







 博客探讨了一个在数据库中由于`use_concat`特性引发的性能问题,该问题导致优化器错误估算内层循环次数,从而选择了一个高代价的执行计划。在分析中,作者发现优化器未对临时表`MIDS_BLOCK_ARTILIST_MORE_TEMP2`使用动态采样,导致估算错误。通过设置`optimizer_dynamic_sampling`和调整SQL提示,如`no_expand`,作者揭示了`use_concat`在特定情况下的动态采样行为,并提出了收集临时表统计信息作为解决方案,以避免性能问题。
博客探讨了一个在数据库中由于`use_concat`特性引发的性能问题,该问题导致优化器错误估算内层循环次数,从而选择了一个高代价的执行计划。在分析中,作者发现优化器未对临时表`MIDS_BLOCK_ARTILIST_MORE_TEMP2`使用动态采样,导致估算错误。通过设置`optimizer_dynamic_sampling`和调整SQL提示,如`no_expand`,作者揭示了`use_concat`在特定情况下的动态采样行为,并提出了收集临时表统计信息作为解决方案,以避免性能问题。
数据库版本:10.2.0.4
一个系统上cpu使用偏高,awr报表表现为逻辑读偏高和大量的hash latch争用,最后得到是因为一些类似的sql语句引发的,这个系统里的sql是拼装起来的,没有使用绑定变量(当然这里有没有使用绑定变量不是引发性能问题的根源,这里就不说了),所以sql并不完全相同,但大致形式是一样的,我测定了一下一个捕捉到的sql语句,为了标识到底是哪里消耗了过多的逻辑io,我在执行sql语句前,在会话中设置statistics_level=all,然后使用SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(null,null,'ALL IOSTATS LAST'));查看真实的执行计划和执行时的统计信息如下:
只保留必要的信息之后,执行计划和统计信息是这样的:(执行计划A)
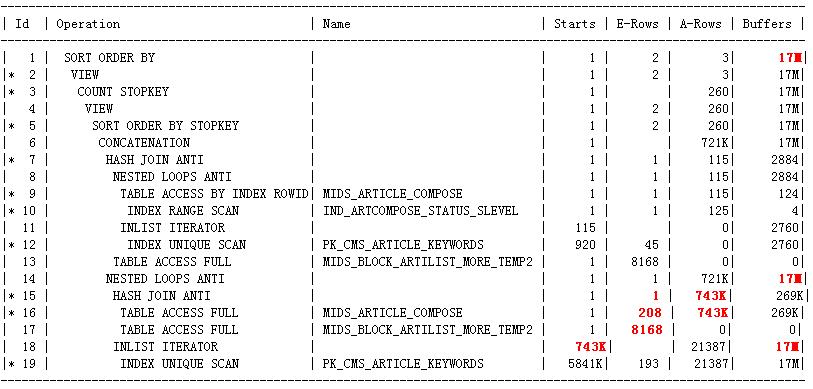
这里给出的执行计划和awrsqrpt.sql生成的执行计划是完全一样的.
从执行统计信息可以看到,这里的逻辑读高达1700W多,本质上是因为18,19步的高逻辑IO导致的,而这里逻辑IO这么高是因为作为nl_aj的内层循环,这里执行的次数太多了:74.3W次,为什么这么高代价的执行计划还要被选择上,是因为优化器估算的时候,认为nl_aj的内层循环只会执行一次,也就是说优化器估算步骤14执行的nl_aj的驱动结果集(也就是步骤15返回的结果集)只有1行,但实际上它却返回了74.3W行导致的.所以这里需要调查步骤15为什么实际返回了74.3W行,但却估算只返回了1行?实际上步骤16,17的card估算都存在问题.
把执行计划中步骤16的filter谓词单独的应用于MIDS_ARTICLE_COMPOSE后,它估算返回335K,和实际执行时返回743K是一个数量级上的了,远不像现在这样同样的filter子句却只估算返回208行这样偏离实际情况,这个需要调查一下.还有步骤17中MIDS_BLOCK_ARTILIST_MORE_TEMP2这个temporary table上没有收集优化器统计信息,但在optimizer_dynamic_sampling=2时应该使用动态采样发现实际上它是一个空表,所以这里的card应该是1的呀,为什么却是临时表的默认的card 8168呢,所以这里应该是没有使用动态采样的,可执行计划的note部分明明提示:- dynamic sampling used for this statement的呀,这里为什么没有使用动态采样也需要调查一下. 200多行的数据不在8000多行的数据里,得出1行的结果集,似乎是合理的,但也要调查一下.
