






云原生大数据组件研究(Hive+Hadoop)
前言
网上的找的文档大多残缺不靠谱,所以我整理了一份安装最新版本的hive4..0.0+hadoop3.3.4的学习环境,可以提供大家安装一个完整的hive+hadoop的环境供学习。
由于在公司担任大数据的培训工作后续还会更新一些基础的文章,希望能帮助到大家。
一、安装Hadoop3.3.4
前置:集群规划
| 机器信息 | Hostname | k8s-master | k8s-node1 | k8s-node2 |
| 外网IP | ||||
| 内网IP | ||||
| NameNode | Y | N | N | |
| SecondaryNameNode | N | Y | N | |
| HDFS | DataNode | Y | Y | Y |
| YARN | ResourceManager | Y | N | N |
| NodeManager | Y | Y | Y |
PS:部署前请修改好格机器的hostname 并配置好/etc/hosts文件。
step1 安装前准备
- 确保 Selinux是禁用状态
#查看是否是禁用状态 若不是则通过 vi 命令进行修改
cat /etc/selinux/config
|
|

- 设置各台机器的免密登录
2.1 切换到k8s-master机器上操作
#进入秘钥存放目录(后续操作一路回车)
ssh-keygen -t rsa
#进入秘钥目录
#rm -rf .ssh
cd ~/.ssh
#将秘钥导入
cat id_rsa.pub >>authorized_keys
#分发秘钥 格式【ssh-copy-id 主机名】
#分发到node1(后续操作需要输入 node2密1)
ssh-copy-id k8s-node1
#分发到node2(后续操作需要输入 node2密码)
ssh-copy-id k8s-node2
#验证node1的免密登录
ssh k8s-node1
exit
#验证node2的免密登录
ssh k8s-node2
exit
- 安装JDK1.8 并配置环境变量(各台机器都需要执行)
#查看jdk安装支持包
yum -y list java*
#安装jdk1.8
yum install java-1.8.0-openjdk.x86_64
#查看jdk版本
java -version
#查看jdk目录
ls /usr/lib/jvm/
#向 /etc/profile 文件追加如下内容
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre" >> /etc/profile
echo "export CLASS_PATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar:\$JAVA_HOME/lib" >> /etc/profile
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile
#修改配置文件
#cat /etc/profile
#使得配置文件生效
source /etc/profile
#查看变量名是否正常生效
echo $JAVA_HOME
echo $CLASS_PATH
echo $PATH
#安装openjdk-devel包 否则无法使用jps
yum install java-1.8.0-openjdk-devel.x86_64
- 安装hadoop
下载 hadoop-3.3.4.tar.gz 编译好的版本
链接: 百度网盘 请输入提取码 提取码: i4a8
#新建用于存放安装包的目录
mkdir -p /home/install/hadoop/
#新建用于存放压缩后组件的目录
mkdir -p /home/module/hadoop/
#进入安装包目录 上传 hadoop-3.3.4.tar.gz
cd /home/install/hadoop/
#解包目录
tar -zxvf /home/install/hadoop/hadoop-3.3.4.tar.gz -C /home/module/hadoop/
#已经解压到 /home/module/hadoop/hadoop-3.3.4
#赋予目录全执行权限
chmod 777 -R /home/module/hadoop
#向 /etc/profile 文件追加如下内容
echo "export HADOOP_HOME=/home/module/hadoop/hadoop-3.3.4" >> /etc/profile
echo "export PATH=:\$PATH:\${HADOOP_HOME}/bin:\${HADOOP_HOME}/sbin" >> /etc/profile
#使得配置文件生效
source /etc/profile
#查看安装是否生效
hadoop version
step2 集群部署
PS:特别注意之后 如果配置发生变更需要将变更的配置文件,还是要分发到各台机器!
修改配置文件
#进入hadoop中的配置文件目录 (注意所需修改的所有配置文件都在 解压后 /etc/hadoop 目录下 )
cd /home/module/hadoop/hadoop-3.3.4/etc/hadoop
#显示当前目录位置
pwd
|
|

