







本文参考:
《机器学习》周志华
主成分分析(PCA)原理总结——刘建平
有关Pca的使用:样本数目和降维数目的关系
————————————————————————————————————
主成分分析(Principal Component Analysis)简称PCA,是一种最常用的降维方法。从名字里就可以看出,它追求的是找到主成分,在低维度的情况下尽可能的代表原来的数据情况。
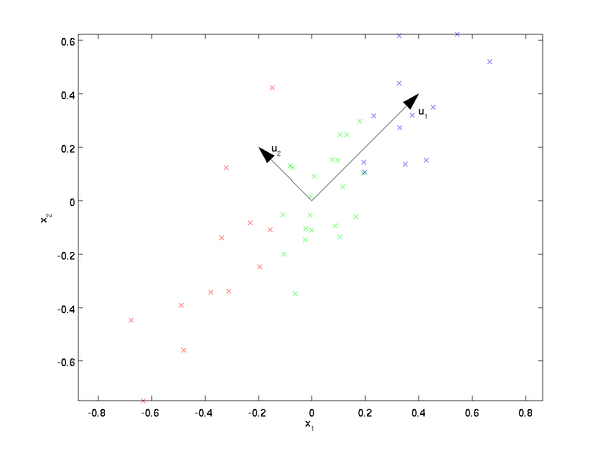
从上图就可以看出,若想把二维数据降为一维,u1相对于u2来说是更优的一个坐标系,原因就是数据投影到u2上相对来说损失更少,能更好的代表原来的数据,PCA降维的过程便是在寻找降维后最优的坐标系。
用官方一点的话来描述:我们考虑的是,对于正交属性空间中的样本点,如何用一个超平面(直线的高维推广)对所有样本进行恰当的表达。(这里的超平面当然不能理解为平面,而是一定维度的坐标系)
若从这个问题出发,我们可以从以下两条性质出发去寻找这个超平面:
- 最近重构性:样本点到这个超平面的距离都足够近
- 最大可分性:样本点在这个超平面上的投影能尽可能分开
看似都有道理,那我们应该遵循哪条规则呢?其实分别从这两条规则出发,最终能得到PCA的两种等价推导。
基于最近重构性
假设原数据为m个n维数据 ( x ( 1 ) , x ( 2 ) , x ( 3 ) , . . . , x ( m ) ) (x^{(1)},x^{(2)},x^{(3)},...,x^{(m)}) (x(1),x(2),x(3),...,x(m)),且数据都已经进行了中心化处理,即 ∑ i = 1 m x ( i ) = 0 \sum_{i=1}^{m}x^{(i)}=0 ∑i=1mx(i)=0。中心化的本质是数据的平移,将数据平移至中心为原点,此处中心化是为了之后求解方便。
假设经过投影变换后得到的新坐标系为 { ω 1 , ω 2 , . . . , ω n } \{\omega_1,\omega_2,...,\omega_n\} {ω1,ω2,...,ωn}(此时还是n维),这个新坐标系是标准正交基,即 ∣ ∣ ω ∣ ∣ 2 = 1 ||\omega||_2=1 ∣∣ω∣∣2=1, ω i T ω j = 0 \omega^T_i\omega_j=0 ωiTωj=0。
上述定义了原始数据和新坐标系,如果想把原始数据从n维降到d维,那么我们就需要在新坐标系中丢弃一部分维度,也就是把新坐标系变成 { ω 1 , ω 2 , . . . , ω d } \{\omega_1,\omega_2,...,\omega_d\} {ω1,ω2,...,ωd},样本点 x ( i ) x^{(i)} x(i)在低维坐标系中的投影为 z i = ( z i 1 ; z i 2 ; . . . z i d ) z_i=(z_{i1};z_{i2};...z_{id}) zi=(zi1;zi2;...zid),其中 z i j = ω j T x ( i ) z_{ij}=\omega^T_jx^{(i)} zij=ωjTx(i)是 x ( i ) x^{(i)} x(i)在低维坐标系下第 j j j维的坐标。
解释一下这个坐标计算的公式的原理。
在上文中
x
i
x_i
xi代表原始数据在原坐标系下的那个向量。这么来理解,首先有两个事实,一是样本点是不会变的,无论参考坐标系变成啥样,也只是坐标在变,点永远在那个位置。第二是在寻找降维坐标系时,只需绕原点旋转,无需平移。这也是好理解的,因为数据已经根据零点对称化了。那么
x
i
x_i
xi代表起点为原点,终点为样本点的向量,向量的坐标就是原始坐标系下的坐标。向量与新坐标系下的基向量相乘,就相当于原始长度上取了个
c
o
s
cos
cos值,就映射到了新坐标轴上。
假设上文中定义的新坐标系还没有丢弃坐标,也就是说还是n维,那么就有:
ω
1
z
i
1
+
ω
2
z
i
2
+
.
