







redis集群模式详解
一,redis集群
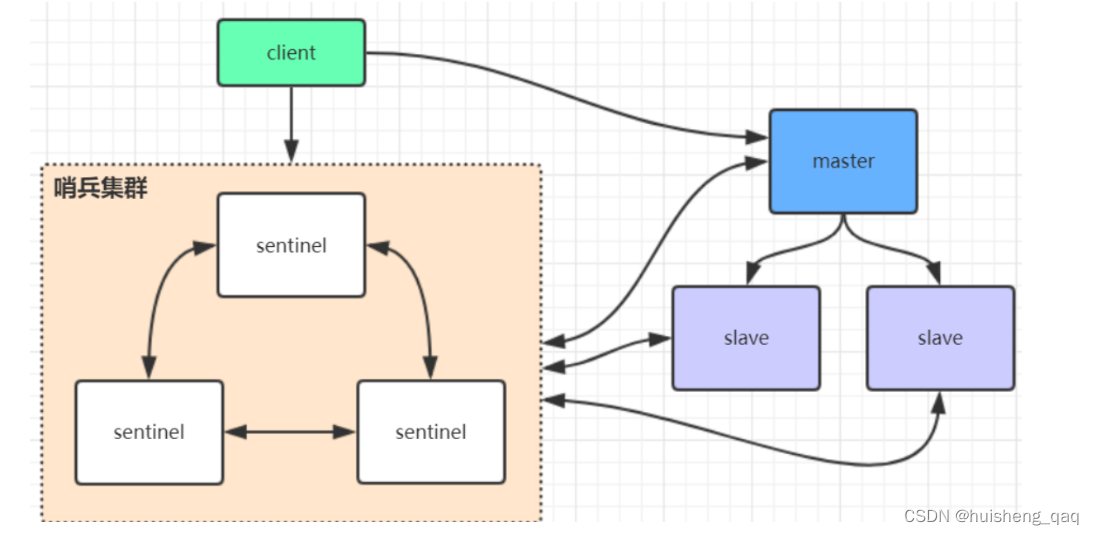
1,哨兵集群
客户端会先去访问这个sentinel的这个哨兵集群,这个哨兵集群会监控所有的redis结点,会将master主结点信息获取,然后告知客户端哪个是主结点,然后客户端再去和这个主结点建立连接,客户端接收到请求之后,和这个客户端建立连接。
但是主从切换的时候存在访问瞬断,就是说不能对外提供服务,并且只有一个主结点对外提供服务,因此没法支持很高的并发。单个主结点内存也不能设置太大,一般都是6个G或者8个G,最好不要超过10个G,否则会影响这个持久化问题,会影响数据的恢复或者主从同步的效率。
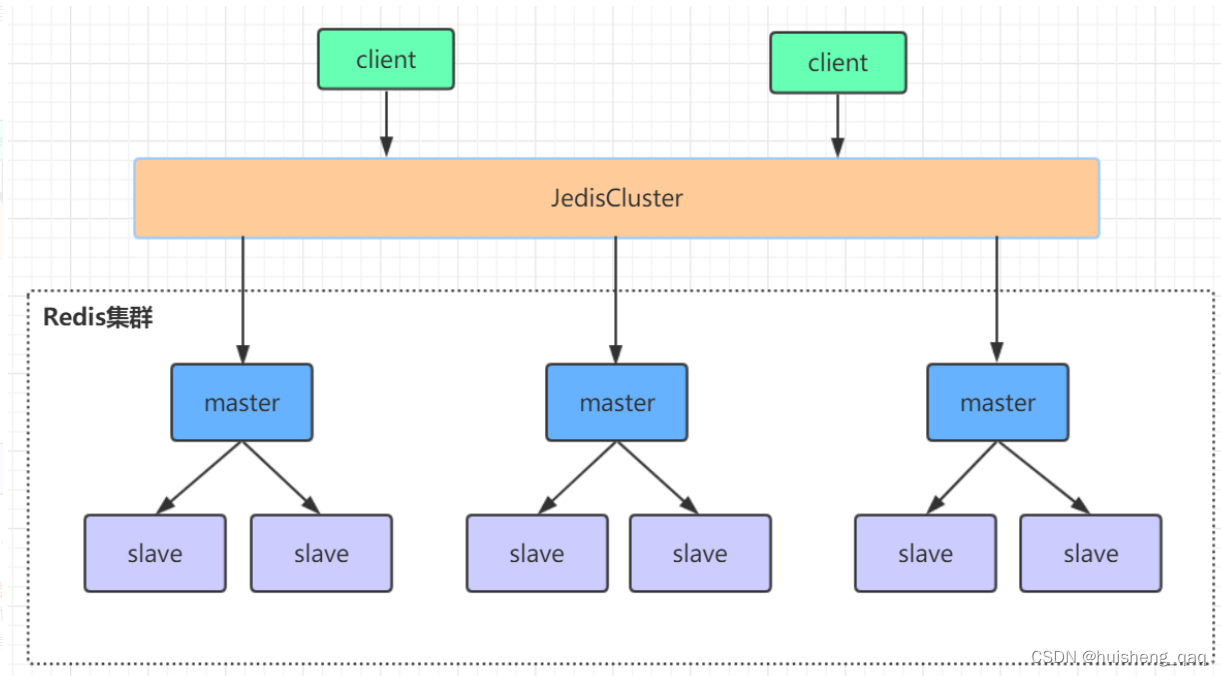
2,redis Cluster
redis的高可用集群如下。就是会有很多小的主从结点的集群,就是相当于将原来的一个大集群进行了一个拆分,拆分成多个小集群。并且小集群里面的数据不会重复,通过hash定位算法找到这个存储的集群的位置。
里面的小集群可以进行一个水平扩容,小集群的个数最好不要超过1000个结点。redis Cluster也支持很高的并发
二,redis Cluster集群的搭建
主要是对里面的redis.conf配置文件进行一个修改,这里的话可以搭建一个伪集群,就是将三个集群放在一个机器里面,和三个集群放三台机器的配置过程一样。
1,配置文件
先创建两个目录
mkdir ‐p /usr/local/redis‐cluster
mkdir 8001 8004
主结点配置信息redis.conf的基本配置信息,端口号为8001
daemonize yes
port 8001(每个机器的端口号进行设置)
pidfile /var/run/redis_8001.pid # 把pid进程号写入pidfile配置的文件,后台会自动创建
dir /usr/local/redis‐cluster/8001/(指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据) cluster‐enabled yes(启动集群模式)
cluster‐config‐file nodes‐8001.conf(集群节点信息文件,这里800x最好和port对应上
cluster‐node‐timeout 10000 13
protected‐mode no (关闭保护模式
appendonly yes
从结点配置信息,端口号为8004
daemonize yes
port 8004(每个机器的端口号进行设置)
pidfile /var/run/redis_8004.pid # 把pid进程号写入pidfile配置的文件,后台会自动创建
