







以下为本人学习中的个人理解,辅以笔记,如有错误,请以正确知识为准。
1.慢查询优化思路
(1)优化更需要优化的SQL
情况1:每小时10000次查询,每次20个IO 优化后,最后只要18个IO,每小时节约20000次IO;
情况2:每小时10次查询,每次20000个IO 优化后,最后只要2000个IO 2000*10=20000次IO。
情况1更值得优化。
(2)定位优化对象的性能瓶颈
IO?CPU?网络带宽?
(3)明确的优化目标
优化到什么程度取决于数据库情况,业务情况,一般用户体验改善就达到目的了
(4)先要在自己的头脑中明确,自己的SQL想要达到的执行计划效果(索引等等)
(5)永远用小结果集驱动大结果集
(6)尽可能在索引中完成排序
- order by 字句中的字段加索引(扫描索引即可,内存中完成,逻辑io);
- 若不加索引的话会可能会启用一个临时文件辅助排序(落盘,物理io)。
(7)只取出自己需要的列,不要用select *
* - 不仅影响着字段的解析,还会影响索引的选择以及SQL的过滤性能,甚至网络带宽
(8)仅使用最有效的过滤条件
1)Where字句中条件越多越好吗?达到效果一样,选择一个索引
2)若在多种条件下都使用了索引,那如何选择?
3)最终选择方案:key_len的长度决定使用哪个条件
(9)尽量避免复杂的join和子查询
(10)小心使用groupby、orderby、distinct语句
(11)合理设计并利用索引
2.永远用小结果集驱动大的结果集(join操作表小于百万级别)
(1)驱动表的定义:
1)指定了联接条件时,满足查询条件的记录行数少的表为[驱动表]
2)未指定联接条件时,行数少的表为[驱动表]
(2)MySQL关联查询的概念
MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,最后合并结果。
(3)leftjoin、right join、inner join的区别
left join:
select * from t2 left join t3 on t2.id =t3.id and t3.id in(1,2,3) order by t2.id desc;

大白话:left join - 左连接表作为驱动表
right join
select * from t2 right join t3 on t2.id =t3.id and t3.id in(1,2,3);

大白话:right join - 右连接表作为驱动表
inner join
select * from t2 inner join t3 on t2.id =t3.id and t3.id in(1,2,3);

解释:
inner join: 驱动表由MySQL决定,但是会受到索引的影响,MySQL会选择没有索引的表作为驱动表。
在没索引的情况下,mysql会通过使用Using join buffer(hash join)来,优化查询,减少循环次数,原来可能循环1000次,优化后可能减少到10次,这个取决于mysql的join_buffer_size大小的设置,默认256kb。
(4)数据量小于百万怎么处理?
永远用小结果集驱动大的结果集
(5)数据量大于百万怎么处理?
1)方法1:单表查询,程序处理
2)方法2:将数据同步至Redis处理
3.join的实现原理
(1)mysql只支持一种join算法
Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种:
Simple Nested-Loop Join(简单嵌套循环)
Index Nested-Loop Join(索引嵌套循环)
Block Nested-Loop Join(块嵌套循环)
(2)Simple Nested-Loop Join(简单嵌套循环)
 现在,这种基本不使用了,建议在被驱动表建立索引,减少开销。
现在,这种基本不使用了,建议在被驱动表建立索引,减少开销。
(3)Index Nested-Loop Join(索引嵌套循环)
 在第一种上进行了优化驱动表会先在关键字所在索引,当查找后索引后,再回表查找。
在第一种上进行了优化驱动表会先在关键字所在索引,当查找后索引后,再回表查找。
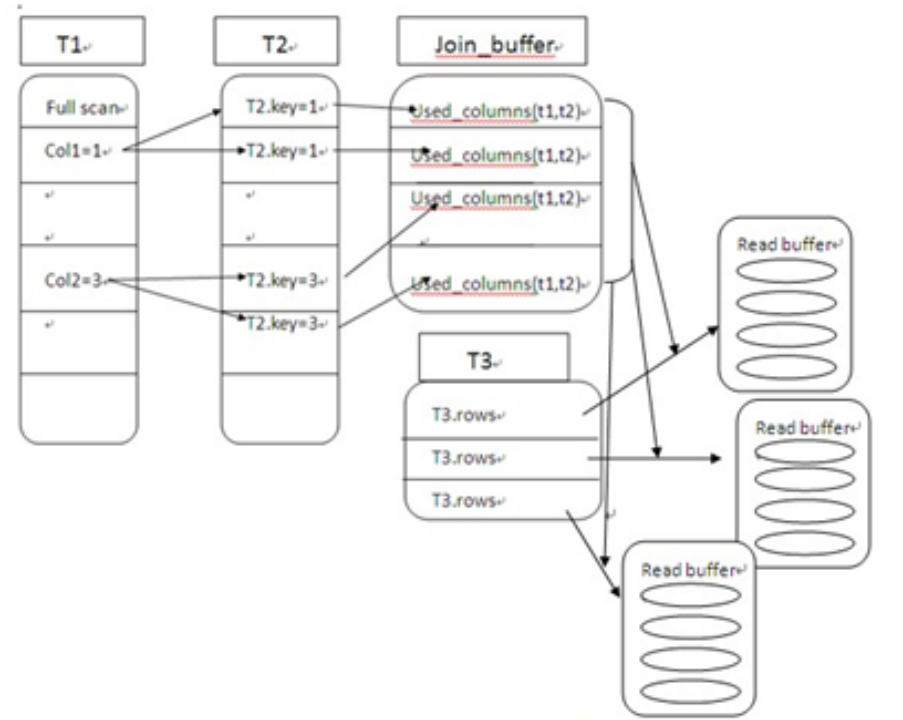
(4)Block Nested-Loop Join(块嵌套循环)