.
.
+
ω
n
z
i
n
=
x
(
i
)
\omega_1z_{i1}+\omega_2z_{i2}+...+\omega_nz_{in}=x^{(i)}
ω1zi1+ω2zi2+...+ωnzin=x(i)(谨记
x
i
x_i
xi是本体)
这时两边同乘以
ω
1
\omega_1
ω1,考虑到坐标系是标准正交的,就有:
z
i
1
=
ω
1
T
x
(
i
)
z_{i1}=\omega_1^Tx^{(i)}
zi1=ω1Tx(i)所以每一个坐标都可以这样求出。
OK接着上面说,知道新坐标系中的新坐标怎么求之后,就可以基于新坐标系来重构样本点,也就是我口中的数据的本体,新的本体为:
x
^
(
i
)
=
∑
j
=
1
d
z
i
j
ω
j
\hat{x}^{(i)}=\sum_{j=1}^{d}z_{ij}\omega_j
x^(i)=∑j=1dzijωj。此时这个本体为什么叫新本体,是因为表达他的坐标系的维度已经发生了变化,从原来的n维降低成了d维,所以本体也发生了变化。我们所希望的是原来的本体与重构的新本体之间的距离尽可能的小,我们可以先列出两者之间的距离公式:(下面W代表新坐标系的轴向量组成的矩阵,标准正交矩阵的逆矩阵和转置相同)
∑
i
=
1
m
∣
∣
∑
j
=
1
d
z
i
j
ω
j
−
x
(
i
)
∣
∣
2
2
=
∑
i
=
1
m
∣
∣
W
z
i
−
x
(
i
)
∣
∣
2
2
=
∑
i
=
1
m
(
W
z
i
)
T
(
W
z
i
)
−
2
∑
i
=
1
m
(
W
z
i
)
T
x
(
i
)
+
∑
i
=
1
m
x
(
i
)
T
x
(
i
)
=
∑
i
=
1
m
z
i
T
W
T
W
z
i
−
2
∑
i
=
1
m
z
i
T
W
T
x
(
i
)
+
∑
i
=
1
m
x
(
i
)
T
x
(
i
)
=
∑
i
=
1
m
z
i
T
z
i
−
2
∑
i
=
1
m
z
i
T
z
i
+
∑
i
=
1
m
x
(
i
)
T
x
(
i
)
=
−
∑
i
=
1
m
z
i
T
z
i
+
∑
i
=
1
m
x
(
i
)
T
x
(
i
)
=
−
t
r
(
W
T
(
∑
i
=
1
m
x
(
i
)
x
(
i
)
T
)
W
)
+
∑
i
=
1
m
x
(
i
)
T
x
(
i
)
=
−
t
r
(
W
T
X
X
T
W
)
+
∑
i
=
1
m
x
(
i
)
T
x
(
i
)
\sum_{i=1}^{m}||\sum_{j=1}^{d}z_{ij}\omega_j-x^{(i)}||_2^2=\sum_{i=1}^{m}||Wz_i-x^{(i)}||_2^2\\=\sum_{i=1}^{m}(Wz_i)^T(Wz_i)-2\sum_{i=1}^{m}(Wz_i)^Tx^{(i)}+\sum_{i=1}^{m}x^{(i)T}x^{(i)}\\=\sum_{i=1}^{m}z_i^TW^TWz_i-2\sum_{i=1}^{m}z_i^TW^Tx