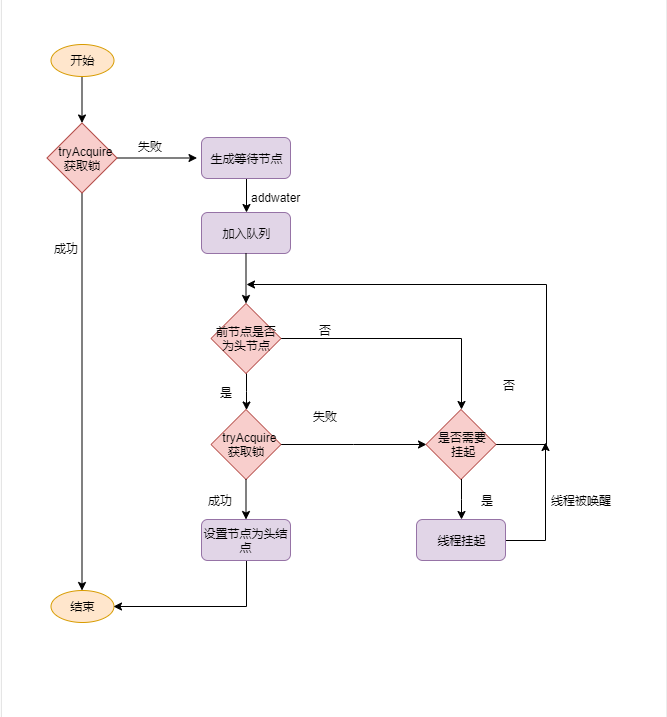
在看完acquire之后,基本上AbstractQueuedSynchronizer就完成一大半了,因为其他的方法都是在acquire逻辑上的一些扩展,区别不是很大
4.2、acquireInterruptibly独占式获取锁,响应中断
acquireInterruptibly和acquire相似,主要逻辑相同,不同的就是在处理线程中断的逻辑,首先看acquireInterruptibly方法
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
相比于acquire,acquireInterruptibly在线程中断时抛出了线程中断的异常,而acquire通过返回值来判断是否发生中断,如果发生中断,则恢复中断状态
再看看doAcquireInterruptibly和acquireQueued有哪些区别
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
/**
*添加节点,模式和acquire一样,使用EXCLUSIVE独占,
*只是这里将addWaiter放到了方法里面,acquire在传参时调用
*/
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
//抛出中断异常
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
可以看出,和acquireQueued相比,获取锁的逻辑一致,但是在发生异常时,acquireQueued通过interrupted字段进行标记是否发生异常,而doAcquireInterruptibly直接抛出异常。
4.3、tryAcquireNanos独占式获取锁,可设置超时时间
acquireInterruptibly是在acquire的基础上增加了对线程中断的响应,而tryAcquireNanos则是在acquireInterruptibly的基础上增加了超时设置,所以tryAcquireNanos也具备中断响应的能力
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
有了acquire的学习过程,这里看起来就一目了然了,还是直接进doAcquireNanos看一下区别吧
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
//如果设置的超时时间小于等于0,直接退出
if (nanosTimeout <= 0L)
return false;
//获取终点时间
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
//获取剩余的超时时间
nanosTimeout = deadline - System.nanoTime();
//如果超时,直接退出
if (nanosTimeout <= 0L)
return false;
/**
*判断是否需要挂起,多了一个条件就是判断剩余的超时时间是否大于设定的最小值(1000)
*如果大于,才进行挂起,这里主要是考虑到如果线程挂起,超时时间过短的话
*马上又要唤起线程进行超时退出,为了平衡线程切换和自旋的效率,所以设置了最小界限值
*/
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
//挂起是,设置了挂起的时间
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
可以看出还是相似的逻辑,同样的味道,只是多了一些超时的判断,不同的地方都加上了注释,理解起来应该不难。
4.4、release释放独占式锁
public final boolean release(int arg) {
//释放锁
if (tryRelease(arg)) {
//释放成功后,获取head
Node h = head;
if (h != null && h.waitStatus != 0)
//唤醒head指向的下一个节点
unparkSuccessor(h);
return true;
}
return false;
}
相比于获取锁,释放锁的逻辑就简单多了,因为释放锁的操作只有获取锁的线程可以执行,所以整个释放锁的过程都处在一个单线程操作的环境,同样的,释放锁的细节实现也在对应的实现类中进行,这里就不像获取锁那样举例了,大概的调用逻辑和获取时一样,就是unlock->release->tryRelease->release
4.5、acquireShared共享式获取锁
相对于独占锁,共享锁的特点就是可以多个线程同时获取锁,最常听说的就是读锁了,这里我们还是看代码吧
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
没有意外,获取锁的细节还是由子类进行实现,而在这个父类的学习中,我们也只需要关注等待队列的处理即可
private void doAcquireShared(int arg) {
//创建节点加入队列中,使用SHARED,共享模式
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
//获取前节点
final Node p = node.predecessor();
//如果前节点为头节点
if (p == head) {
//获取锁
