









Bloom Filter的出现,使得海量数据搜索的效率提高了非常多,大家针对简单的Bloom Filte存在的各种局限进行分析,从而得到了不同的演化版本,本文针对这些演化版本进行粗略分类与介绍,简要说明各类演化版本的优缺点。
1.Counting Bloom Filter
简单的Bloom Filter中位向量中的各个位由于只有0,1两种数值,而不同的元素经过Hash后可能得到相同的位编号,这样一来多个元素都把该位置的值置为1,这种情况在数据量很大的情况下非常普遍,所以,如果表达的元素集合经常发生删除等变动,那么Bloom Filter的弊端就出来了,因为它不支持删除操作...
Counting Bloom Filter的出现解决了这个问题,它将标准Bloom Filter位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的k(k为哈希函数个数)个Counter的值分别加1,删除元素时给对应的k个Counter的值分别减1,Counting Bloom Filter通过多占用几倍的存储空间的代价,给Bloom Filter增加了删除操作。

上述公式为计算第i个Counter被增加j次的概率,其中n为集合元素个数,k为Hash函数个数,m为Counter
个数(对应着原来位数组的大小),前一部分表示从nk次哈希中选择j次,中间部分表示j次哈希都选中了第i个Counter,后一部分表示其它nk–j次哈希都没有选中第i个Counter,因此,第i个Counter的值大于j的概率可以限定为:

其中的第二次缩放用到了估计阶乘的斯特林公式:

在前面我们提到过k的最优值为(ln2)m/n,现在我们限制k ≤(ln2)m/n,就可以得到如下结论:

如果每个Counter分配4位,那么当Counter的值达到16时就会溢出。这个概率为:

这个值足够小,因此对于大多数应用程序来说,4位就足够了。
2.Spectral Bloom Filter
Counting Bloom Filter将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。一旦位扩展成了counter,每一个counter就不仅能表示这一地址有无映射,还能表示映射的个数。这一扩展使得存储的数据包含了更多信息,然而遗憾的是,CBF仅仅利用这个扩展支持了删除操作,并没有将信息中蕴含的潜力完全挖掘出来。
标准的bloom filter和CBF解决的只是集合元素的membership问题,即判断一个元素是否属于某个集合,但有时我们不但想知道集合中是否存在一个元素,我们还想知道这个元素在集合中的出现次数,例如在一些数据流(data stream)应用中,我们关心的也许不是一个数据元素是否属于某个集合,而是它的出现频率。很自然地,我们希望能从counter中得到这些信息,但是,counter反映的只是映射数,如何将其与集合元素的出现次数关联呢?
在CBF中加入一个元素时,k个哈希位置的counter都要加1,也就是说,如果不考虑碰撞(collision),出现次数为n的元素对应的k个counter的值都为n。即使考虑到碰撞的因素,只要k个位置不全出现碰撞,k个counter中的最小值仍是n。令元素x对应的k个counter的最小值为mx,x的出现频率为fx,从上面的分析我们不难看出,fx ≠ mx的概率和标准bloom filter的false positive概率相同,因为二者出现的充要条件都是k个哈希位置同时出现碰撞。
上面这个结果其实就是SBF的理论基础。SBF扩展了CBF,使得用户不但可以进行membership query,还可以查询集合元素的出现频率。在查询元素x的出现频率时,SBF返回mx,出错的概率和false positive rate相同。注意,由于fx ≤ mx,所以查询的结果即使不准,也可以得到一个上界,而且这个上界和实际值fx一般情况下不会相差太远。
为实现counter的高效存储,我们先简化问题,来看最少需要多少位才能存储所有的counter。假设SBF要表示M个元素的集合(可能包含重复元素),counter数组的长度为m(对应bloom filter的位数组),显然所有counter需要的最少位数N为

