







处理海量数据六大方法【原文】:
- 分而治之/hash映射 + hash统计 + 堆/快速/归并排序;
- 双层桶划分
- Bloom filter/Bitmap;
- Trie树/数据库/倒排索引;
- 外排序;
- 分布式处理之Hadoop/Mapreduce
【0】从set/map谈起得基本数据结构类型、分类与特点
STL(Standard Template Library):
- 序列容器:vector, list, deque, string.
- 关联容器:set, multiset, map, mulmap, hash_set, hash_map, hash_multiset, hash_multimap
- 其他的杂项:stack, queue, valarray, bitset
- set/map/multiset/multimap都是基于RB-tree之上,所以有自动排序功能;
- hash_set/hash_map/hash_multiset/hash_multimap都是基于hashtable之上,所以不含有自动排序功能;
- 加个前缀multi_无非就是允许键值重复而已;
- set:内部元素唯一,用一棵平衡树结构来存储,因此遍历的时候就排序了,查找也比较快的哦。
- map:一对一的映射的结合,key不能重复
- 适配器其实就是一个接口转换装置,包括容器适配器、迭代器适配器和函数适配器
eg:我们已有的容器(比如vector、list、deque)就是设备,这个设备支持的操作很多,比如插入,删除,迭代器访问等等。
而我们希望这个容器表现出来的是栈的样子:先进后出,入栈出栈等等,
此时,我们没有必要重新动手写一个新的数据结构,而是把原来的容器重新封装一下,改变它的接口,就能把它当做栈使用了。
- "age" : 23 }
- 在MongoDB内,文档(document)是最基本的数据组织形式,每个文档也是以Key-Value(键-值对)的方式组织起来。
一个文档可以有多个Key-Value组合,每个Value可以是不同的类型,比如String、Integer、List等等。
{ "name" : "July", "sex" : "male", "age" : 23 }
标准容器类 说明 顺序性容器 vector 从后面快速的插入与删除,直接访问任何元素 deque 从前面或后面快速的插入与删除,直接访问任何元素 list 双链表,从任何地方快速插入与删除 关联容器 set 快速查找,不允许重复值 multiset 快速查找,允许重复值 map 一对多映射,基于关键字快速查找,不允许重复值 multimap 一对多映射,基于关键字快速查找,允许重复值 容器适配器 stack 后进先出 queue 先进先出 priority_queue 最高优先级元素总是第一个出列
【1】密匙一、分而治之/Hash映射 + Hash_map统计 + 堆/快速/归并排序
【eg-1】:把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求;【eg-2】: 300万个查询字符串中统计最热门的10个查询
假设有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去!(300万个字符串假设没有重复,都是最大长度,那么最多占用内存3M*1K/4=0.75G。所以可以将所有字符串都存放在内存中进行处理)在这里, HashTable绝对是我们优先的选择。所以我们放弃分而治之/hash映射的步骤,直接上hash统计,然后排序。So,针对此类典型的TOP K问 题,采取的对策往往是:hashmap + 堆。如下所示:
1.hash_map统计:先对这批海量数据预处理。
具体方法是:维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),
2.堆排序:第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。
即借助堆结构,我们可以在log量级的时间内查找和调整/移动
【2】密匙二、多层划分
【eg-1】:2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,
整数个数为2^32,所以我们可以将这2^32个数划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域;然后不同的区域在利用bitmap就可以直接解决了;也就是说只要有足够的磁盘(不是内存)空间,就可以很方便的解决;
【3】密匙三、Bloom filter/Bitmap
当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检索元素一定不在;如果都是1,则被检索元素很可能在。这就是布隆过滤器的基本思想。
而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
【eg-1】:假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道蜘蛛已经访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,有如下几种方案:
1. 将访问过的URL保存到数据库。2. 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。3. URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。4. Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。
以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。
方法1的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?方法2的缺点:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。