于是做了一个10053事件.
先说步骤16只估算返回208行数据的问题:
Table: MIDS_ARTICLE_COMPOSE Alias: A
Card: Original: 2626 Rounded: 208 Computed: 207.58 Non Adjusted: 207.58
从表统计信息部分看,这个表的统计信息没有问题,是200多W行数据,可到了这里,原始估算却只有2626行数据了,这应该是导致最终这里只估算返回208行数据的根源.可为什么是这个2626行数据呢?!似乎又和这里的rownum<=n这个有关.在这个card内容的上面就是SINGLE TABLE ACCESS PATH (First K Rows).
sql语句最后部分是这样的:
order by a.DISPLAY_TIME desc nulls last) a
where rownum <= 260)
where r >= 258
order by r;
(这里不去说为什么这里使用了nulls last)
我这里修改where rownum<=n 这里的n值,步骤16估算的card是随这里n值的增大或者是减小而同步变化的.
我在最外层的select中添加了/*+ all_rows*/的提示后,执行计划变了(sql中有两部分的or,一个or部分是字段A上的一个or,另一个or部分是字段B上的两个or,执行计划由原来的一个or的use_concat变成了两个or的use_concat)(在里面任何一层的select部分添加/*+ all_rows*/这样的提示都不改变现有的执行计划的),但是现在的执行计划B和原来的执行计划A还是有相似之处的,只保留必要的信息之后,执行计划和统计信息是这样的:(执行计划B)
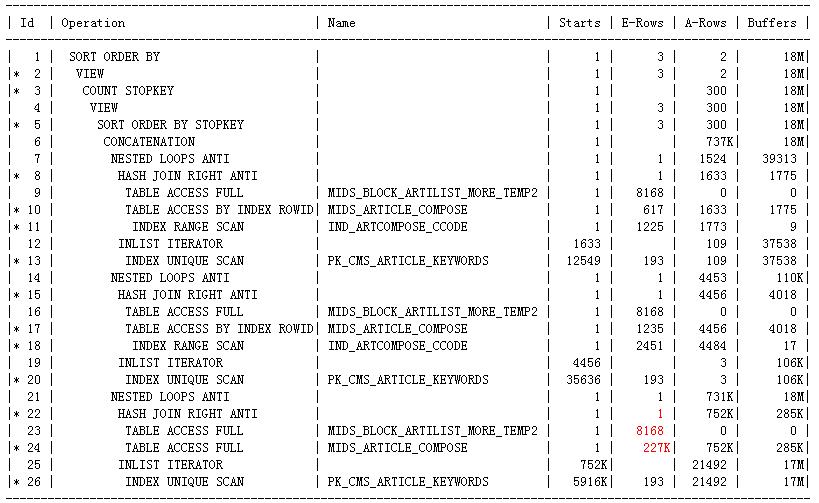
我这里再改变rownum<=n 这里的n值,无论改变程度有多大,步骤10,17,24估算的card都不再改变了,而且我这里select * from MIDS_ARTICLE_COMPOSE a where 只单独应用步骤24的filter谓词之后,估算返回的card和这里估算的card是完全相同的,远不像执行计划A中同样的应用却是完全不同的.这说明执行计划A中rownum<=n确实在一定程度上触发了first_rows(n)这样的优化器模式.但这里有两个疑问:1.除了rownum<n 这样的谓词之外,还需要什么样的条件才会触发first_rows(n)这样的优化器模式,因为你会发现并不是查询中含有rownum<=n这样的谓词就一定会触发first_rows(n)优化器模式的,我想要在自己的模拟测试中再现这一点,可就是再现不了,这说明除了rownum<n这样的谓词之外应该还需要其它的一些必要条件才会触发first_rows(n),但这样的触发条件是什么呢?这样的触发条件是否总是合适的?就像我下面要说的一样,如果它是在一定的条件下触发的,那它可能就不是完全基于代价的,那么就可能选择糟糕的执行计划,就像这里一样,虽然这里实际是分页取某个页面的数据,但实际上它必须得到整个候选结果集之后才可以取这个页面的数据的,所以它应该是all_rows,而不应该是first_rows(n)的 2.first_rows(n)(当然也包括all_rows)这些优化器模式是什么阶段确定下来的,它们是否是完全基于代价的?我的意思是说:明显你可以看到first_rows(n)下,计算出的card会很小,相应的执行计划的cost也会很小,这样all_rows下的执行计划和这些first_rows(n)下的执行计划明显是不具有可比性的,因为all_rows下的执行计划很可能cost要比它高,注定是要被淘汰掉的.这样它们就不是完全基于代价的了,那first_rows(n)还是all_rows这样的优化器模式是什么时候确定下来的呢?如果说first_rows(n)得到一批执行计划,all_rows下得到一批执行计划,然后选择cost最低的,可就像我前面说的那样,这样的情况下,first_rows(n)的cost显然是要比同等情况下的all_rows的cost要低,几乎是注定要被选择的,所以我感觉似乎是在硬分析一开始的某个阶段在比较执行计划的cost之前就确定了要使用某种优化器模式的,然后才开始比较各个可行的执行计划的cost的.