其中Ci表示counter数组中第i个counter的大小,即哈希函数映射到第i位的次数。用N位存储counter,其实相当于把所有的counter化成二进制位串然后连在一起。这样当然占用的位数最少,但如何访问长度不一的counter是个大问题。不管怎么样,在不考虑增删操作的情况下,我们想要达到的目标就是在保证查询操作快速的基础上,使得存储位数尽量接近N。
SBF并没有发明什么异乎寻常的高超技巧,和你大概能想到的一样,它构建了一套索引结构。首先SBF将N位的基本位串分成m/log2N段,每一段包含log2N个counter,然后将每一段的offset记下来,offset要占用log2N位,所以记录子串offset的数组(文中叫Coarse Vector)总长度为m位。
有了Coarse Vector,我们就可以随机访问任何一个子串了。这时我们有两种选择,要么把子串继续分成子段,要么将子串中所有counter的offset记下来,子串有长有短,但所含counter个数相同,也就是记录counter的offset数组长度相同,这就意味着把长子串用来记录offset比较划算。SBF规定子串长度超过log3N位的,直接用offset数组记录counter位置,否则再继续分。N位基本位串中最多有N/log3N个长度不超过log3N的子串,所以在这一层所有的offset数组加起来长度最多为N/log3N× (logN ×logN) = N/logN位。
长度不超过log3N位的子串,我们将其再分成loglogN段,每一段包含logN/loglogN个counter。由于offset要占用loglog3N = 3loglogN位,所以整个offset数组总长度为3loglogN×logN/loglogN = 3logN位。这一层所有的offset数组加起来长度最多为m/logN× 3logN= 3m位。
并不是子串的每一个子段都用offset数组来存储counter的位置,和前面一样,仍然只记录较长的子段。假设子段长度为T,这里的阀值设为T0 = (loglogN)3,当T > T0时,子段的counter位置用offset数组记录。由于子段包含loglogN个counter,且每一个offset可以用3loglogN位表示,因此offset数组的长度最多为loglogN× 3loglogN =3(loglogN)2 « T。这一层的所有的offset数组长度加起来也不过O(N)。
现在就剩了T ≤ T0的情况,这时SBF也不继续分了,而是将所有这类情况存储在一个全局查询表里。总之,在不考虑增删操作的情况下,SBF的counter存储所要达到的目标就是只使用O(N) + O(m)位,构建时间为O(m)。通过上面构建的复杂的索引结构,这个目标是达到了。下面我们来看增删操作如何在这样的结构上实现。
我们介绍到SBF将所有counter排成一个位串,counter之间完全不留空隙,然后通过建立索引结构来访问counter。现在我们来扩展这个结构,使之能支持增加和删除操作。删除操作相对来说比较好处理,因为它不会导致存储空间的增加。但是也不能坐视不管,因为大量的删除操作会导致本该释放的空间仍然被占用。SBF采取的策略是,单个删除操作只影响相关的counter,整个存储结构并不更新,但经过一系列连续的删除操作后,整个存储结构会被重建。
增加操作稍微麻烦点,因为它意味着原来分配的存储空间不再够用。SBF采取的应对策略有点像我们平时排工作计划时留buffer的做法。我们在安排工作时,如果一件事估计需要10天才能做完,我们写计划时不会写成刚好10天,因为事态的发展有太多动态变化的因素。我们会在计划里给自己留一点buffer,将10天的工作写成12天。
SBF处理增加操作时也采取相似的策略,它给原本只需要N位的基本位串增加єm(є > 0,m为counter个数)位的buffer,以应对将来可能出现的增加操作。SBF将这єm位buffer插入到m个counter之间,每1/є个counter增加1位buffer。当某个counter需要更多位数时,它就找离自己最近的buffer位。如果找到的buffer位就在自己的尾部,就直接用掉它;如果隔了一个或几个counter,它就将隔的这几个counter往后“推”,然后使用腾出来的buffer位。最后,counter移动之后,别忘了索引结构也需要更新。
总而言之,SBF是一种扩展版的Counting Bloom Filter,它不仅支持membership query,还支持元素在multi-set中的出现频率查询。实际上,前者只是后者的一种特例,membership query无非是元素出现频率为1的查询。元素出现频率用k(哈希函数个数)个counter中的最小值来近似表示。这种近似使得一个元素对应的k个counter中,最小的那个比其它的更有价值。
