






7.2 我们机房断网了!–图文解析
原文链接:https://juejin.cn/post/7399569706183049250
原文作者:哔哩哔哩技术团队
1、背景
原文:
2024 年 7 月 2 日 10:04,我站机房 A 公网物理光缆中断,导致机房 A 公网无法访问。本文将从 DCDN 架构及多活治理的视角,分析本次故障中我们发现的问题和治理优化措施。


解析:
DCDN是什么?
了解DCDN之前首先要了解什么是CDN.
参考文章链接:https://blog.51cto.com/u_15284125/2985839
CDN 是Content Delivery Network的缩写,翻译为内容分发网络,主要场景是静态资源的下发。常见场景:
- 你的服务器在中国,如果美国用户访问就会有较高的网路延迟。也就是说距离服务器较远的用户访问资源延时较高。CDN会根据请求用户的IP匹配对应的节点返回数据,缓解网络延迟问题。
- 带宽瓶颈,大量用户访问静态资源(图片,视频,css等)导致的服务器带宽拥塞。比如你的服务器上存了一个视频,然后同时有几十个用户来看,对于一般网络配置的服务器都是受不了的。CDN会把静态资源(图片,视频,css等)搬离服务器,作为外部链接放在其他节点上,让主服务器去引用即可。
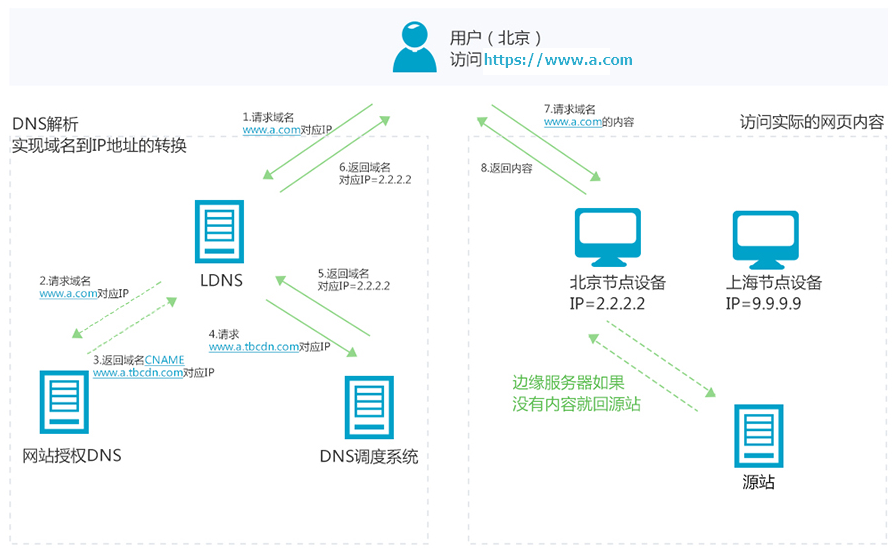
从这张图可以看到CDN的一个工作流程。
左侧方框里面是域名解析流程,CDN服务会根据你的IP定位,返回一个与你邻近的CDN节点IP。
右边方框可以看到DNS返回了北京节点的IP给北京的用户。用户无须访问可能更长路由的源站,这样就解决了上面提出的第一个延迟高的问题。
右侧方框是内容下发流程,得到上面的IP之后用户会去对应CDN节点获取资源,如果当前节点(边缘服务器)存在这个资源则直接返回。如果不存在或已经过期CDN节点会先向源站(也就是你的资源存储的地方)下载这份资源再返回,这个向源站请求资源的过程被称作回源请求。自此这个边缘节点就缓存了这份资源,在有效期内如果有其他北京用户来访问则直接由边缘节点响应而无须回源。
边缘服务器:可以简单理解为距离请求用户最近的服务器。
CDN里还有一个问题,就是访问源站,源站距离我们的CDN节点较远或者网络状态不好,依然会发生高延时问题,所以可以采用DCND来解决。
DCDN:阿里云的动态路由+CDN服务(Dynamic Route for Content Delivery Network)。
