







摘要
由于在像联邦学习这样的协作学习环境中存在多个参与方,好奇的参与方可能是诚实的,但会试图通过推理攻击来推断其他参与方的私有数据,而恶意的参与方可能会通过后门攻击来操纵学习过程以达到自己的目的。然而,大多数现有的工作只考虑了数据按样本划分(HFL)的联邦学习场景。特征分区联邦学习(VFL)可能是许多实际应用程序中的另一个重要场景。当攻击者和防御者无法访问其他参与者的特征或模型参数时,这种场景中的攻击和防御尤其具有挑战性。以前的工作只表明私有标签可以从每个样本梯度的通信中重建。在本文中,我们首先证明了即使只显示批平均梯度而不显示样本水平梯度,也可以重建私有标签。通常认为批平均信息共享是安全的,因此批标签推理攻击对VFL是一个严峻的挑战。
对抗的目标
在我们的设置中,攻击者的目标是训练一个在原始任务和攻击任务上都达到高性能的模型。
标签推理攻击。标签推断任务的目的是推断被动方(在VFL设置中没有获得标签信息的一方)的标签信息。
后门攻击。与拜占庭式攻击不同(Mu ~ noz- gonzalez, Co, and Lupu 2019),在我们的设置下,防止收敛不是攻击者的目标。后门任务是为具有特定模式(即触发器)的输入数据分配攻击者选择的标签,如图2所示。我们将在以下部分详细讨论这两种攻击以及这些攻击如何相互关联。
Label Inference Attack
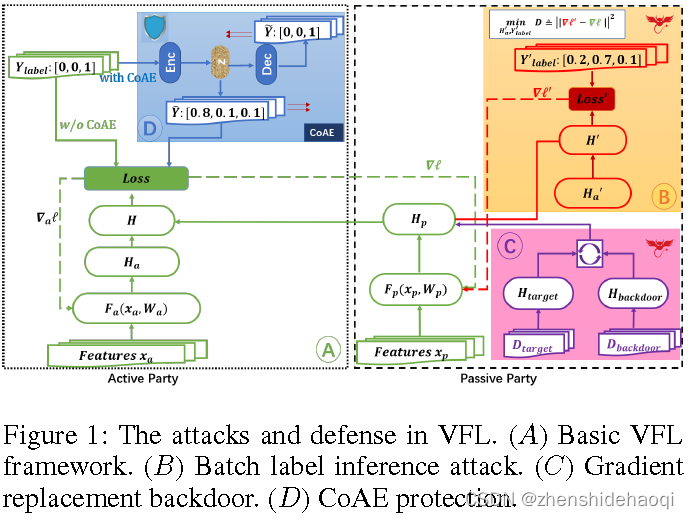
具体来说,被动性的一方(攻击者)p建立了一个内部模型,试图猜测标签,并传达中间结果Ha,使模拟的局部梯度与观察到的梯度相匹配。

我们的实验表明,这种重建可以非常强大,达到90%以上的标签重建率。因此,我们得出结论,批量平均不足以保护VFL设置中的标签信息。在下一节中,我们提出了一种新的保护标签的防御技术。
防御
在前面的章节中,我们已经表明标签泄漏和后门攻击都是VFL的挑战问题。在本节中,我们将讨论可能的保护途径。特别是主动方需要建立更强有力的防御机制。以前采用的常见防御机制包括差分隐私和梯度稀疏。然而,这些技术通常会遭受精度损失,这在某些情况下可能是不可接受的。另一项工作是利用每样本梯度值的分布差异(Li et al. 2021),但它们并不总是可用的。在这里,我们提出了一种简单而有效的标签伪装技术,即主动方学习将原始标签转换为一组“软假标签”,以便1)这些软假标签与原始标签形成对比,即转换后的假标签和原始标签可能不一样;2)原始标签几乎可以无损地重建;3)假冒标签应尽可能引入混淆,防止被动方推断出真实标签。例如,一个简单的映射函数(例如,一个函数将标签“狗”分配给“猫”,将标签“猫”分配给“狗”)将满足前两个条件,但不满足最后一个条件,因为如果一方知道一个样本的真实标签,它将知道属于同一类的所有样本的真实标签。为了增加混淆,我们建议学习一个混淆自编码器(CoAE)来建立一个映射,这样一个标签将以更高的概率为每个替代类转换为软标签。例如,将一只狗分别映射为狗和猫的[0.5,0.5]概率。尽管自动编码器在隐藏真实标签方面简单有效,但混淆在改变类的概率分布方面很重要,这使得后门攻击更难成功。














 1554
1554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