(5)Block Nested-Loop Join(3表)
4.join的优化思路
(1)尽可能减少join语句中的Nested Loop的循环总次数
最有效的办法,驱动表尽可能的小
(2)优化Nested Loop的内层循环
(3)保证join语句中被驱动表join条件字段已经被索引(2的一种优化方式)
(4)在无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜join buffer的设置
5.join的优化思路总结
(1)并发量太高的时候,系统整体性能肯能会急剧下降
(2)复杂的join语句,所需要锁定的资源也就越多,所阻塞的其他线程也就越多
(3)复杂的Query语句拆分成多个较为简单的Query语句分布执行
6.mysql其他几种优化注意点
(1)只取出需要的列,不要用select *
1)如果取出的列过多,则传输给客户端的数据量必然很大,增加数据响应时间,且浪费带宽
2)若在排序的时候输出过多的列(超出索引列以外的列,没法在索引完成排序),则会浪费内存(Using filesort)
3)若在排序时, 输出过多的列(超出索引列以外的列,导致无法使用索引),还可能改变执行计划
(2)仅使用最有效的过滤条件
1)Where字句中条件越多越好吗?达到效果一样,选择一个索引
2)若在多种条件下都使用了索引,那如何选择?
3)最终选择方案:key_len的长度决定使用哪个条件
大白话:key_len: 索引的字节长度,比如nickname为varchar(25),则key_len的字节长度为25*4+3=103,25*4(一个字符四个字节) + varchar可变字符额外加3个字节 = 103。
(3)尽可能在索引中完成排序
1)order by字段中的字段加索引(扫描索引即可,内存中完成,逻辑IO)
2)若不加索引的话,可能会启用一个临时文件辅助排序(落盘,物理IO)
7.order by子句优化详解
(1)order by排序原理及优化思路
1)ordey by排序可利用索引进行优化,order by子句中只要是索引的前导列都可以使索引生效,可以直接在索引中排序,不需要在额外的内容或文件中排序;
重点理解:orderby(where也符合)使用复合索引的条件,查询条件必须包含前导列(最左匹配原则),且必须按索引字段查询一个或多个索引字段,举例:idx_index(id,name,status),如果通过id/id、name/id、name、status都可以利用复合索引(走索引),但id,status/name/status/id、status这样都是无法利用复合索引的(不走索引);
查询字段(在复合索引情况下idx(id,name,status)只要是索引中的字段就行(与是否为前导列无关),即select status from t3,都是可以走索引的。
额外解释一种情况SQL:


where条件idc变成范围后,

其实很好理解,将idc=3改为>2后,idc变成了范围,这是idc=3和idc=4的数据柔在一起了,不能保证name还是有序的,所以需要额外的重新排序。

2)不能利用索引避免额外排序的情况,例如:排序字段中有多个索引,排序顺序和索引键顺序不一致(非前导)
(2)order by排序算法
1)MySQL对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求,此时SQL的执行计划中会出现’Using fileSort’,这里需要注意的是filesort并不意味着文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size(一般未优化情况下,都是256kb,即262144字节)参数与结果集大小确定。MySQL内部实现排序主要由3种方式,常规排序、优化排序和优先队列排序,主要涉及3中排序算法:快速排序、归并排序和堆排序。
2)order by常规排序算法
【1】步骤
a.从表t1中获取满足WHERE条件的记录;
b.对于每条记录,将记录的主键和排序键(id,col2)取出放入sort_buffer;
如果sort_buffer可以存放所有满足条件的(id,col2)对(注意:这里是根据排序字段col2进行排序的,意味着id是乱序的,后面排好序后,id是可能乱序的,可以优化将id排好序,id排序的内存大小受”read_rnd_buffer_size”,默认大小也为256kb),则进行排序;否则sort_buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法);
c.若排序中产生临时文件,需要利用归并排序算法,保证临时文件中记录是有序的;
d.循环执行上述过程,直到所有满足条件的记录全部参与排序;
e.扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3);
f.将获取的结果集返回给用户。
3)order by优化排序算法
常规排序方式除了排序本身,还需要额外两次IO。
优化的排序方式相对于常规排序,减少了第二次IO。
主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。
什么时候采用优化排序算法呢?(id,col2)元组(order by关键字后要排序的列)大小小于”max_length_for_sort_data”的大小,默认是4kb,低于4kb,MySQL就采用优化排序算法排序,否则采用常规排序算法。
4)order by优先队列排序算法
5.6及之后的版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。
对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
(3)order by排序不一致问题
1)MySQL5.6发现分页出现了重复值

