






基于canal的mysql数据同步
一、引言
1、什么是canal?
主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
2、canal工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议。MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ),canal 解析 binary log 对象(原始为 byte 流)。

3、扩展
canal 特别设计了 client-server 模式,交互协议使用 protobuf 3.0 , client 端可采用不同语言实现不同的消费逻辑,如:java,c#,php,Python等。并且canal 作为 MySQL binlog 增量获取和解析工具,可将变更记录投递到 MQ 系统中,比如 Kafka/RocketMQ,可以借助于 MQ 的多语言能力。
二、实现案例
1、开启mysql binlog日志
修改mysql的配置文件my.ini,添加如下配置:
log-bin=mysql-bin
binlog-format=Row
server-id=12333(如果mysql是5.6以上的版本需要)重启Mysql服务。重启后输入一下命名查看是否成功开启:
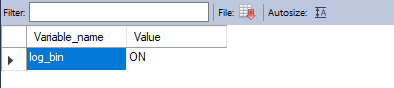
show variables like 'log_bin' ;
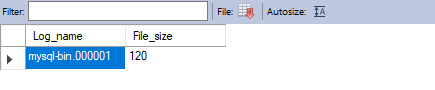
show binary logs;如下显示则表示开启成功
在mysql创建canal用户并赋予replication权限。创建用户赋予权限执行以下语句:
#创建canal用户
create user canal identified by 'canal';
#授权
grant select,replication slave,replication client on*.* to 'canal'@'%';
grant all privileges on *.* TO 'canal'@'%';
flush privileges注:如果授权语句执行报错。需要检查root有没有grant的权限。
2、安装并配置canal-server端
软件下载:https://github.com/alibaba/canal/releases

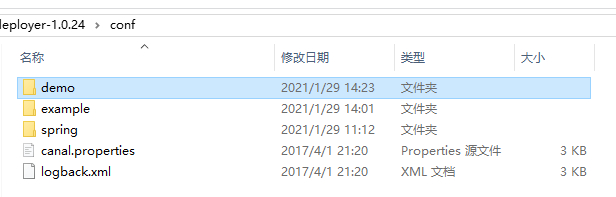
解压下载的压缩包后,可以看到下图的文件夹:

打开conf目录下的canal.properties文件,可以配置端口号、集群(集群依赖zk,需要配置zk地址),如下
#每个canal server实例的唯一标识,暂无实际意义,默认:1
canal.id= 1
#canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行启动服务,默认:无 canal.ip=
#canal server提供socket服务的端口,默认:11111
canal.port= 11111
#canal server链接zookeeper集群的链接信息
canal.zkServers=配置监听数据库的信息:首先将example文件夹 复制一份。比如复制后,名字改为demo。如图
打开demo下的instance.properties文件,如图

# mysql serverId,唯一的
canal.instance.mysql.slaveId = 12345
# 要监听的mysql数据库地址
canal.instance.master.address = 127.0.0.1:3306
# mysql主库链接时起始的binlog文件,默认:无
canal.instance.master.journal.name =
# mysql主库链接时起始的binlog偏移量,默认:无
canal.instance.master.position =
# mysql主库链接时起始的binlog的时间戳,默认:无
canal.instance.master.timestamp =
# 数据库用户名
canal.instance.dbUsername = canal
# 数据库密码
canal.instance.dbPassword = canal
# 数据库名称
canal.instance.defaultDatabaseName = its
# 字符编码
canal.instance.connectionCharset = UTF-8
# 设置需要监听的表,Perl正则表达式.多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\) canal.instance.filter.regex = its\\..*
# 过滤黑名单,同样是正则表达式
canal.instance.filter.black.regex = 注意:1.canal 设置过滤需要改 instance.properties的canal.instance.filter.regex 参数,并且需要注意目录下的mata.dat文件里是否有历史的配置属性。
2.在配置文件里设置,如conf\demo\instance.properties里有2个配置选项canal.instance.filter.regex = ... 这个是白名单,如test..*只监听test数据 库,test.test监控test库里的test表,多个的话用逗号隔开,但是注意这个配置会被客户端的subscribe()方法覆盖,所以如果配置文件里做了配置,客户端最好别配置了,或者只在客户端进行配置过滤也可以。canal.instance.filter.black.regex = 这个是黑名单,排除库表,配置同上,这个配置有效。具体配置示例参照源码目录里filter部 分,canal.instance.defaultDatabaseName = 这个配置项也是无效的,配不配没有关系
启动Canal,在bin目录下的startup.bat 文件,至此服务端的配置已经完成。
3、客户端示例(JAVA语言)
POM中添加依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.0.24</version>
</dependency>JAVA实现代码如下:
public static void main(String args[]) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("10.20.11.121",
11111), "demo", "", "");
int batchSize = 1000;
try {
connector.connect();
connector.subscribe("its\\.cargps");
connector.rollback();
while (true) {
// 获取指定数量的数据
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
printEntry(message.getEntries());
}
// 提交确认
connector.ack(batchId);
//connector.rollback(batchId); // 处理失败, 回滚数据
}
} finally {
connector.disconnect();
}
}
private static void printEntry( List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage = null;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## 解析数据失败:" + entry.toString(),
e);
}
CanalEntry.EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn( List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}1.canal 设置过滤需要改 instance.properties的canal.instance.filter.regex 参数,并且需要注意目录下的mata.dat文件里是否有历史的配置属性。
2.设置了canal.instance.filter.regex,一定不要在客户端调用CanalConnector.subscribe(".\…"),不然等于没设置canal.instance.filter.regex。
3.mysql开始bin-log的时候,如果是5.6以上的Mysql版本,还需要设置server-id。
4.总结:在配置文件里设置,如conf\example\instance.properties里有2个配置选项canal.instance.filter.regex = .\.. 这个是白名单,如test\..*只监听test数据库,test\.test监控test库里的test表,多个的话用逗号隔开,但是注意这个配置会被客户端的subscribe()方法覆盖,所以如果配置文件里做了配置,客户端最好别配置了,或者只在客户端进行配置过滤也可以。canal.instance.filter.black.regex = 这个是黑名单,排除库表,配置同上,这个配置有效。具体配置示例参照源码目录里filter部分,canal.instance.defaultDatabaseName = 这个配置项也是无效的,配不配没有关系















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









