







一、Spark的运行机制:
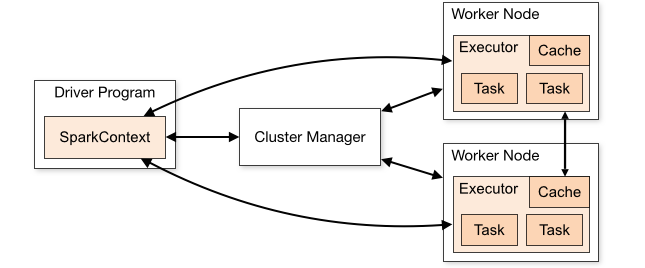
一个Spark应用包含两个部分:
(1) Driver Program(一个):里面包含最重要的SparkContext。
(2)Executor(多个):一个里面包含多个Task(任务)和Cache(缓存)。
1、构建Spark Application运行环境
在Driver Program中新建SparkContext(包含sparkcontext的程序成为Driver Program);Spark Application运行表现方式为:在集群上运行一组独立的excutor进程,这些进程有sparkcontext来协调。
2、SparkContext向资源管理器申请运行Executor资源,并启动standaloneExecutorBackend,executor向SparkContext申请Task。集群通过SparkContext链接到不同的cluster manager(standalone,yarn,mesos),cluster manager为运行应用的Executor分配资源,一旦建立连接后,Spark每个Application就会获得各个节点上的Executor(进程);每个Application都有自己独立的executor的进程,Executor才是真正运行在WorkNode上的工作进程。他们为应用计算或者存储数据;
3、SparkContext获取到executor之后,Application的应用代码将会发送到各个executor;
4、SparkContext构建RDD DAG图,将RDD DAG分解成Stage DAG图,将Stage提交给TaskScheduler,最后由TaskScheduler将Task发送到Executor运行。
5、Task在Executor上运行,运行完毕后释放所有资源。
二、Spark核心集群的概念

















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









