







今年的高考报名人数突破了千万,很多省市的报名人数都有所增加,高考录取的竞争也更加激烈了。当然,每个省市的情况不一样,大家要关注本地的政策。
中国教育网站上有2020年各地高考一分一段表。考生根据成绩对照一分一段表,就可以知道自己在全省的排名,再参照各类学校各批次招生计划数,确定自己该如何填报志愿。
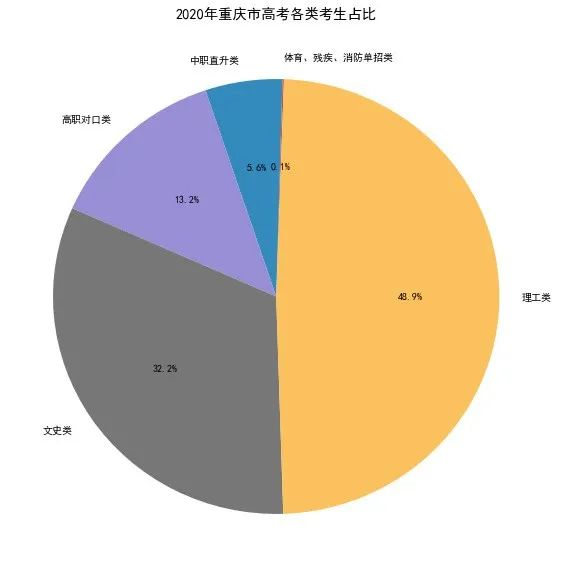
一分一段表大部分都是以图的形式存在,但是也有少数省市的一分一段表数据是表格,可以直接爬取,如重庆,湖南等。我们就直接爬取重庆市的一分一段数据,看看重庆市2020年高考分数和录取情况,赶紧过来看吧。
考生人数
2020年重庆市高考报名 282977 人,比2019年增加 18698 人,增长7.1%。其中,文史类考生 90998 人,理工类考生 138494 人,普通文理类考生共计 22.95 万人,比2019年增加0.5万人;高职对口类考生 3.74 万人,中职直升类考生 1.58 万人,分别比2019年增加 1.1 万人、 0.27 万人;体育单招、残疾单招、消防单招 298 人。
理科分数
重庆市理科最高分是726分,超过700分有54人,超过650分1841人,超过7924人超过600分。重庆理科本科一批分数线为500分,本科二批分数线为411分。
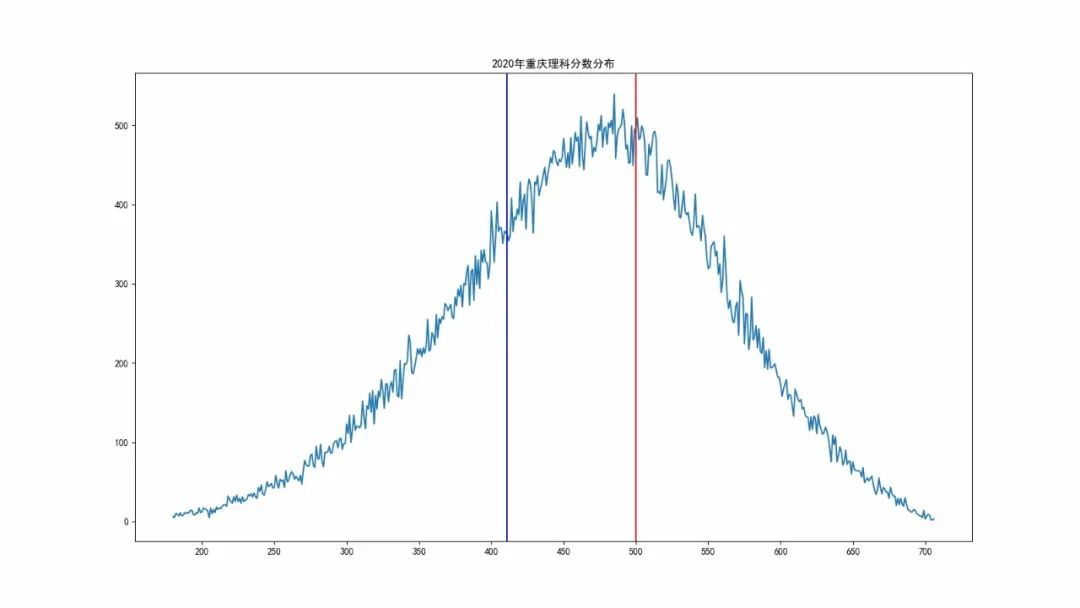
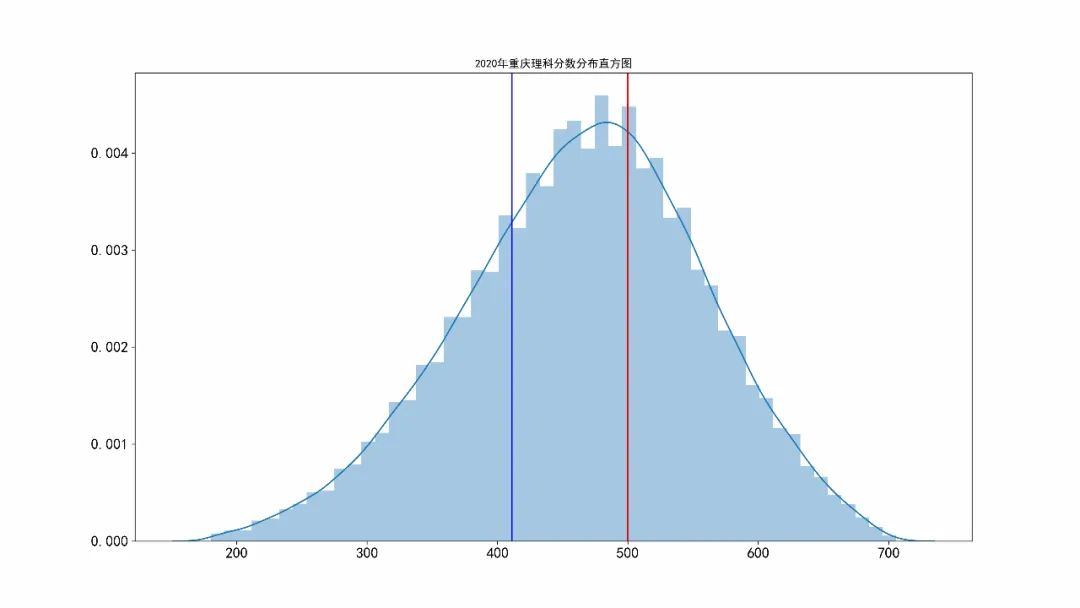
重庆市理科本科一批分数线为500分,本科二批分数线为411分。上图的红色对应本科一批线,蓝色对应本科二批线。有 42071 人超过一本线, 82444 人超过二本线。对应的一本上线率为30.38%,二本上线率为59.53%。理科考生的分数均值为465分,标准差为93分。
文科分数
重庆市文科超过650分101人,超过1835人超过600分。重庆文科本科一批分数线为536分,本科二批分数线为443分。