dir /usr/local/redis‐cluster/8004/(指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据) cluster‐enabled yes(启动集群模式)
cluster‐config‐file nodes‐8004.conf(集群节点信息文件,这里800x最好和port对应上
cluster‐node‐timeout 10000 13
protected‐mode no (关闭保护模式
appendonly yes
上面就配置好了一个主从,接下来再在这个redis‐cluster目录创建四个目录,主结点分别为8002,8003,从结点为8005,8006。然后按照上面的配置,修改一下端口号即可。
2,redis服务启动
搭建好六个结点之后,可以启动这六个服务
/usr/local/redis‐5.0.3/src/redis‐server /usr/local/redis‐cluster/8001/redis.conf
/usr/local/redis‐5.0.3/src/redis‐server /usr/local/redis‐cluster/8002/redis.conf
/usr/local/redis‐5.0.3/src/redis‐server /usr/local/redis‐cluster/8003/redis.conf
/usr/local/redis‐5.0.3/src/redis‐server /usr/local/redis‐cluster/8004/redis.conf
/usr/local/redis‐5.0.3/src/redis‐server /usr/local/redis‐cluster/8005/redis.conf
/usr/local/redis‐5.0.3/src/redis‐server /usr/local/redis‐cluster/8006/redis.conf
然后可以通过这个命令查看这个redis是否启动成功。
ps ‐ef | grep redis
启动成功之后,就需要给这个节点全部加到一个集群里面。 ‐‐cluster‐replicas 1 这个1表示里面构建一个三主三从的架构。
/usr/local/redis‐5.0.3/src/redis‐cli ‐a zhs ‐‐cluster create ‐‐cluster‐replicas 1 175.178.75.153:8001 175.178.75.153:8002 175.178.75.153:8003 175.178.75.153:8004 175.178.75.153:8005 175.178.75.153:8006
任意连接一个集群
/usr/local/redis‐5.0.3/src/redis‐cli ‐a zhs ‐c ‐h 175.178.75.153 ‐p 8001
进去之后可以查看集群信息
cluster info:查看集群信息
cluster nodes:查看节点列表
