







目录
一 增
相比于C语言,c++的添加元素机制好处在哪:
插入对应的字符,字符串或者string对象以及基于这些功能的string的函数实现,比如+=,append,push_back,insert以及一些对应的扩容机制
相比于C语言的增加机制,由于是malloc出来的一块空间,因此需要手动地进行扩容,并且扩容的时候还有很多需要注意的地方比如差错处理等,需要对这块空间进行管理。
并且追加对应的字符使用的函数strcat,追加的时候需要去找尾巴,效率低下。
c++的话增加对应的字符串等底层自己就实现了扩容,并且不再需要自己手动地去管理了。就比较省心。
由此,STL的string类也有自己增加元素的函数。
①+=
运算符重载。相比于+,+=直接返回的是引用,但是+返回的是string对象,所以+=要比+更加的高效
+=操作的对象可以是字符,字符串,字符串对象
string s1 = "hello ";
string s2 = "world";
string s3(s2);
s1 += s2;
s1 += s3;
s1 += 'c';她的底层其实是封装了append和push_back的,(string不提供头插,因为头插的效率很低下,插入之后需要将后续的所有位置都进行移动。但是可以用其他的方法实现头插,之后讲解)
②append
都是在末尾添加
它既可以追加一个字符串,并且对于被添加的字符串来说可以在特定的位置追加特定的长度的字符串 比如第24行的意思就是hello第三个位置开始添加3个大小的字符串,如果长度太大,默认添加到结尾结束 第28行的意思是添加hello从头开始两个位置大小的字符串
也可以实现追加特定个数的字符
也可以追加一个string对象
也可以用迭代器区间来追加。这个迭代器区间应该是要左闭右开的
string s1 = "hello";
string s2 = "world";
s1.append("hello");
cout << s1 << endl;
cout << endl;
s1.append("hello", 3, 3);
cout << s1 << endl;
cout << endl;
s1.append("hello", 2);
cout << s1 << endl;
cout << endl;
s1.append(s2);
cout << s1 << endl;
cout << endl;
s1.append(5, 'a');
cout << s1 << endl;
cout << endl;
s1.append(s2.begin() + 3, s2.end());
cout << s1 << endl;
cout << endl;③push_back
在末尾增加一个字符,同时长度size+1
string s1 = "hello ";
s1.push_back('a');
cout << s1 << endl;
cout << endl; 其实上述的push_back和append的功能都可以由+=运算符重载来实现的
④insert
可以实现在特定的位置添加对应的数据,添加数据的方法和append类似,只不过多了一个指定对应位置的参数
由增加引起的扩容机制
由于string是一个定长的数组,长度不够会进行扩容。但是在不同的平台下有不同的扩容机制,并且不同的编译器她的扩容机制也是不一样的
在了解扩容机制之前我们先了解下与此相关的概念,capacity容量大小,计算的是能够存储有效字符的空间,不算\0
size计算的是对应string的长度,不算\0
length和size一样,只不过string刚开始被设计出来是length,后来为了和其他的容器同一,有了size
max_size没啥太大的意义,是一个定长的数字
1 在vscode下,一般起点会比较大,刚开始扩容2倍,之后是1.5倍进行扩容
2 在linux的平台下,一般都是两倍两倍的扩容
由此我们可以看出,我们不能依赖SLT的底层实现,因为在不同平台不同编译器甚至同一个编译器不同版本都不相同
扩容带来的问题:
如果我们一开始开的空间太小 ,那么我们放不下对应的数组,之后增加数据要进行频繁的扩容,如果我们开的空间太大了,又会造成空间的浪费,因此如果我们提前知道需要开辟多大的空间,可以提前先开辟好,避免频繁地扩容
由此引申出的一个函数——reserve和resize
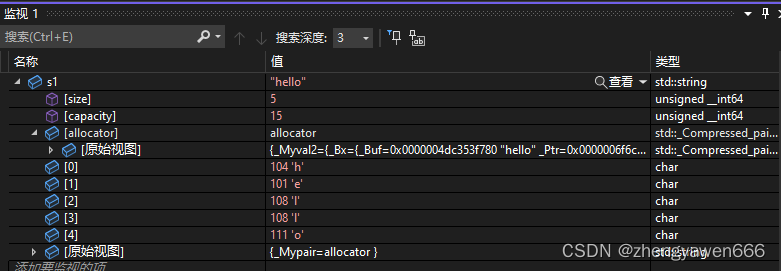
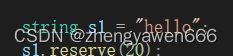
①reserve
直接影响capacity,并且需要遵循上述对应的扩容机制,比如你reserve20个空间大小,很可能capacity不是20
![]()
比如刚开始的时候,开了15个大小的capacity
扩容之后:

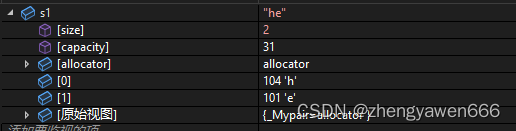
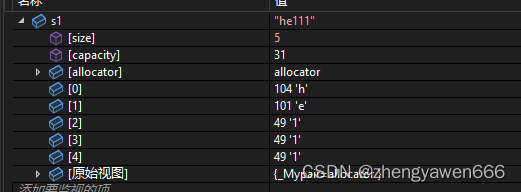
②resize
影响有效字符,比如resize之后的长度比一开始的长度要小,那么就会截掉多余的字符
如果resize之后的长度比之前的要大,我们就可以进行填充,针对于刚开始没有存储数据的string来说,就相当于开了空间还可以初始化
![]()
![]()
例题:
将一个字符串中的‘ ’处插入20%
string s1 = "we are happy";
for (int i = 0; i < s1.size(); i++)
{
if (s1[i] == ' ')
{
s1.insert(i,"20%");
}
}如果单纯这么写的话,那么会陷入死循环。因为i的变化没有插入的变化快,当你插入三个字符20%的时候,i只增加1,那么就会在当前位置向后查找,又找到之前的‘ ’,进行插入,如此无休无止。
解决方法:
①对i单独控制
string s1 = "we are happy";
for (int i = 0; i < s1.size(); i++)
{
if (s1[i] == ' ')
{
s1.insert(i,"20%");
i += 3;
}
}
cout << s1 << endl;② erase释放对应位置的元素再插入
但是头插和在特定位置删除效率会很低下,可以思考其他的方法
其他的方法1
先提前用reserve开辟好对应的空间,之后从后往前进行遍历,如果遇到了空格,
其他的方法2
以空间换时间。再创建一个string类型的对象,对之前的数组从头开始遍历,如果遇到了‘ ’,那么就在对应的新的string的该位置插入20%。
string s1 = "We are happy!";
string s2;
for (int i = 0; i < s1.size(); i++)
{
if (s1[i] == ' ')
{
s2 += "20%";
}
s2 += s1[i];
}
cout << s2;
}也可以用replace
二 删除
erase
啥都不指定就全部删光了
可以删除特定位置的一个字符
也可以删除一段区间的数据
string s1 = "hello";
s1.erase(s1.begin() + 1);
s1.erase(s1.begin() + 1, s1.end() - 1);
s1.erase();如果想实现替换(删除对应的数据并且添加新的数据),可以用replace
三 查找
find
从头开始查找对应的字符或者字符串的位置,如果找到就返回对应的下标,如果找不到就返回npos
tring s1 = "hello";
size_t i= s1.find('e');
if (i != string::npos)
{
cout << i;
}
size_t i2 = s1.find("llo");
if (i2 != string::npos)
{
cout << i2;
}由find衍生出的其他查找函数
rfind:查找子字符串或字符最后一次出现的位置(倒着找)
find_first_of:字符串中查找参数中任何一个字符首次出现的位置。
find_last_of:字符串中查找参数中任何一个字符最后一次出现的位置。
find_first_not_of:在字符串中查找第一个不包含在参数中的字符
find_last_not_of:查找最后一个不包含在参数中的字符。
例题:取后缀
如果一个文件名字是test.cpp如何取出对应的后缀呢?
1 find函数找到对应的.的位置
2 substr取子串,取出对应的子串 需要给出对应的位置和取出的大小,如果没有给大小,那么默认从pos位置开始全部取出
string filename = "test.cpp";
size_t pos = filename.find('.');
if (pos != string::npos)
{
cout << filename.substr( pos, filename.size() - pos);
}拓展1:如果有多个.如何取出真后缀呢?从后往前取出
用rfind
string filename = "test.cpp.zip";
size_t pos = filename.rfind('.');
if (pos != string::npos)
{
cout << filename.substr( pos, filename.size() - pos);
}拓展2 网络解析
网址一般由三个部分构成:①协议名http,之后会带上://进行与域名分割②域名,带上/与之后的动作进行分割
string url = "https://ilive.lenovo.com.cn/?f=stee";
size_t pos1 = url.find(':');
string protocol = url.substr(0, pos1);
cout << protocol << endl;
size_t pos2 = url.find('/', pos1 + 3);
if (pos2 == string::npos)
{
cout << "非法URL" << endl;
return -1;
}
string domain = url.substr(pos1+3,pos2-1-(pos1+3));
cout << domain << endl;
string uri = url.substr(pos2+1);
cout << uri << endl;
return 0;
}四 类型转换操作
string可以向其他的类型进行转换 ,其他的类型也可以转换成string。浮点数进行转换的时候,有时候后会有精度的损失

五 一些其他的接口
getline
cin和scanf多个值输入,值和值之间以空格或者换行间隔,多个字符串之间以空格或者换行间隔。
如果输入的一行中本身就带着空格,那么单独一次的cin就不能接收了,因为cin碰到空格就结束了,空格之后在输入的缓冲区中存着,只cin一次是拿不到对应的以空格隔开的所有的字符串的。这时候就可以用用getline:
getline(cin,str)实现
c_str
C语言中也有读取字符串的需求,但是此时不能传入string,就可以调用c_str
但是C语言标准的c_str和c++中的string是有区别的
c++中的string可以包含\0,他的终止以size为准。但是C语言中\0标识着字符串的结束,如果有\0,就会停止输入,也就是说正常的字符串中不能够包含\0,否则就会出现问题
也就是说,在c++中,\0不一定是结束的标识符
string s1 = "test.cpp ";
string s2 = "test.h";
s1 += '\0';
s1 += s2;
cout << s1 << endl;//test.cpp test.h
cout << s1.c_str() << endl;//test.cpp














 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