该目录下有我们所需修改文件 core-site.xml 、hdfs-site.xml 、mapred-site.xml、yarn-site.xml 。
修改配置文件
- hadoop-env.sh
该文件是hadoop环境变量读取文件,我们执行下面的内内容将配置追加到文件末尾
#进入hadoop中的配置文件目录 (注意所需修改的所有配置文件都在 解压后 /etc/hadoop 目录下 )
cd /home/module/hadoop/hadoop-3.3.4/etc/hadoop
#执行命令 追加到 hadoop-env.sh
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre" >> hadoop-env.sh
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> hadoop-env.sh
echo "export HDFS_NAMENODE_USER=root" >> hadoop-env.sh
echo "export HDFS_DATANODE_USER=root" >> hadoop-env.sh
echo "export HDFS_SECONDARYNAMENODE_USER=root" >> hadoop-env.sh
echo "export YARN_RESOURCEMANAGER_USER=root" >> hadoop-env.sh
echo "export YARN_NODEMANAGER_USER=root" >> hadoop-env.sh
#查看追加结果
cat hadoop-env.sh
!无需执行!(也可以使用vi来添加下面内容)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre
export PATH=$PATH:$JAVA_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
- core-site.xml
#编辑文件 修改<configuration></configuration>中的内容
vi core-site.xml
<configuration>
<!--1.指定Hadoop的文件系统的 NameNode URI -->
<property>
<name>fs.defaultFS</name>
<!--格式<value>hdfs://主机名:8020 </value>-->
<value>hdfs://k8s-master:8020</value>
</property>
<!--2.指定hadoop 数据的存储目录默认为/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoopDatas/tempDatas</value>
</property>
<!--hive.hosts 允许 root 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--hive.groups 允许 Hive 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--配置缓存区的大小,实际可根据服务器的性能动态做调整-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--开启hdfs垃圾回收机制,可以将删除数据从其中回收,单位为分钟-->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
| PS:hadoop.proxyuser.root.groups hadoop.proxyuser.root.groups 必须设置不然 hiveServer2启动会失败。 |
| 报错如下: java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://k8s-master:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous |
- hdfs-site.xml
#编辑文件 修改<configuration></configuration>中的内容
vi hdfs-site.xml
<configuration>
<!-- 配置 hdfs 文件切片的副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置HDFS文件权限-->
<property>
<name>dfs.permission</name>
<value>false</value>
</property>
<!--设置一个文件切片的大小:128M-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- NameNode web 端访问地址(主机名:端口号) -->
<property>
<name>dfs.namenode.http-address</name>
<value>k8s-master:9870</value>
</property>
<!-- 指定SecondaryNameNode web 端访问地址(主机名:端口号) -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>k8s-node1:9868</value>
</property>
<!--指定namenode元数据的存放位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/server/hadoopDatas/namenodeDatas</value>
</property>
<!--指定datanode数据存储节点位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/server/hadoopDatas/datanodeDatas</value>
</property>
<!--指定namenode的edit文件存放位置-->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/server/hadoopDatas/nn/edits</value>
</property>
<!--指定检查点目录-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/server/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/server/hadoopDatas/dfs/snn/edits</value>
</property>
</configuration>
- mapred-site.xml
是MapReduce的核心配置文件
#编辑文件 修改<configuration></configuration>中的内容
vi mapred-site.xml
<configuration>
<!--指定mapreduce运行的框架yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--开启mapreduce最小任务模式-->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 配置 mapreduce 的历史记录 组件的内部通信地址即 RPC 地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<!--格式<value>主机名:端口</value>-->
<value>k8s-master:10020</value>
</property>