^{(i)}+\sum_{i=1}^{m}x^{(i)T}x^{(i)}\\=\sum_{i=1}^{m}z_i^Tz_i-2\sum_{i=1}^{m}z_i^Tz_i+\sum_{i=1}^{m}x^{(i)T}x^{(i)}\\=-\sum_{i=1}^{m}z_i^Tz_i+\sum_{i=1}^{m}x^{(i)T}x^{(i)}\\=−tr(W^T(∑_{i=1}^{m}x^{(i)}x^{(i)T})W)+∑_{i=1}^mx^{(i)T}x^{(i)}\\=-tr(W^TXX^TW)+\sum_{i=1}^{m}x^{(i)T}x^{(i)}
i=1∑m∣∣j=1∑dzijωj−x(i)∣∣22=i=1∑m∣∣Wzi−x(i)∣∣22=i=1∑m(Wzi)T(Wzi)−2i=1∑m(Wzi)Tx(i)+i=1∑mx(i)Tx(i)=i=1∑mziTWTWzi−2i=1∑mziTWTx(i)+i=1∑mx(i)Tx(i)=i=1∑mziTzi−2i=1∑mziTzi+i=1∑mx(i)Tx(i)=−i=1∑mziTzi+i=1∑mx(i)Tx(i)=−tr(WT(i=1∑mx(i)x(i)T)W)+i=1∑mx(i)Tx(i)=−tr(WTXXTW)+i=1∑mx(i)Tx(i)最后一步是把代数表达成了矩阵形式,其中tr表示矩阵的迹,即主对角线之和。最后一项中右边项是个常数,所以我们只需要最小化左边项即可。所以PCA的优化目标为:
m
i
n
W
−
t
r
(
W
T
X
X
T
W
)
s
.
t
.
W
T
W
=
I
\underset{W}{min}-tr(W^TXX^TW)\\s.t. \ \ \ W^TW=I
Wmin−tr(WTXXTW)s.t. WTW=I其中
X
X
T
XX^T
XXT是协方差矩阵,我们知道协方差是表示两个变量之间相关性的一个量,当这两个变量相同时就变成了协方差的特殊情况——方差。协方差矩阵的主对角线就是方差值,这里是不是看到了一丝基于最大可分性原理的意思,接下来就看一下基于最大可分性怎么推导。
基于最大可分性
基于最大可分性就非常简单了,最大化降维后数据的方差即可。最大化方差,简写就是最大化:
m
a
x
z
i
T
z
i
max z_i^Tz_i
maxziTzi因为数据已经经过中心化了,所以此处也不用减去均值,分母是固定的,也可以扔掉。其实能写出这一步就已经和基于最近重构性中推导的公式倒数第三步相同了,继续推导下去可以得到:
m
a
x
W
t
r
(
W
T
X
X
T
W
)
s
.
t
W
T
W
=
I
\underset{W}{max} \ tr(W^TXX^TW)\\s.t\ \ W^TW=I
Wmax tr(WTXXTW)s.t WTW=I
此时两种方法可谓殊途同归,简直完美。
上述说的头头是道,看似很有道理,但如果细心点还是可以发现问题。我们就抛出两个问题:
1、新坐标系中丢弃掉的坐标如何进行选择?也就是说怎么决定哪些丢哪些留着?
2、公式推导虽然完全成立,但明明有更简洁的表示方法,在公式最后为什么要转化成矩阵的迹来表示?