那它就不是完全基于代价的了,就是某些规则下使用first_row_n,某些规则下使用all_rows了,在这样的基调下才去比较各个执行计划了,是这样吗?(虽说first_row_n下的执行计划和all_rows下的执行计划的可选集合是完全一样的,不同模式下的执行计划不具有可比性了,但同一模式下的执行计划还是具有可比性的嘛)还有就是first_rows(n)这里的n是如何确定的呢? 不知道我这里表达清楚没有,其实这种想法在以前的博文中记录rownum引发的类似的问题时就产生这样的想法了.
再说连接的结果集估算为1的情况:
从执行计划B中步骤22,23,24比对执行计划A,你会感觉其实执行计划A中因为rownum的问题导致步骤16估算只返回208行还不是步骤15估算只返回1行数据的根源,因为你发现执行计划B中步骤24估算返回22.7W行数据了,可最终步骤22还是估算返回1行数据,实际上它返回了75.2W行数据.如果说208行数据不在8168行数据里估算返回1行数据还算正常的话,那么22.7W行数据(关键是这里的id是有主键约束的)不在8168行数据里仍然估算返回1行数据,总觉得就有点儿说不过去了吧.所以这里还是需要调查一下了,这里的相应的sql部分是这样的:
from mids_article_compose a where a.id not in (select id from mids_block_artilist_more_temp2 t)
其中id是表mids_article_compose的主键,mids_block_artilist_more_temp2中的id没有主键约束(其实也是不重复的),但要求是非空的.
执行计划A的步骤15只估算返回1行数据,从10053文件来看是这样得来的:
Anti Join Card: 0.00 = outer (207.58) * (1 - sel (1)) --为什么是这样一个结果呢?sel(1)是如何得来的呢?这里当然没有给出sel(1)是如何得来的
Join Card - Rounded: 1 Computed: 0.00
Best:: JoinMethod: HashAnti
Cost: 79.16 Degree: 1 Resp: 79.16 Card: 0.00 Bytes: 840
同时需要引起注意的一点是:
>>> adjusting AJ/SJ sel based on min/max ranges: jsel=min(0.93269, 0.23308)
Anti Join Card: 159.20 = outer (207.58) * (1 - sel (0.23308)) --这个为什么被抛弃了呀?
Best:: JoinMethod: HashAnti
Cost: 69.99 Degree: 1 Resp: 69.99 Card: 159.20 Bytes: 842 --为什么被抛弃了呀?显然不是因为cost,因为它的cost更小
执行计划B的步骤22只估算返回1行数据,从10053文件来看是这样得来的:
Anti Join Card: 0.00 = outer (227642.69) * (1 - sel (1))
Join Card - Rounded: 1 Computed: 0.00
Best:: JoinMethod: HashAnti
Cost: 49905.19 Degree: 1 Resp: 49905.19 Card: 0.00 Bytes: 881
同样需要引起注意的一点是:
Anti Join Card: 227448.68 = outer (227642.69) * (1 - sel (8.5225e-04))
Join Card - Round
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