<!-- 配置 mapreduce 历史记录服务的 web 管理地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>k8s-master:19888</value>
</property>
<!-- 配置 mapreduce 已 完成的 job 记录在 HDFS 上的存放地址 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<!-- 配置 mapreduce 正在执行的 job 记录在 HDFS 上的存放地址 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property> <!-- 为 MR 程序主进程添加环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/module/hadoop/hadoop-3.3.4</value>
</property>
<!-- 为 Map 添加环境变量 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/module/hadoop/hadoop-3.3.4</value>
</property>
<!-- 为 Reduce 添加环境变量 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/module/hadoop/hadoop-3.3.4</value>
</property>
</configuration>
- yarn-site.xml
#编辑文件 修改<configuration></configuration>中的内容
vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!--指 定 resourcemanager 所启动服务的主机名 |IP(yarn主节点位置)-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>k8s-master</value>
</property>
<!--指 定 mapreduce的shuffle 处理数据方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置 resourcemanager 内部通讯地址 -->
<property>
<name>yarn.resourcemanager.address</name>
<value>k8s-master:8032</value>
</property>
<!-- 配置 resourcemanager 的 scheduler 组件的内部通信地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>k8s-master:8030</value>
</property>
<!-- 配置 resource-tracker 组件的内部通信地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>k8s-master:8031</value> </property>
<!-- 配置 resourcemanager 的 admin 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>k8s-master:8033</value>
</property>
<!-- 配置 yarn 的 web 管理地址 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>k8s-master:8088</value>
</property>
<!--yarn 的日志聚合是否开启 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 聚合日志在 hdfs 的存储路径 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<!-- 聚合日志在 hdfs的 保存时长,单位 S ,默认 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 聚合日志的检查时间段 -->
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>3600</value>
</property>
<!-- 设 置日志聚合服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://k8s-master:19888/jobhistory/logs</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
- workers
重新配置workers
cat > workers << EOF
k8s-master
k8s-node1
k8s-node2
EOF
创建配置文件中涉及的数据目录
#创建hadoop.tmp.dir对应目录
mkdir -p /export/server/hadoopDatas/tempDatas
#创建dfs.namenode.name.dir对应目录
mkdir -p /export/server/hadoopDatas/namenodeDatas
#创建dfs.datanode.data.dir对应目录
mkdir -p /export/server/hadoopDatas/datanodeDatas
#创建dfs.namenode.edits.dir对应目录
mkdir -p /export/server/hadoopDatas/nn/edits
#创建dfs.namenode.checkpoint.dir对应目录
mkdir -p /export/server/hadoopDatas/snn/name
#创建dfs.namenode.checkpoint.edits.dir对应目录
mkdir -p /export/server/hadoopDatas/dfs/snn/edits
chmod 777 -R /export/server/hadoopDatas
step4 分发节点
1.切换到k8s-node1和k8s-node2 分别执行
1.1 追加环境变量(各台机器均需要执行)
#向 /etc/profile 文件追加如下内容
echo "export HADOOP_HOME=/home/module/hadoop/hadoop-3.3.4" >> /etc/profile
echo "export PATH=:\$PATH:\${HADOOP_HOME}/bin:\${HADOOP_HOME}/sbin" >> /etc/profile
#使得配置文件生效
source /etc/profile
1.2 创建目录(各台机器均需要执行)
mkdir -p /home/module/hadoop/
chmod 777 -R /home/module/hadoop/
2.切换到k8s-master执行
2.1 copy配置好的hadoop
#复制到k8s-node1
scp -r /home/module/hadoop/hadoop-3.3.4 root@k8s-node1:/home/module/hadoop/
#复制到k8s-node2
scp -r /home/module/hadoop/hadoop-3.3.4 root@k8s-node2:/home/module/hadoop/
2.2 格式化Namenode(仅能格式化一次)
首次启动HDFS需要对其进行格式化操作,做清理和准备
hadoop namenode -format
|
|
|
|
|
|