三,springboot连接redis集群
1,需要的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
2,yml的配置文件
server:
port: 8080
spring:
redis:
database: 0
timeout: 3000
cluster:
nodes:175.178.75.153:8001 175.178.75.153:8002 175.178.75.153:8003 175.178.75.153:8004 175.178.75.153:8005 175.178.75.153:8006
lettuce:
pool:
max-idle: 50
min-idle: 10
max-active: 100
max-wait: 1000
3,java代码测试
@Autowired
private StringRedisTemplate stringRedisTemplate;
@RequestMapping("/test_cluster")
public void testCluster() throws InterruptedException {
stringRedisTemplate.opsForValue().set("zhenghuisheng", "666");
System.out.println(stringRedisTemplate.opsForValue().get("zhuge"));
}
四,redis集群原理
1,redis分片原理
底层主要是通过一个hash算法实现,会对这个16384进行取模运算。当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这样当客户端要查找某个 key 时,可以直接定位到目标节点
HASH_SLOT = CRC16(key) mod 16384
2,redis集群结点的通信方式
redis采取gossip协议进行通信,主要通信方式有两种,一种是集中式,一种是gossip方式
集中式
就是一个只要有一个结点里面的数据出现变更,那么集群中的其他结点立马可以感知得到,例如可以借助于这个zookeeper的方式实现。
gossip
点对点的方式实现结点与结点之间的通信,更新的请求会陆陆续续,对结点更新会有一定的延时。结点与结点之间会有一些ping,pong的一些通信协议。并且结点通信会有内部的端口,就是在外面通信的端口上面+10000,因此搭建这个集群的时候需要关闭。
3,网络抖动问题
就是说在一段很短的时间内,这个网络不稳定或者说这个出现这个断网的现象,那么可能造成下面的第一个主结点出现这种心跳发送失败的情况,那么其他集群以及第一个集群中的从结点就会认为这个第一个集群的主结点可能挂了,因此第一个集群的从结点就会重新进行一个主结点的选举,在短时间内,这个之前的主结点又恢复了,那么此时会有两个这个主结点。
