







Apache Hadoop常见命令汇总
创建文件夹
hadoop fs -mkdir [-p] path
- -p,将前置目录也创建
- path,hdfs路径
查看hdfs内容
hadoop fs -ls [-R] path
- -R,递归查看文件夹内的子文件夹和文件
- path,hdfs路径
查看文件内容
hadoop fs -cat path
- path,hdfs路径
升级写法:
hadoop fs -cat path | more
避免文件过大,翻页查看
复制文件
hadoop fs -cp [-f] path1 path2
- -f,重名会覆盖
- path1,被复制hdfs路径
- path2,目的地hdfs路径,有改名效果
移动文件
hadoop fs -mv path1 path2
- path1,被移动hdfs路径
- path2,目的地hdfs路径,有改名效果
追加内容
hadoop fs -appendToFile localpath hdfspath
- localpath 本地文件
- 如果是
-,可以手动输入内容,按ctrl + c提出
- 如果是
- hdfspath,被追加的文件
上传文件到hdfs
hadoop fs -put localpath hdfspath
- localpath 本地文件
- hdfspath hdfs文件路径
下载文件到本地
hadoop fs -get hdfspath localpath
- localpath 本地文件
- hdfspath hdfs文件路径
删除文件或文件夹
hadoop fs -rm [-r] path
- -r,删除文件夹用
- path,被删除的hdfs路径
修改文件或文件夹的权限
hadoop fs -chmod [-R] number hdfspath
- -R 对文件夹内的全部子文件应用同样设置
- number:权限数字,如754,也可以替换为:u=
rwx,g=r-x,o=r--这个形式 - hdfspath,被设置的路径(文件或文件夹)
修改文件或文件夹的所属用户和所属用户组
hadoop fs -chown [-R] u:g hdfspath
- -R 对文件夹内的全部子文件应用同样设置
- u表示要修改的所属用户
- :g要修改的所属用户组
- hdfspath hdfs路径
设置副本数量
hadoop fs -setrep [-R] number path
- -R 对文件夹内的全部子文件应用同样设置
- number,数字,被设置的副本数
- path,被修改的文件
上传数据指定副本数
hadoop fs -D dfs.replication=number -put localpath hdfspath
- -D 临时让这一条命令以你指定的配置项去执行
- -D key=value
- dfs.replication就是配置项设置如何决定文件的副本数
- dfs.replication=number,number是数字,副本数
- localpath 本地文件路径
- hdfspath hdfs路径
检查文件系统状态 fsck
hdfs fsck path [-files [-blocks [-locations]]]
- path 被检查的文件夹或文件(HDFS的)
- -files:列出被检查的文件信息
- -block:列出被检查文件的块信息(必须写-files)
- -locations:列出被检查文件的副本信息(必须写-blocks)
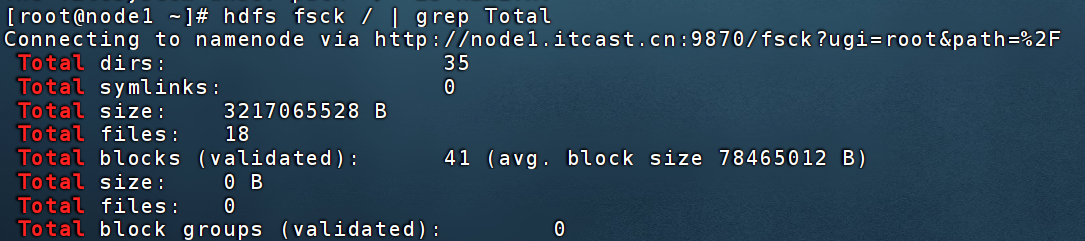
配合管道符和grep可以快速过滤查看信息。
YARN启动关闭
一键启动
包含ResourceManager和NodeManagers和Proxyserver
start-yarn.sh
不包含历史服务器,需要自己启动它
一键关闭
stop-yarn.sh
命令的本体存在于:/export/server/hadoop/sbin/stop-yarn.sh
单独的角色启停
可以单独控制:resourcemanager、nodemanager、proxyserver(代理服务器)、historyserver(历史服务器)
# 写法1
yarn-daemon.sh (start | stop) (resourcemanager | nodemanager | proxyserver)
# 上述命令使用:/export/server/hadoop/sbin/yarn-daemon.sh
# 写法2
yarn --daemon (start | stop) (resourcemanager | nodemanager | proxyserver)
# 上述命令使用:/export/server/hadoop/bin/yarn
这两种写法,一个用
sbin中的.sh文件,一个用bin里面的yarn程序但是效果一模一样。
历史服务器的控制
# 写法1
mr-jobhistory-daemon.sh (start | stop) historyserver
# 写法2
mapred --daemon (start | stop) historyserver
分散汇总模式和中心调度-步骤执行模式
分散汇总模式更注重并行执行和结果的汇总,而中心调度-步骤执行模式更注重任务的调度和执行顺序
ZooKeeper
# 开启服务
zkServer.sh start
# 查询服务状态
zkServer.sh status
# 关闭服务
zkServer.sh stop
# 开启本地客户端
zkCli.sh
# 远程链接其他服务客户端
zkCli.sh -server 服务器ip
zookeeper的过半原则:
集群服务中启动服务数量过半则集群可用,宕机服务数量过半则服务崩溃















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









