







集合概述
这篇博客记录 javase 集合相关的内容。javase 集合部分主要有 javase 集合框架相关的内容和 javase 泛型相关的内容。集合是用来做什么的呢,集合主要是用来对现实世界中多个对象在一起进行统一描述的。在现实世界中,常常我们会对多个在一起的对象进行操作描述,比如1000学生的资料,100个用户的资料等等,基本的操作有增、删、改、查。现实中对这些对象的操作通常都是要进行统计相关的操作,比如排序等操作。数组虽然也是对对象的统一描述,在语义上差不多,但是在java语言使用中数组和集合仍有许多不同,数组的长度是固定的,集合的长度是可变的,数组的可以存储基本数据类型和对象,集合只能存储对象,并且他们在 jvm 底层的实现也是不同的,数组在 jvm 中有专门的指令和类型来支持,数组实例中有包含数组长度 length 这个元素的单元。
集合框架中常用类关系图
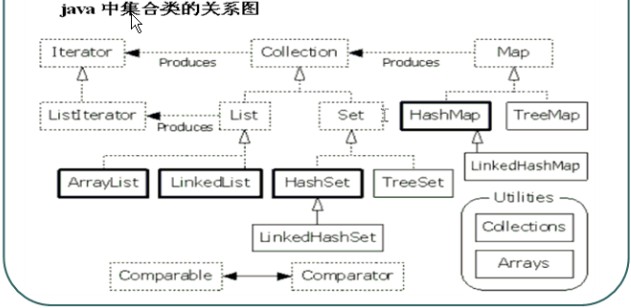
集合框架的子类 ArrayList LinkedList HashSet TreeSet HashMap TreeMap 的主要区别是存储方式(数据结构)不同
Collection 和 Map 的区别是:Collection是单列集合,Map是双列结合,是保存映射关系的集合
List 和 Set 的区别是:List 元素是有序的(存入取出的顺序一致),元素有索引,并且元素可以重复,Set 元素是没有序的,元素没有索引,并且元素不能重复。
Collection <E> 中的共性关系
增:
删:
查:
iterator() 遍历集合,获取集合中的元素的引用
Iterator 接口,迭代器是用于取出集合中的元素,这里迭代器类和集合类是相互依赖的关系,在创建迭代器对象的时候,需要传一个集合类对象的引用,迭代器才能知道遍历那个对象。而且具体的迭代器对象遍历集合类的方法依赖于具体的集合类的数据结构,每个集合类中的迭代器是典型的内部类的例子,把每个集合中迭代器共性抽取出来就有了 Iterator 接口。Iterator 和 Collection 的是典型的双向关联关系。
hasNext() 判断是否有下一个元素
next() 获取元素
remove() 移除元素
Iterator 接口的实现都是在 Collection 子类的内部,是内部类,迭代器使用注意,在迭代过程中不可以使用集合的对象的方法来操作对象。
List <E> 集合的共性关系
增:
删:
remove(int index) 删除指定索引位置的元素
改:
查:
listIterator(int index) 获取指定位置开始的 List 的 ListIterator
subList(int fromIndex, int toIndex) 返回子 List
总结:凡是可以操作角标的方法都是 List 中特有的方法
Listiterator 接口
ListIterator 和 Iterator 的区别主要是, Iterator 只能进行单向迭代,只能进行删除操作,ListIterator 运行双向迭代 和 索引的迭代,并且可以在迭代过程中添加、删除、修改元素
hasNext()
hasPrevious()
hasPrevious()
next()
nextIndex()
previous()
previousIndex()
add()
remove()
set()
ArrayList:底层使用的是数组数据结构,特点是查询和修改速度快,增删比较慢,线程不同步
LinkedList:底层使用的是链表数据结构,特点是增删速度很快,查询和修改速度较慢
Vector:底层是数组数据结构。Vector 是线程同步的。被 ArrayList 替代。Vector 中的 Enumeration 接口的实现,和 Iterator 接口功能是重复的。
LinkedList 特有的方法
addFirst() push
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