2.3 启动 hadoop服务
cd /home/module/hadoop/hadoop-3.3.4/sbin
start-all.sh
#关闭命令(无需执行)
#stop-all.sh
|
|

附录:分阶段一键启动命令(无需执行)
#一键启动HDFS
#start-dfs.hs
#一键启动Yarn
#start-yarn.sh
#启动历史服务进程(这必须单独启动)
#mr-jobhistory-daemon.sh start historyserver
2.4. 检查进程运行情况
jps
|
|

step5 通过web端查看 hdfs集群情况
HDFS查看地址:http://[你机器机器ip]:9870/
|
|

yarn查看地址:http://[你机器机器ip]:8088/
|
|

HDFS:公网IP:9870
yarn:公网IP:8088
错误解决集合
1. no YARN_RESOURCEMANAGER_USER defined.
|
|

解决方法:该文件是hadoop环境变量读取文件,我们执行下面的内内容将配置追加到文件末尾
即可解决该问题
#进入hadoop中的配置文件目录 (注意所需修改的所有配置文件都在 解压后 /etc/hadoop 目录下 )
cd /home/module/hadoop/hadoop-3.3.4/etc/hadoop
#执行命令 追加到 hadoop-env.sh
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64/jre" >> hadoop-env.sh
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> hadoop-env.sh
echo "export HDFS_NAMENODE_USER=root" >> hadoop-env.sh
echo "export HDFS_DATANODE_USER=root" >> hadoop-env.sh
echo "export HDFS_SECONDARYNAMENODE_USER=root" >> hadoop-env.sh
echo "export YARN_RESOURCEMANAGER_USER=root" >> hadoop-env.sh
echo "export YARN_NODEMANAGER_USER=root" >> hadoop-env.sh
#查看追加结果
cat hadoop-env.sh
2
#如果找不到 chattr 命令需要重装下
yum remove e2fsprogs
yum install e2fsprogs
cd ~/.ssh
lsattr authorized_keys
#显示
#-----a-------e-- authorized_keys
lsattr authorized_keys2
#显示
#-----a-------e-- authorized_keys2
chattr -a -e authorized_keys
chattr -a -e authorized_keys2
rm -rf authorized_keys
rm -rf authorized_keys2
2.【漏洞】 Hadoop Yarn RPC未授权访问漏洞
| 参考文献 | |
Hadoop Yarn RPC未授权访问漏洞存在于Hadoop Yarn中负责资源管理和任务调度的ResourceManager,成因是该组件为用户提供的RPC服务默认情况下无需认证即可访问,因此把RPC服务暴露在公网上是非常危险的。
RPC服务利用这一问题会影响到部分有安全意识的用户。一部分用户基于过去几年中基于多种利用Hadoop的历史蠕虫已经意识到RESTful API的风险,通过配置开启了基于HTTP的认证,或通过防火墙/安全组封禁了RESTful API对应的8088端口,但由于他们没有意识到Hadoop同时提供RPC服务,并且访问控制机制开启方式跟REST API不一样,导致用户Hadoop集群中RPC服务所在的8032端口仍然可以未授权访问。
经测试可知,对于8032暴露在互联网且未开启kerberos的Hadoop Yarn ResourceManager,编写应用程序调用yarnClient.getApplications()即可查看所有应用信息
解决方案
1、Apache Hadoop 官方建议用户开启 Kerberos 认证
2、设置 Hadoop RPC 服务所在端口仅对可信地址开放
或者只在【内网】开放8032端口,注意由于这个漏洞不能对外开放8032!
- 容器方式安装mysql8.0-作为元数据库
这个是作为hive的元数据库的,如果自己有mysql可以跳过这个步骤
前置:数据规划
| 用户名 | 密码 |
| root | 【你自己的密码】 |
| chenjia | 【你自己的密码】 |
1创建目录
若之前用本文档安装轻用这个命令清理 #rm -rf /home/mysql
cd /home
mkdir mysql
mkdir -p /home/mysql/conf
mkdir -p /home/mysql/data
mkdir -p /home/mysql/logs
chmod -R 777 /home/mysql
2创建一个临时的mysql镜像复制其配置文件
| docker run -d -p 3306:3306 --privileged=true --restart=always \ -e MYSQL_ROOT_PASSWORD=123456 \ --name mysql01 mysql \ --lower-case-table-names=1 |