方法3的缺点:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。
方法4的缺点:内存消耗相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将BitSet的长度设置为URL个数的100倍。
实质上上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要100%准确!也就是说少量url实际上没有没网络蜘蛛访问,而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。
方法四的致命缺点是冲突概率高,为了降低冲突的概念,Bloom Filter使用了多个哈希函数,而不是一个。
创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。这样就将字符串str映射到BitSet中的k个二进制位了。
Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
Bit-map:
就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
【4】密匙四、Trie树/数据库/倒排索引
【4-0】树的基础知识补充
动态查找树主要有:二叉查找树(Binary Search Tree),平衡二叉查找树(Balanced Binary Search Tree),
红黑树(Red-Black Tree ),B-tree/B+-tree/ B*-tree (B~Tree)。
前三者是典型的二叉查找树结构,其查找的时间复杂度O(log2N)与树的深度相关,那么降低树的深度自然会提高查找效率。树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下;如何减少树的深度(当然是不能减少查询的数据量)
一个基本的想法就是:采用多叉树结构(由于树节点元素数量是有限的,自然该节点的子树数量也就是有限的)。
【4-0-1】B-Tree是为了磁盘或其它存储设备而设计的一种多叉(相对于二叉,B树每个内结点有多个分支,即多叉)平衡查找树。
与红黑树很相似,但在降低磁盘I/0操作方面要更好一些。许多数据库系统都一般使用B树或者B树的各种变形结构,如下文即将要介绍的B+树,B*树来存储信息。
B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。B树与红黑树又 很相似:
因为与红黑树一样,一棵含n个结点的B树的高度也为O(lgn),但可能比一棵红黑树的高度小许多,所以,B树可以在O(logn)时间内,实现各种如插入(insert),删除(delete)等动态集合操作。
B树是一棵平衡树,它是把一维直线分为若干段线段,当我们查找满足某个要求的点的时候,只要去查找它所属的线段即可。
这种思想其实就是先找一个大的空间,再逐步缩小所要查找的空间,最终在一个自己设定的最小不可分空间内找出满足要求的解。一个典型的B树查找如下:
要查找某一满足条件的点,先去找到满足条件的线段,然后遍历所在线段上的点,即可找到答案。
【4-0-2】R树是B树在高维空间的扩展,是一棵平衡树,R树运用了空间分割的理念,它很好的解决了在高维空间搜索等问题。
用地图的例子来解释,就是所有的数据都是餐厅所对应的地点,先把相邻的餐厅划分到同一块区域,划分好所有餐厅之后,再把邻近的区域划分到更大的区域,划分完毕后再次进行更高层次的划分,直到划分到只剩下两个最大的区域为止。要查找的时候就方便了。
【4-1】Tire树与后缀树
由于基因(或者其他)数据库一般是不变的, 通过预处理来把搜索简化或许是个好主意. 一种预处理的方法是建立一棵Trie.
首先, Trie是一种n叉树, n为字母表大小, 每个节点表示从根节点到此节点所经过的所有字符组成的字符串.
而后缀Trie的 “后缀” 说明这棵Trie包含了所给字段的所有后缀
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
后缀树,就是包含一则字符串所有后缀的压缩Trie;
首先, Trie是一种n叉树, n为字母表大小, 每个节点表示从根节点到此节点所经过的所有字符组成的字符串. 而后缀Trie的 “后缀” 说明这棵Trie包含了所给字段的所有后缀【4-2】再归类总结
涉及到字符串的问题,无外乎这样一些算法和数据结构:自动机,KMP算法,Extend-KMP,后缀树,后缀数组,trie树,trie图等;
最常用和最熟悉的大概是kmp,他们之间的关系如下:
。
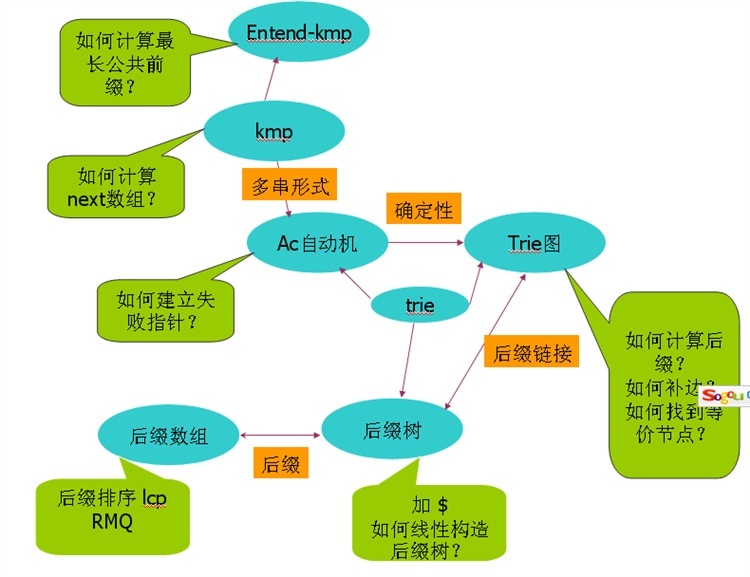
图中可以看到这样一些关系:extend-kmp 是kmp的扩展;ac自动机是kmp的多串形式;它是一个有限自动机;而trie图实际上是一个确定性有限自动机;ac自动机,trie图,后缀树实际上都是一种trie;后缀数组和后缀树都是与字符串的后缀集合有关的数据结构;trie图中的后缀指针和后缀树中的后缀链接这两个概念及其一致;
【4-2-0】KMP算法,Knuth-Morris-Pratt算法【参考这个图文解释】
【问题】有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
【传统BF算法】BF(Brute Force)算法是普通的模式匹配算法
1.
首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.
因为B与A不匹配,搜索词再往后移。
3.
就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.
接着比较字符串和搜索词的下一个字符,还是相同。
5.
直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.
这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.