通过下图我们可以了解到:边缘节点不会直接访问源站,而是请求延迟最低的加速节点,加速节点又会继续请求下一个延迟最低的加速节点直到到达源站。这些节点又被成为专线节点,是额外投资请专业人员维护管理的,非常稳定。与之对应的是公网节点,走的是公共互联网,由于是公共的,所以期间发生一些问题我们无法预知,优点是便宜,方便。
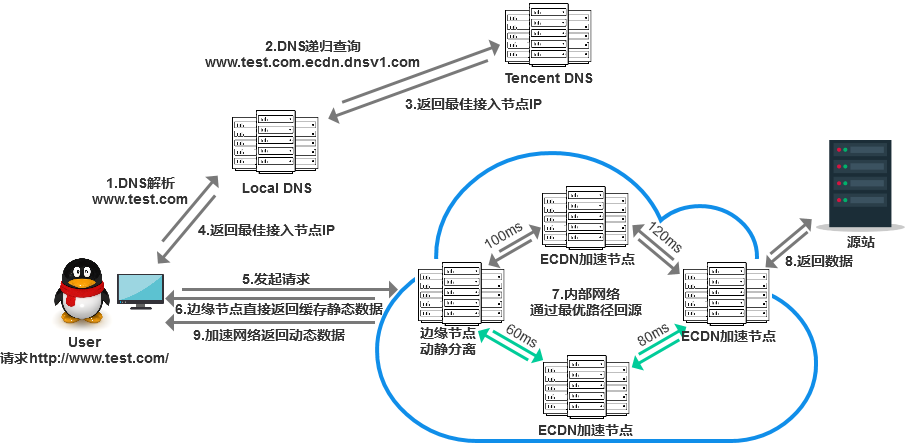
2、止损过程
故障发生后,SRE(网站可靠性工程师Site Reliability Engineer)与网工接收到大量专线中断、公网探测告警。于是赶紧拉起线上会议协同进行故障定位及止损操作;
在此期间核心业务(如首页推荐、播放等)因在 DCDN 侧配置了源站机房级别自动容灾生效(配置了多个源站机房,都处于存活状态,一个机房出现问题,另一个立即接受所有流量继续提供服务),未受影响;
首先定位到的是单个运营商线路存在大量丢包异常,优先将该运营商用户流量切向具有专线回源的 CDN 专线节点,此时这部分用户流量恢复,但整体业务未完全恢复;
继续定位到整个机房 A 公网完全无法访问,而从机房 B 核心业务场景因自动容灾生效存在流量上升且观测业务 服务级别目标 (SLO)正常,决策执行全站多活业务切流至机房 B 止损。此时多活业务完成止损,非多活业务仍有损;
继续对非多活业务流量执行降级,将用户流量切向 CDN 专线节点回源,此时非多活业务流量完成止损。
名词解析:
服务级别目标 (SLO):约定好的要测量的内容能够达标,比如请求成功率,读取成功率等。
切流:本文指的是切换机房或者切换CDN节点的流量,简单说就是机房A挂了,则把原来流向机房A的流量都切换到机房B.
多活指的是数据中心在不同地理位置的多个数据中心同时提供服务,确保业务的连续性和高可用性。这种部署方式允许数据在多个地点实时同步,使得用户无论在哪个数据中心访问,都能获得一致的服务体验。多活架构通常涉及复杂的系统设计和高度可靠的技术实现,以确保数据的一致性和系统的可用性。例如,青云提供的多活服务,通过“两地三中心”的方式,至少需要考虑到城市、机房、光纤、网络等基础设施层面的支持,以保证服务的稳定运行。
非多活则是指数据中心没有实现多活架构,可能只有一个主数据中心提供服务,而其他数据中心仅作为备份或灾难恢复使用。在这种模式下,如果主数据中心发生故障,备份数据中心可以接管服务,但用户可能会经历短暂的服务中断,直到备份数据中心能够完全接管并恢复服务。非多活架构相对简单,成本较低,但牺牲了一定的服务连续性和高可用性
3、问题分析