int r = tryAcquireShared(arg);
//获取锁成功,设置头结点,如果中断,直接中断线程
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
//线程挂起
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
//取消
cancelAcquire(node);
}
}
其他的获取锁的模式都是在acquire的基础上改进而来的,那我们对于其他模的式学习,也主要基于和acquire的对比来进行,因此能对acquire理解透彻的话,整个类中的其他方法理解起来就很轻松了,只不过是加法减法的问题,和acquire调用的acquireQueued相比,doAcquireShared只有一个地方不同,那就是在设置队列头的地方,一个是调用setHead,一个是调用setHeadAndPropagate,看名字就能知道,doAcquireShared这里在设置队列头时,做了更多的操作,除此以外,除了代码放置位置的调整,再无其他不同。那我们就直接看下setHeadAndPropagate多做了哪些处理
private void setHeadAndPropagate(Node node, int propagate) {
//获取原队列头
Node h = head; // Record old head for check below
//设置新队列头
setHead(node);
//判断下一个节点是否可以被唤醒
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
//唤醒后续的共享式获取同步状态的节点
doReleaseShared();
}
}
因为是共享模式获取锁,锁可以被多个线程同时获取,所以在获取到锁的同时,需要去判断下一个节点是否也是共享模式,如果是的话,就需要 唤醒后续节点对锁的获取,也就是相比于setHead,setHeadAndPropagate增加的处理逻辑。
4.6 acquireSharedInterruptibly和tryAcquireSharedNanos
acquireSharedInterruptibly、tryAcquireSharedNanos相比于doAcquireShared,就和acquireInterruptibly、tryAcquireNanos相比于acquire是一模一样的,这里在单独说就有点码字数的感觉了,跳过!跳过!
4.7releaseShared
废话不多说,直接看它调用的doReleaseShared,其实在获取锁时,setHeadAndPropagate在唤醒下一个节点时,就是调用的doReleaseShared,所以这里也相当于是接着setHeadAndPropagate继续向下分析。
private void doReleaseShared() {
for (;;) {
//获取head
Node h = head;
//如果头节点不为空且头节点不为尾节点
if (h != null && h != tail) {
//获取头节点状态
int ws = h.waitStatus;
//如果为SIGNAL,则设置为初始化状态0,设置成功则唤醒下一个节点
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
//唤醒节点
unparkSuccessor(h);
}
//如果为初始化状态,设置为PROPAGATE
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
//如果h == head,则退出循环
if (h == head) // loop if head changed
break;
}
}
相比于独占式的release,这里的doReleaseShared要复杂一点,因为独占式的锁,在释放锁时,只有获取锁的线程可以执行,就是一个纯单线程的操作,没有太多需要考虑的,而共享式锁,多个线程共享,所以在释放时,也是多线程环境的,相比于release,会复杂一点,但看看注释,理解起来问题也不大,最后一步,因为在获取锁的情况下会修改head,所以这里有可能为false,如果为false,结合setHeadAndPropagate就知道,这里我们需要继续往下唤醒线程,所以会继续进行下一轮的线程唤醒。
总结
整个类看下来,其实最主要的就是对acquire方法的理解,其他获取锁的方式都是在这个方式上改进而来的,在开篇介绍的属性中,有一个status字段,但是整篇下来,我们都没有看到这个字段的身影,其实这个字段主要是用在具体的实现类中,用于锁状态的标记,也就是tryAcquire、tryAcquireShared需要做的事情,所以把AbstractQueuedSynchronizer理解透彻了后,学习juc中具体的锁实现就很轻松了,基本上就只需要理解实现类中对status字段的操作就可以了。AbstractQueuedSynchronizer中其实还有一个比较重要的内部类ConditionObject,他实现了Condition接口,用来作为条件队列提供更为灵活的等待 / 通知模式,但是如果这里一并讲完的话,觉得篇幅太长了,不利于阅读,所以这篇就主要写一下获取锁和释放锁的部分,之后有机会在说说Condition。














 2832
2832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