【改进的KMP算法】
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.
怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了

9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
因为空格与A不匹配,继续后移一位。
12.
逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.
逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。





【4-3】倒排索引【参考这篇博客】
单词-文档矩阵是表达两者之间所具有的一种包含关系的概念模型,
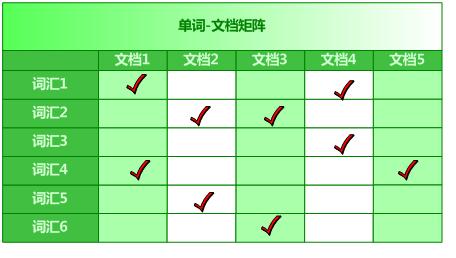
搜索引擎的索引其实就是实现“单词-文档矩阵”的具体数据结构。可以有不同的方式来实现上述概念模型,如“倒排索引”、“签名文件”、“后缀树”等;
但是各项实验数据表明,“倒排索引”是实现单词到文档映射关系的最佳实现方式,
有了这个索引系统,搜索引擎可以很方便地响应用户的查询,
倒排索引基本概念示意图如下:
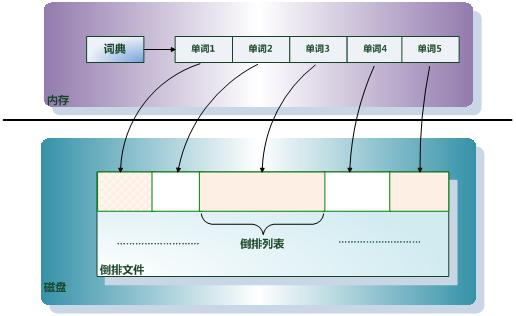
假设文档集合包含五个文档,每个文档内
容如图3-3所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。
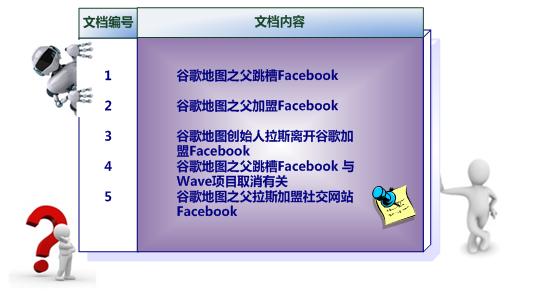
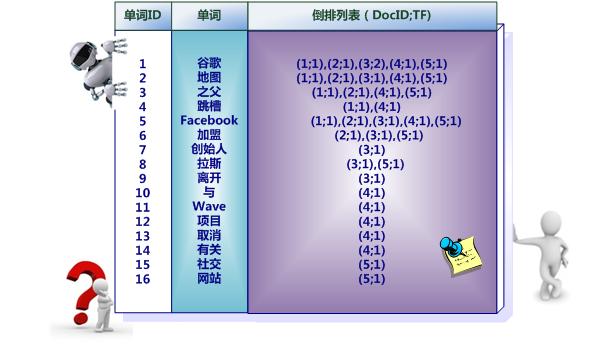
图3-6所示索引系统除了记录文档编号和单词频率信息外,额外记载了两类信息,即每个单词对应的“文档频率信息”(对应图3-6的第三栏)以及在倒排列表中记录单词在某个文档出现的位置信息。
【5】密匙五、外排序
- 按可用内存的大小,把外存上含有n个记录的文件分成若干个长度为L的子文件,把这些子文件依次读入内存,并利用有效的内部排序方法对它们进行排序,再将排序后得到的有序子文件重新写入外存;
- 然后对这些有序子文件逐趟归并,使其逐渐由小到大,直至得到整个有序文件为止。
【6】密匙六、分布式处理之Mapreduce
可以用Spark替代了!















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