3.Dynamic Count Filter
Spectial Bloom Filter在Count Bloom Filter的基础上提出了元素出现频率查询的概念,将CBF的应用扩展到了multi-set的领域。但是,SBF为解决动态counter的存储问题,引入了复杂的索引结构,这让每个counter的访问变得复杂而耗时,有没有一种解决方案既支持元素出现频率查询,结构又相对比较简单呢?Dynamic count filter(DCF)尝试回答了这个问题。
要支持元素出现频率查询,就需要解决变化范围可能很大的counter的存储问题。DCF和SBF的不同之处,也就是counter的存储结构。DCF使用两个数组来存储所有的counter,它们的长度都为m(即bloom filter的位数组长度)。第一个数组是一个基本的CBF(即下图中的CBFV,counting bloom filter vector),counter的长度固定,为x = log(M/n),其中M是集合中所有元素的个数,n为集合中不同元素的个数。第二个数组用来处理counter的溢出(即下图中的OFV,overflow vector),数组每一项的长度并不固定,根据counter的溢出情况动态调整。假设OFj是OFV中某一项的值,那么OFV中每一项的长度y = floor(log(max(OFj))) + 1,即最大值决定了每项长度。
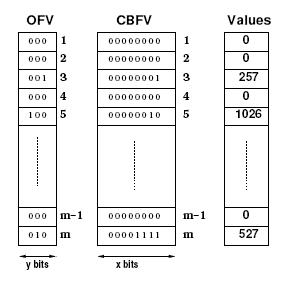
上图中最右一列是counter的值,从图中我们可以清楚地看出OFV和CBFV的作用。比如第5个counter的值是1026,二进制为10000000010。我们把这个二进制位串分成两段100和00000010,分别就对应着OFV和CBFV中的值。图中我们也可以看出x + y就等于counter的最大值的二进制位数。
在查询一个counter时,DCF要求两次内存访问。假设想查询位置为j的counter的值,我们先读出CBFV和OFV的值,分别为Cj和OFj,那么counter的值就可以表示为Vj = (2x ×OFj + Cj)。
在集合增加元素时,如果OFV的最大值从2x – 1增加到2x,OFV就需要给每一项增加1位,否则就会溢出。每次OFV大小改变的时候都需要重建。重建是一件开销很大的工作,必须重新创建一个OFV数组,然后把旧OFV数组的值拷贝到新建的OFV数组中,最后把旧OFV数组的空间释放掉。如果说增加时的overflow必须重建的话,那么集合元素减少时的underflow则有更多选择。当OFV的最大值从2x减少到2x – 1时,我们可以选择马上重建OFV,也可以采用一些策略延迟OFV的重建,以避免一些临时性的减少导致OFV反复重建。
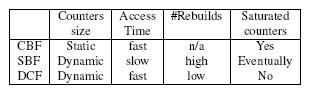
从上面的介绍可以看出,DCF中最大的那个counter决定了整个结构所占的空间。因此,在counter的值普遍不大的情况下,DCF由于不用维护复杂的索引结构,所以占用空间比SBF要少。如果将counter的值逐渐增大,SBF在空间占用上的优势就会越来越明显。在counter存取时间上,DCF占有绝对的优势,只比CBF多访问了一次内存。在不同的实际应用场合中对比SBF和DCF,论文作者发现DCF整体占用的空间以及执行时间都比SBF少了一半还多。最后,我们给出一个将CBF、SBF和DCF定性比较的表格:
参考文献:
Dynamic Count Filterhttp://blog.csdn.net/jiaomeng/article/details/1543751
http://www.sigmod.org/sigmod/record/issues/0603/p26-article-pey.pdf
Count Bloom Filter技术研究及应用newhttp://wenku.baidu.com/link?url=0Djx5syWrKnzmZ8shXtyoBupI1gly4707Gvsl2KpjP2Q4ns1XgZvkBqrpdmeSRISJiqSDsTMwjHd-xChejBcJQpyKdBchk9arvsqGXkefS_

















 7107
7107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









