






目录
一 Kylin设计核心思想
业务的发展伴随着事实表的数据体量的增大,查询时间也越来越长,而另一方面,结果集的数据量却没有显著增长,指标的变化也并不频繁。我们希望所有的查询都能在秒级返回查询结果,于是,我们有了一个思路:为什么不能把所有的结果先算好,查询时直接从结果集中取出来呢?这也就是 kylin 设计的初衷。
kylin的核心思想是预计算。
好,现在这个组件已经有了一个准确的定位,那么接下来要解决的问题就是如何实现预计算,这套架子里究竟需要什么组件呢?
二 Kylin基本架构
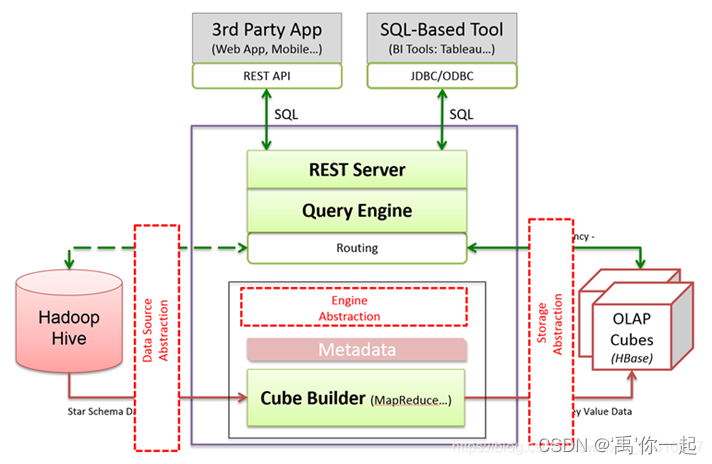
上图中,蓝色的框框是 kylin 系统的边界,里面是 kylin 的核心功能,蓝色框框外面的部分是 Kylin 的外围插件和适配器。
从模块上来看,大致分为以下几部分:
Data Source Abstraction:数据源抽象层,目前离线的主流实现是 hive,实时的主流实现是 kafka。
Cube Builder:也就是构建引擎,目前支持 MapReduce 和 Spark。
Storage Abstraction:结果集存储抽象层,目前主流实现是 hbase,也可以以数据流的方式输出到其他大数据生态工具。
Metadata:元数据管理,包括 model,cube,job 等元数据的信息,由于 Kylin 的结果表名和 rowkey 都是经过编码的,必须要通过元数据来映射,所以元数据非常关键,若元数据损坏,相对应的结果集也会不可用,表现为表损坏或查询时报错。
Rest Server:通过 Restful API,JDBC/ODBC 的方式向外界提供接口。
Query Engine:查询引擎,内置 Apache 开源 SQL 解析工具 Calcite,生成执行计划并执行物理查询计划。
Routing:路由转换,实时查询情景下,路由指向数据存储层 Hbase,准实时查询情景下,路由指向数据源层 Hive,准实时情景一般是在结果集的数据满足不了查询需求时,Kylin会转而向数据源做查询,也就是所谓的“查询下压”。
从数据流上来看,大致分为以下几部分:
红线:离线任务数据流,从数据源 Hive 读取数据,经计算引擎 MapReduce 或 Spark 计算,生成结果集并存储到 Hbase,离线构建任务可以定时,构建任务可通过 Rest API 定时调度。
绿色实线:实时查询数据流,从客户端通过 Rest API 或 JDBC/ODBC,经 Rest Server 和 Query Engine 处理,由路由转发至 Hbase,秒级返回查询结果。
绿色虚线:准实时查询数据流,查询下压时,通过数据源直接汇总出查询结果,性能视计算复杂程度而定。
接下来,我们就要涉及到 Cube 构建的一些概念啦
三 基本概念
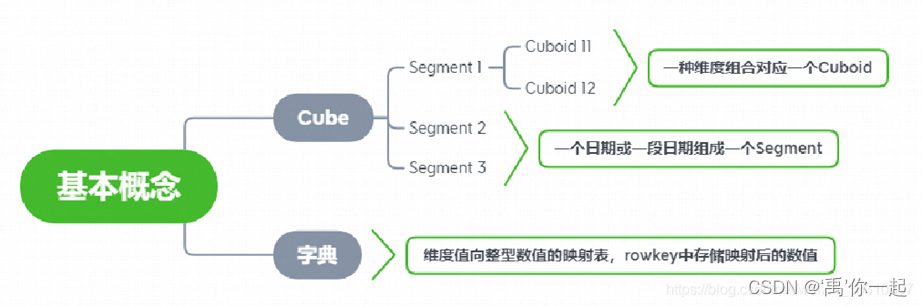
Cube / Segment / Cuboid :一个查询结果集为一个 Cube; 对于分区表来说,一个日期区间为一个 Segment,一个 Cube 可分为多个 Segment ;每个 Segment 中,有不同维度组合的小结果集,每个小结果集称为一个 Cuboid ,如A维度,B维度,A+B维度,就是3个不同的 Cuboid,同一个Cube 中,不同 Segment 中的 Cuboid 组合和个数都相同。
字典:可以把字典理解为维度值向整型数值的映射表,若一个维度值用了字典编码,Hbase 的 rowkey 中就会存储映射后的整数值以提高检索速度,字典内部数据是有序的,方便查找和筛选。字典分为两种:Global Dictionary 和 Segment Dictionary,区别是作用域不同,分别为整个 Cube 或一个 Segment。字典在运算时会加载到内存中,所以,对于一些基数比较高的维度,要慎用字典,防止查询时内存溢出。














 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