解决方案:就是可以对这个cluster-node-timeout值进行一个添加,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。并且可以将这个值设置大一点,比如说5s
4,redis集群选举原理
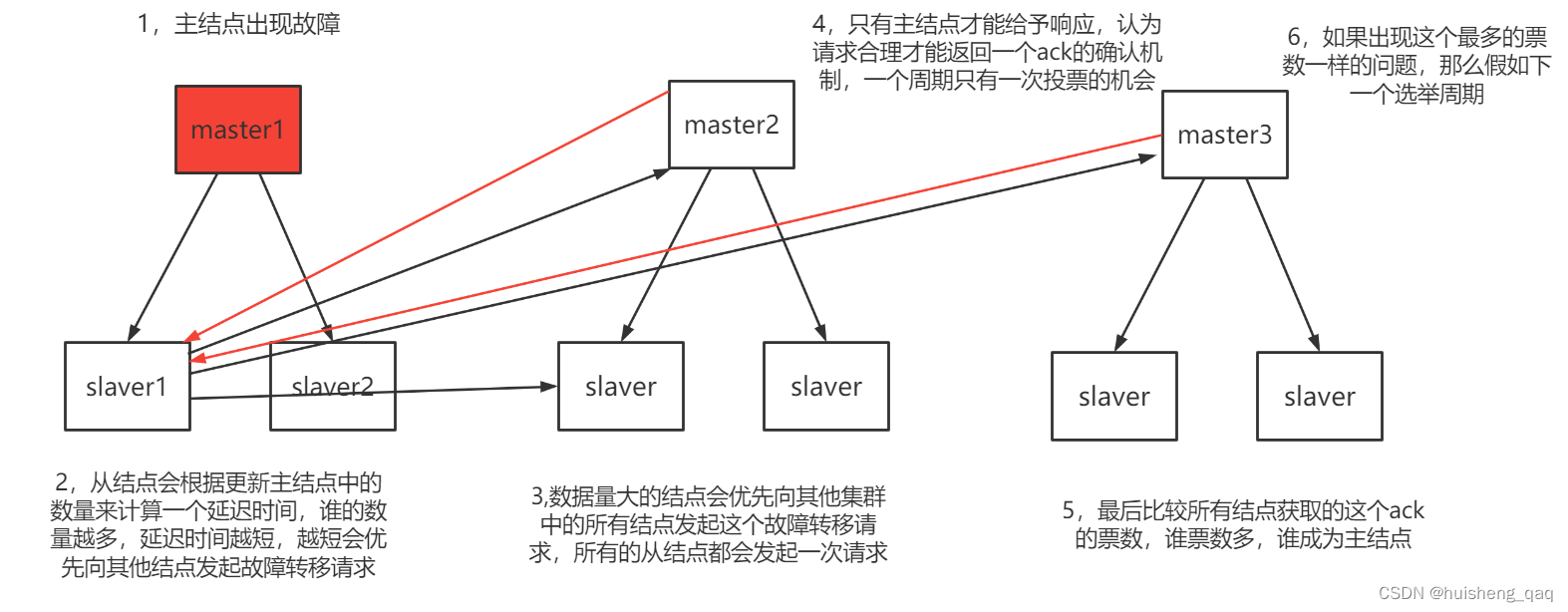
1,当slave从结点发现主结点变为FAIL的时候,从结点便会开始选举一个新的主结点。
2,从结点得知这个主结点挂了,会在一段延迟时间之后,通过广播的形式向其他集群中的所有结点发送信息,就是一个故障转移的请求,信息内容就是想尝试成为新的主结点。并且此时的选举周期会+1。
3,从结点中哪个从结点里面的数据量越多,那么这个从结点的延迟时间就越短,就会优先向其他集群发送成为主结点的请求。
4,其他集群的结点都可以收到这个请求信息,但是只有这个主结点才能响应,如果请求合理就会返回一个ack的确认机制,每个周期只能发送一次ack,就是给这个节点投票了就不能给其他结点进行投票。
5,从结点会收集这个到其他集群主结点返回的这个ack的票数
6,当前集群中的其他从结点到了这个延迟时间,也会做同样的请求操作,然后得到最终的这个ack的票数
7,最后所有的从结点会进行一个票数的比较,超过一半master的ack就可以成为一个新的master。
8,成为新的master之后,会以一个广播pong消息来通知其他的集群的结点。
9,如果出现很极端的情况,就是存在票数一样的情况,那么就会加入下一轮的这个选举周期。
延迟时间的计算公式如下,这个SLAVE_RANK便是的就是表时这个从结点向主结点中获取数据的更新度,如果获取的数据越多,那么这个更新度rank就会越小,那么这个延长时间就会越小。
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
5,集群脑裂数据丢失问题
和网络抖动一样,就是说在一段很短的时间内,这个网络不稳定或者说这个出现这个断网的现象,那么可能造成下面的第一个主结点出现这种心跳发送失败的情况,那么其他集群以及第一个集群中的从结点就会认为这个集群的主结点可能挂了,因此集群的从结点就会重新进行一个主结点的选举,在短时间内,这个之前的主结点又恢复了,那么此时会有两个这个主结点,就是造成了这个脑裂问题,这样就会有大量的数据丢失。
解决方案如下,但是也会影响一定的可用性
min-replicas-to-write 1
6,集群要三个master节点原因,并且推荐为奇数
新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。而奇数的master节点更多的是 从节省机器资源角度出发















 5606
5606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