带着这两个问题我们来看一下它的求解过程。
求解
我们对目标函数使用拉格朗日乘子法,可以得到:
F
(
W
)
=
t
r
(
W
T
X
X
T
W
+
λ
(
W
T
W
−
I
)
)
F(W)=tr(W^TXX^TW+\lambda(W^TW-I))
F(W)=tr(WTXXTW+λ(WTW−I))对W进行求导得:
X
X
T
W
+
λ
W
=
0
XX^TW+\lambda W=0
XXTW+λW=0转换一下形式就可以得到:
X
X
T
W
=
(
−
λ
)
W
XX^TW=(-\lambda)W
XXTW=(−λ)W是不是非常像线性代数中的特征值和特征向量的关系形式。剩下的步骤按照线性代数中求特征值和特征向量的操作来就行。这下我们明白了第二个问题的答案,表达成矩阵的迹就是为了进而转换成求矩阵的特征值和特征向量的形式,这样方便了求解。
对于第一个问题,在线性代数中说过,矩阵特征值的和等于矩阵主对角线元素的和,也就是说特征值的和就是矩阵的迹。退回我们推出的目标函数,最大化矩阵的迹,也就是最大化特征值的和。(
W
T
X
X
T
W
W^TXX^TW
WTXXTW与
X
X
T
XX^T
XXT相似,相似矩阵的迹相同)
经过上述分析,PCA降维的过程就变得非常清晰了,就是求协方差矩阵特征值和特征向量的过程。
降维后低维空间的维数一半由用户事先定好,或通过在维度不同的低维空间中对k近邻分类器(或是其他开销较小的学习器)进行交叉验证来选取较好的维数。对于PCA,出了事先定好低维的维数,还可以从重构的角度设置一个重构阈值,例如
t
=
95
%
t=95\%
t=95%,然后选取使下式成立的最小维数:
∑
i
=
1
d
λ
i
∑
i
=
1
n
λ
i
≥
t
\frac{\sum_{i=1}^{d}\lambda_i}{\sum_{i=1}^{n}\lambda_i}\geq t
∑i=1nλi∑i=1dλi≥t
PCA降维后必然会使数据损失一部分东西,它的优点是:
1、舍弃部分信息后会使样本的采样密度增大,这正是降维的重要动机。
2、当数据收到噪声影响时,最小特征值对应的特征向量往往与噪声有关,将他们舍弃能在一定程度上起到降噪效果。
3、仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
4、各主成分之间正交,可消除原始数据成分间的相互影响的因素。
5、计算方法简单,主要运算是特征值分解,易于实现。
缺点:
1、当然,降维后由于维度降低,表达数据的方式与原数据差异很大,降维后的数据的特征,将不具有可解释性。(也就是说完全不知道降维后每个维度的物理意义是啥)
2、而方差小的非主成分也有可能是造成样本差异的重要信息,丢弃后可能会对后续数据处理有影响
tips:
1、上面讲的是线性的情况,但大多数情况下数据往往不是线性的,不能直接用上述方法进行降维。这里引入核函数,就类似于SVM中,把数据映射到高位线性可分的空间,然后再进行降维。
使用了核函数的主成分分析成为核主成分分析(KPCA)。假设高维空间的数据是由n维空间的数据通过映射
ϕ
\phi
ϕ产生,那么之前的结果就变为:
∑
i
=
1
m
ϕ
(
x
i
)
ϕ
(
x
i
)
T
W
=
λ
W
\sum_{i=1}^{m}\phi(x_i)\phi(x_i)^TW=\lambda W
i=1∑mϕ(xi)ϕ(xi)TW=λW
通过在高维空间进行协方差矩阵的特征值分解,然后用和PCA一样的方法进行降维。一般来说,映射
ϕ
\phi
ϕ不用显式的计算,而是在需要计算的时候通过核函数完成。由于KPCA需要核函数的运算,因此它的计算量要比PCA大很多。
2、降维后的低维维数要求比样本数少。
简单来说,就是确定一直线至少需要两点,确定一平面至少需要三点,确定n维空间至少需要n点。Pca是将原数据投影到新的空间,因此对于样本数n来说,最多确定n维空间。
举个极端的例子,将一个二维的样本降为一维,那么任何穿过此样本的直线都可以使得投影误差最小,此时降维便失去了意义。















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