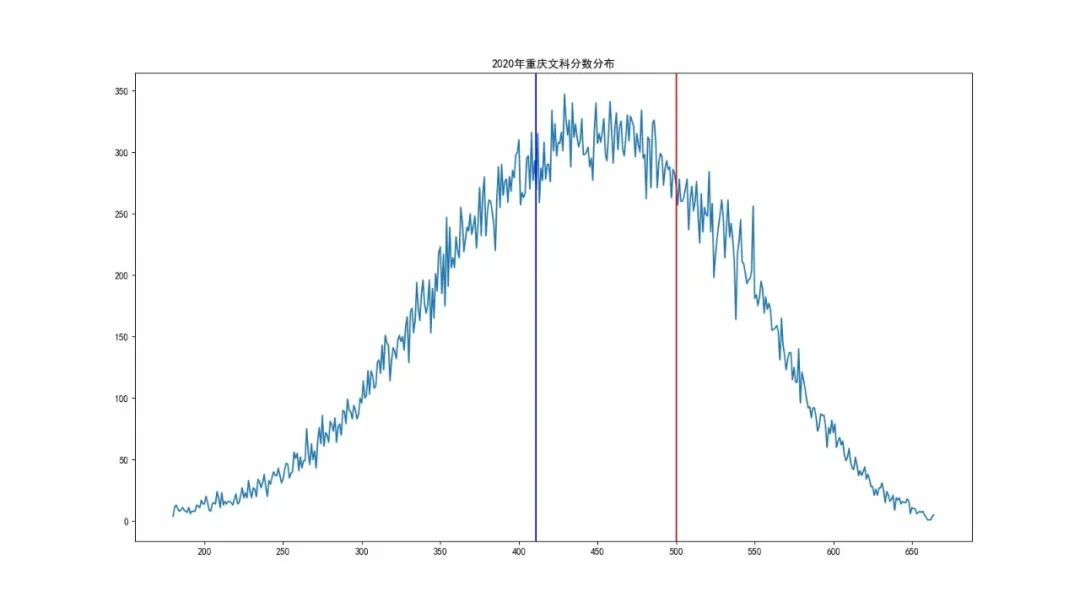
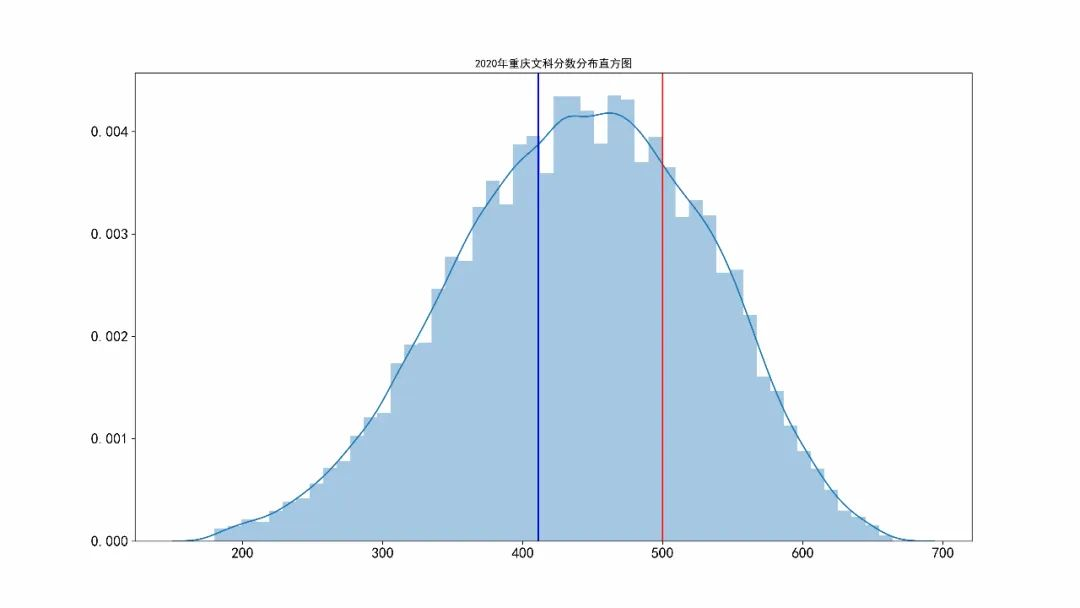
重庆市文科本科一批分数线为536分,本科二批分数线为443分。上图的红色对应本科一批线,蓝色对应本科二批线。有 11117 人超过一本线, 37493人超过二本线。对应的一本上线率为12.22%,二本上线率为41.2%。文科考生的分数均值为440分,标准差为88分。
峰度和偏度(Kurtosis)和 偏度(Skewness)
峰度:峰度(Kurtosis)是描述某变量所有取值分布形态陡缓程度的统计量。
它是和正态分布相比较的。
• Kurtosis=0 与正态分布的陡缓程度相同。
• Kurtosis>0 比正态分布的高峰更加陡峭——尖顶峰
• Kurtosis<0 比正态分布的高峰来得平滑——平顶峰计算公式:β = M_4 /σ^4 偏度:
偏度:偏度(Skewness)是描述某变量取值分布对称性的统计量。
• Skewness=0 分布形态与正态分布偏度相同。
• Skewness>0 正偏差数值较大,为正偏或右偏。长尾巴拖在右边。
• Skewness<0 负偏差数值较大,为负偏或左偏。长尾巴拖在左边。计算公式:S= (X^ - M_0)/δ Skewness 越大,分布形态偏移程度越大。
print('Kurtosis:%.3f'%df_score['score'].kurt())
print('Skewness:%.3f'%df_score['score'].skew())
理科的Kurtosis:-0.233,Skewness:-0.209。文科的Kurtosis:-0.403,Skewness:-0.188。
文理科的峰度和偏度均小于0,比正态分布的高峰来得平滑,长尾巴拖在左边。出现这种偏离,我想到一个原因:复读生。复读生的水平显然和应届的不一样,大量复读生叠加在最后的分布图上,就会导致高峰向右偏。
代码
-
爬虫:https://www.eol.cn/e_html/gk/gkfsd/index.shtml
import requests
import pprint,csv,random,time
import pandas as pd
from bs4 import BeautifulSoup
url='https://gaokao.eol.cn/chong_qing/dongtai/202007/t20200723_1739877.shtml'
headers = {
'Host': 'gaokao.eol.cn',
'Referer': 'https://www.eol.cn/e_html/gk/gkfsd/index.shtml',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
res=requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
items=soup.select('tr')
data=[]
for item in items[3:]:
datum={}
score=item.select("td")[0].text
num=item.select("td")[1].text
total=item.select("td")[2].text
print(score,num,total)
datum["分数段"]=score
datum["人数"]=num
datum["累计人数"]=total
data.append(datum)
df=pd.DataFrame(data)
print(df.head())
df.to_csv('cq_science.csv',index=False


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