图1:南北向流量架构图 / 0702故障逻辑图
先简单介绍一下 B 站源站架构,从上图1可以看出,B 站在线业务有两个核心机房,每个机房都有两个互联网接入点(公网 POP ),且这两个互联网接入点分布在不同的省市。这样设计的核心思路:网络接入(以下统称为 POP )和算力中心(以下统称为机房)解耦,达到接入层故障可容灾的效果。
POP:Point of Presence,接入点。
接入层故障: 指的是 B 站在线业务中网络接入层面出现的问题,比如两个核心机房的互联网接入点(公网 POP )或者其相关部分发生了故障。
常规检测是检测POP,公网POPA挂了会检测POPB,如果B没事就切流过去,但这次是机房挂了。常规双 POP 之间互相容灾方案无法生效。非自动容灾的多活业务需要执行机房维度切流进行止损。由于DCDN 专线节点可以通过 B2-CDN 环网专线回源不受本次故障影响,最终成为了非多活业务的逃生通道。

图2为B2-CDN 环网,目的是增加业务从边缘节点回核心源站获取数据的途径。图中的源站彼此相连,CDN节点通过POP节点实现互通。其实 B2-CDN 环网的设计初衷是为了给各不同级别的自建CDN节点在处理边缘冷流(流量少)、温流(流量正常)、热流时能有更多的手段,以探索更加适合有 B 站业务特征的边缘网络调度方式。B2-CDN 环网底层通过二层 MPLS-VPN 技术实现各节点 Full-Mesh,并在此基础上通过三层路由协议(OSPF、BGP) 实现各节点与源站核心机房之间的互联互通。同时各业务保留通过公网回源核心机房的能力,做为 B2-CDN 环网出现极端故障情况下的兜底回源方案。
MPLS-VPN :
早期的互联网传输,和现在的快递类似,直接写上收件人IP,寄件人IP就可以发出,收件人收到信息后,直接把反馈的信息通过寄件人IP返回即可。后来IP地址不够用了,就搞了一个共享IP地址,分别是:10.0.0.0/8 (包含1600万+IP地址),172.16.0.0/12 (包含100万+ IP地址),192.168.0.0/16 (包含6万+ IP地址)。
如果北京分公司发出信息的电脑和上海分公司收信息的电脑的内网地址都是10.0.0.1,则北京分公司需要把地址通过一个叫做NAT的技术转换成公网地址后传递给上海分公司,后来人们觉得太麻烦了,就搞了一个VPN加密技术,简单说就是在北京和上海两个路由器之间搞了一个加密的高速隧道,直接收发信息,但后来数据量变大,尤其是后来的多机房副本间彼此收发信息进行同步时,数据量非常大,每次发送的单条数据都需要加解密,太慢了,本来就在公共互联网上传输,还要频繁的加密解密处理,于是就搞出了一个MPLS-VPN.简单说就是不在加解密了,而是在发出地址上加一个收获地址的前缀,比如要发到上海机房,上海机房路由器给出一个前缀是8888,则北京的发出时写的收件人地址就是8888:10.0.0.1,上海机房指定的8888路由器接收到信息后,将IP前缀的8888去除后,在发给内网的指定机器即可。
三层路由:主要处理IP协议。
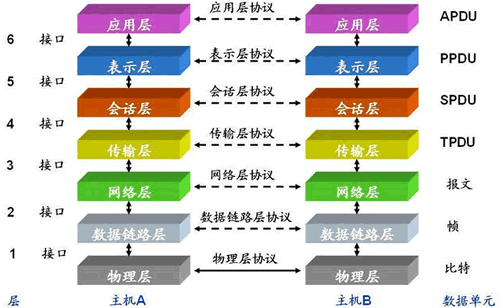
二层路由主要处理物理mac地址,三层为网络层,主要处理IP协议。
4、优化措施
1.提升扩容DCDN节点的算力,提高其承载力,一旦发现机房出现问题,直接从DCDN层进行切流,直接访问专线节点。
2.对于已经到达出问题的公网POP的流量,可以快速切流到专线POP节点。
3.优化上报告警链路。

图3:DCDN流量调度架构:日常态 / 容灾态
多活建设持续推进及常态化演练

图4:同城多活架构简图
图中的名词解释:
四层负载均衡器:位于网络层(IP 层)和传输层(TCP/UDP 层)进行操作,它根据源 IP 地址、目标 IP 地址、端口号等信息进行流量分发
七层负载均衡器:位于应用层,可根据报文内容(例如 URL、Cookie、主机名)进行流量分发,如常见的 HAProxy、Nginx。
BFF:Backend For Frontend,用中文解释就是服务于前端的后端。类似b站这种多类型客户端系统,前端可以是PC浏览器端,小程序端,Android/IOS客户端,可以通过创建一个bff架构,统一处理api,以及对应的鉴权等功能。
bff层参考图,来自:https://cloud.tencent.com/developer/article/1518564
service: 服务层,泛指一个个的微服务。
proxy:本文中的数据库一定是集群实现的,需要用一个数据库proxy对其进行负载均衡,高可用等处理。
db/kv:泛指关系型数据库与kv数据库。
DTS:时钟同步技术
MQ:消息队列
JOB:定时任务,个人理解在框架中存在的两种可能:1,定时检查缓存更新状况。2.这个定时任务本身就是MQ的延时消息。
consumer的三种消费方式:Kafka消费模式主要有三种:点对点(Point-to-Point)、发布/订阅(Publish/Subscribe)和流处理
流处理模式则更注重于对数据的实时处理和分析