MySQL5.6,id=3的数据没了,id=4的数据出现了2次。
MySQL8是正常的。
2)原因分析及解决方案
针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,比如上述的例子order by idc limit 0,3 需要采用大小为3的大顶堆;limit 3,3需要采用大小为6的大顶堆。由于idc为3的记录有3条,而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。为了避免这个问题,我们可以在排序中加上唯一值,比如主键id,这样由于id是唯一的,确保参与排序的key值不相同。

4)order by排序索引
重点:一般情况下,一个SQL语句只能用一个索引,如果where占用了索引,那么order by将无索引可以使用,所以要格外注意查询字段,where条件,分组字段的索引生效 使用情况。

上图因为用了主键的索引PRIMARY,导致idx_idc_name_id没有被使用。
去掉where条件

发现没有争抢索引,从而使order by用上了idx_idc_name_id索引。
那么必须有where条件怎么办?
权衡下是where条件花费时间长还是orderby排序时间长,决定索引用在哪里
不抢占索引,where条件看能否换成不走索引的。

继续,把order by的前导列干掉
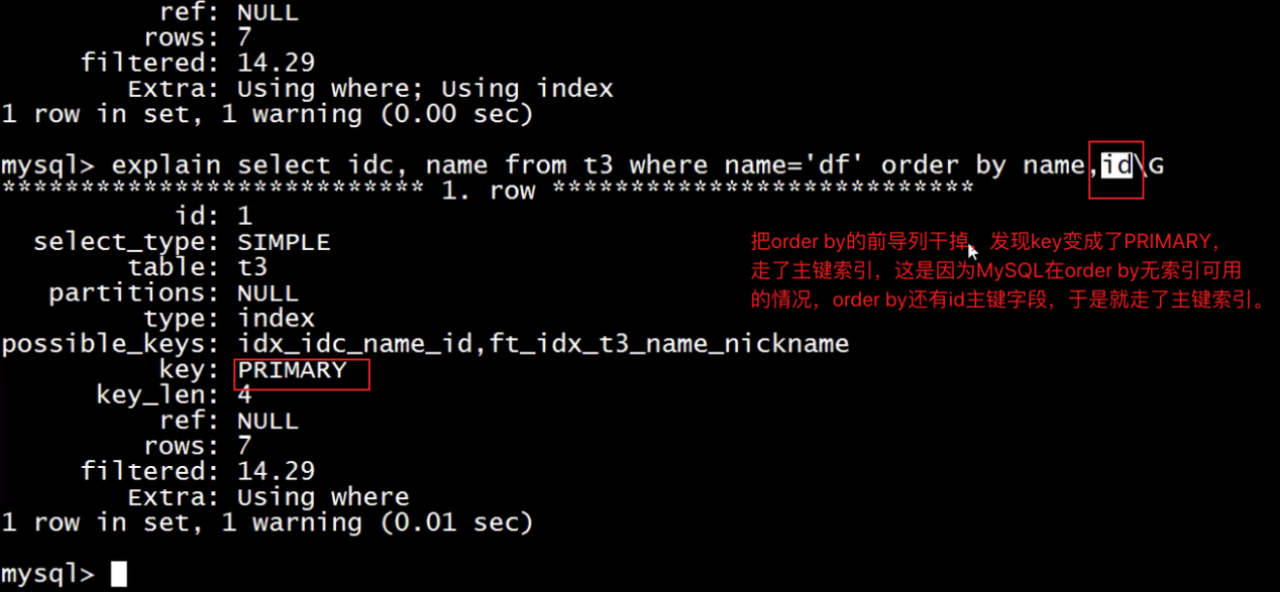
继续将order by的id干掉

这里排序name沾了idc字段的光。
继续,给查询列增加一个nickname字段,这时,nickname即不是order by字段,也不存在索引

变成了全表扫描,无索引可走。
总结:要想让SQL走索引,一定要综合考虑查询字段、where条件、orderby排序字段这三个点。














 64
64











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









