







前两节主要介绍了hadoop运行环境和开发环境的搭建,有了这个,我们就可以开始hadoop的学习了,最近买了两本hadoop的书,先是买了一本《hadoop权威指南》,看了几天,感觉大部分都是在讲理论,不太适合作为hadoop入门的书籍,所以又买了本国内刘鹏写的《实战hadoop》,这本书到是写的比较浅显易懂,尤其是操作性比较强,个人觉得比较适合作为hadoop的入门书籍。这里就记录一下我学习hadoop的笔记吧。
1.hadoop的产生
首先,hadoop是一个分布式系统基础架构,它可以让用户在不了解分布式底层细节的情况下,充分利用集群的威力,开发分布式程序,实现高速运算和存储。
2003年和2004年,google先后发表两篇论文《The Google File System》和《MapReduce: Simplified Data Processing on Large Clusters》。在这两篇论文的驱动下,Hadoop创始人DougCutting为改善Nutch的性能,实现了DFS和MapReduce机制并将其成功应用于Nutch,说到Nutch,不得不说一说Lucene,Lucene是一个Java高性能全文索引引擎工具包,它可以方便地嵌入到各种实际应用中实现全文索引搜索功能,而Nutch是一个应用程序,它是一个以Lucene为基础实现的搜索引擎应用。Hadoop就是从Nutch项目中分离出来的一个专注于DFS和MapReduce的开源项目。
2.hadoop架构
hadoop是一个能够对大量数据进行分布式处理的软件框架,它主要包括两部分:用于分布式计算的MapReduce和用于分布式存储的HDFS。在分布式计算和分布式存储两个方面,Hadoop都采用了主/从(Master/Slave)架构,如下图所示:
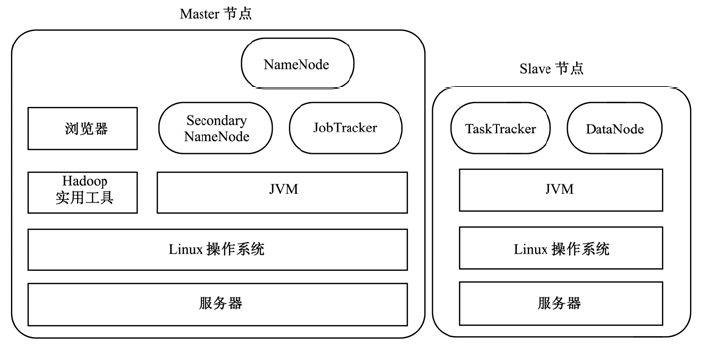
要在一个集群中运行hadoop,需要在集群中运行一系列的后台程序:NameNode、DataNode、Secondary NameNode、JobTracker、TaskTracker。其中,NameNode、DataNode、Secondary NameNode用于分布式存储,JobTracker、TaskTracker用于分布式计算(一个准备提交执行的应用程序成为作业(job),而从一个作业划分出来的、运行于各计算节点的工作单元称为任务(task))。另外,如上图所示,NameNode、Secondary NameNode、JobTracker运行于Master节点上,每个Slave节点上都部署有一个DataNode和TaskTracker,以便于这个Slave服务器上运行的数据处理程序能尽可能直接处理本机的数据。
下面分别介绍这些后台程序:
1)NameNode
NameNode是HDFS的守护程序,负责记录文件是如何分割成数据块的,以及这些数据块分别被存储到哪些数据节点上。它的主要功能是对内存和I/O进行集中管理。
一般来说,NameNode所在的服务器不存储任何用户信息或执行计算任务,以避免这些程序降低服务器的性能。如果从服务器宕机,Hadoop集群仍旧可以继续运转。但是,由于NameNode是Hadoop集群中的一个单点,如果NameNode服务器宕机,整个系统将无法运行。
2)DataNode
集群中的每个从服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通信,并对相关的数据块进行读/写操作。
3)Secondary NameNode
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序,就像NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一台单独的服务器上。Secondary NameNode不同于NameNode,它不接收或记录任何实时的数据变化,但是,它会于NameNode进行通信,以便定期地保存HDFS元数据的快照。由于NameNode是单点的,通过SecondaryNameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
4)JobTracker
JobTracker后台程序用来连接应用程序与hadoop。用户代码提交到集群以后,由JobTracker决定哪个文件将被处理,并且为不同的task分配节点。同时,它还监控所有运行的task,一旦某个task失败了,JobTracker就会自动重新开启这个task,在大多数情况下,这个task会被放在不同的节点上。每个hadoop集群只有一个JobTracker,一般运行在集群的Master上。
5)TaskTracker
TaskTracker与负责存储数据的DataNode相结合。其处理结构上也遵循主/从架构,JobTracker位于主节点,统领MapReduce工作;而TaskTrackers位于从节点,独立管理各自的Task。每个TaskTracker负责独立执行具体的Task,而JobTracker负责分配task。虽然每个从节点仅有唯一的一个TaskTracker,但是每个TaskTracker可以产生多个Java虚拟机(JVM),用于并行处理多个map以及reduce任务。TaskTracker的一个重要职责就是与JobTracker交互,如果JobTracker无法准时获取TaskTracker提交的信息,JobTracker就判定TaskTracker已经崩溃,并将任务分配给其他节点处理。
3.hadoop族群
整个hadoop族群包括很多个项目,如下:
Common:是整个hadoop项目的核心,包括一组分布式文件系统和通用I/O的组件与接口(序列化、java RPC和持久化数据结构)。
MapReduce:大型数据的分布式并行编程模型和程序执行框架,Google的MapReduce的开源实现。
HDFS:向应用程序提供高吞吐量访问的文件系统,是GFS的开源实现。
Avro:一种支持高效、跨语言的RPC以及永久存储数据的序列化实现。
Pig:一种数据流语言和运行环境,用以检索非常大的数据集,运行在MapReduce和HDFS的集群上。
Hive:一个分布式、按列存储的数据仓库。Hive管理HDFS中存储的数据,并提供基于SQL的查询语言(由运行时引擎翻译成MapReduce作业)用以查询数据。
HBase:一个分布式、按列存储数据库。HBase使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)。
ZooKeeper:一个分布式、可用性高的协调服务。ZooKeeper提供分布式锁之类的基本服务用于构建分布式应用。
Cassandra:是一套开源分布式NoSQL数据库系统,它最初由Facebook开发,用于存储收件箱等简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身。
Mahout:是一个在Hadoop上运行的机器学习类库(例如分类和聚类算法)。
参考:
《实战Hadoop》 刘鹏
《Hadoop权威指南》第二版 Doug Cutting














 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