在读一下原文,应该能看懂了:
-
接入层:
-
DCDN:南北向流量管控,基于用户纬度信息Hash路由至不同可用区的源站机房,支持可用区维度自动容灾;
-
七层负载/API网关:南北向流量管控,支持接口级别路由、超时控制、同/跨可用区重试、熔断、限流&客户端流控等;
-
服务发现/服务治理组件:东西向精细流量管控,框架 SDK 支持同可用区内优先调用,服务、接口级别流量调度;
-
缓存层:主要为 Redis Cluster、Memcache,提供 Proxy 组件供接入,不支持跨可用区同步,需双可用区独立部署;通过订阅数据库Binlog维护数据最终一致性,同时对于纯缓存场景需要改造;
-
消息层:原则上可用区内封闭生产/消费,支持 Topic 级别消息跨可用区双向同步,Local/Global/None 三种消费模式适配不同业务场景;
-
数据层:主要为 MySQL、KV 存储,主从同步模式;提供 Proxy 组件供业务接入,支持多可用区可读、就近读、写流量路由至主、强制读主等;
-
管控层:Invoker 多活管控平台,支持多活元信息管理、南北向/东西向切流、DNS 切换、预案管理、多活风险巡检;
机房级别自动容灾
对于用户强感知的场景涉及的核心服务,在DCDN侧配置源站机房级别的容灾策略,应对单个源站机房入口故障时可以自动将流量路由至另一个机房实现止损。
多活业务的自动容灾原先没有默认全配置,优先保障了首页推荐、播放相关等主场景,其余业务场景根据资源池水位情况执行切流。当前我们资源池平均CPU利用率已达35%+,在线业务平均峰值CPU利用率接近50%,我们已经对全站业务切流单机房的资源需求进行梳理,同时多活切流也将联动平台进行HPA策略调整,以及准备资源池的快速弹性预案,确保大盘资源的健康。后续将支持对社区互动、搜索、空间等更多用户强感知场景自动容灾策略配置。在遇到机房级别故障时候无需人工干预,多活业务可直接容灾止损。
HPA策略是Kubernetes中的一个重要组件,用于自动调整Pod的数量以适应工作负载的需求。HPA通过监控Pod的性能指标(如CPU利用率和内存使用量)来决定是否需要增加或减少Pod的数量
pod是什么?
k8s中的最小单元,k8s太过于庞大在这里不再做展开讲解,我们进需要知道以下概念即可:
图片来自:https://www.jianshu.com/p/04ef80b76b6a

1.容器:简单理解为就是一个虚拟机,我们开发好一个项目,部署到服务器中,服务器需要对该项目配置环境,如果对一个服务器部署多个项目,尤其是不同语言的项目以及使用多种不同版本中间件对其进行环境配置的时候,很容易造成环境污染,导致项目的环境配置失败,所以通过docker等技术,把开发好的项目以及项目依赖的相关的库,中间件等元素统一部署到一个容器中,容器和容器之间隔离,互不干扰,这样就可以在一个服务器中部署多个项目并且不会污染服务器环境了。
2.node: k8s中的node中文称作节点,一个node可以简单理解为就是一台物理机,一台服务器。k8s至少需要一个主节点以及多个工作节点。
3.pod:在一个Node中可以部署多个pod,在java领域中,每个pod通常包含一个微服务容器,但有时一个Pod中会包含多个容器,这些容器通常是紧密耦合的,必须一起工作。例如,一个微服务和它的辅助服务(如日志收集器)可以部署在同一个Pod中。这种方式主要用于需要共享资源或紧密协作的场景。
k8s的主要工作之一就是增加弹性,当用户请求量以及计算量特别大的时候,可以考虑通过replicas参数的设置来增加副本的数量,概念类似于网络游戏的多开。
图5:多活业务南北向流量架构:日常态 / 容灾态

非多活流量逃生
部分业务当前是没有多机房多活部署的,仅在一个机房可以处理流量;因此在原来的方案中,这部分非多活业务流量只会回源至机房 A,无法应对机房 A 公网入口故障。如同本次事故中,非多活业务流量无法切流止损,依赖降级走CDN专线节点。
为了应对单机房公网入口、四层负载、七层负载故障等场景,我们计划在DCDN侧为非多活业务规则也配置源站级别自动容灾,在七层负载SLB(Server Load Balancer,负载均衡)实现多机房多集群的路由配置合并统一,确保非多活业务的流量在故障时可进入机房 B 路由至API网关;在API网关侧判断接口是否多活,非多活接口通过内网专线进行流量转发,实现流量逃生。
图6:非多活业务南北向流量架构:日常态 / 容灾态



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