#复制配置文件 挂载出去方便以后修改
docker cp -a mysql01:/etc/mysql/my.cnf /home/mysql/conf/my.cnf
#删除临时镜像
docker rm -f mysql01
3修改/home/mysql/conf/my.cnf 配置文件
vim /home/mysql/conf/my.cnf
在最后一行增加最大连接数设置
max_connections=2000
:wq 保存
4正式启动mysql环境
注意:需要使用大小写不敏感配置 (--lower-case-table-names=1 )
如果之前安装过请先执行此命令删除 #docker rm -f mysql01
| mysql8.0 安装命令 | docker run -d -p 3306:3306 --privileged=true --restart=always \ -v /home/mysql/conf/my.cnf:/etc/mysql/my.cnf \ -v /home/mysql/data:/var/lib/mysql \ -v /home/mysql/logs:/logs -e MYSQL_ROOT_PASSWORD=123456 \ --name mysql01 mysql \ --lower-case-table-names=1 |
5为mysql创建一个可以远程访问的用户
以下是创建一个用户名为 chenjia 密码为 【你自己的密码】 的管理员账号
docker exec -it mysql01 /bin/bash
mysql -u root -p
create user chenjia@'%' identified by '【你自己的密码】';
grant all privileges on *.* to chenjia@'%' with grant option;
flush privileges;
alter user 'chenjia'@'%' identified with mysql_native_password by '【你自己的密码】';
#将简单密码改成复杂的【你自己的密码】 以免收到攻击
alter user 'root'@'%' identified with mysql_native_password by '【你自己的密码】';
#alter user 'root'@'%' identified with mysql_native_password by '【你自己的密码】';
6查看与临时修改mysql最大连接数
docker exec -it mysql01 /bin/bash
mysql -u root -p
show variables like 'max_connections';
set global max_connections=1000;
exit
技巧:Docker镜像中安装vim命令的方法
docker exec -it mysql01 /bin/bash
apt-get update
apt-get install vim
三、安装hive4.0.0
版本选用
对于 Hadoop 3.3.4,建议使用与之兼容的最新版本的 Hive,即 Hive 4.0.0。这是因为 Hive 4.0.0 是与 Hadoop 3.3.x 兼容的最新版本,可以充分利用 Hadoop 3.3.4 中的新特性和改进。
Hive 3.1.3。 Hive 3.1.3 也与 Hadoop 3.3.x 兼容,并且是 Hive 3.x 系列中的最新版本,它在功能和性能方面与 Hive 4.0.0 相当接近。
前置已经安装项目:
Hadoop3.3.4
MySql8.0
安装Hive
1.下载安装包
下载 apache-hive-4.0.0-alpha-2-bin.tar.gz
下载方式1:官方网站
下载方式2: https://pan.baidu.com/s/1hPas2f3PU81SXdtvB4_zbQ?pwd=81lv 提取码: 81lv
2.设置安装目录和环境变量
#建立目录
mkdir -p /home/install/hive
#上传apache-hive-4.0.0-alpha-2-bin.tar.gz
#创建hive安装目录
mkdir -p /home/module/hive
chmod 777 /home/module/hive
#解压hive到 安装目录
tar -zxvf /home/install/hive/apache-hive-4.0.0-alpha-2-bin.tar.gz -C /home/module/hive
#进入hive安装目录
cd /home/module/hive/
#修改名称为 hive-4.0.0
mv apache-hive-4.0.0-alpha-2-bin hive-4.0.0
#进入hive的安装目录
cd /home/module/hive/hive-4.0.0
#向 /etc/profile 文件追加如下内容
echo "export HIVE_HOME=/home/module/hive/hive-4.0.0" >> /etc/profile
echo "export PATH=\$PATH:\$HIVE_HOME/bin" >> /etc/profile
#查看配置是否被写到最后
cat /etc/profile
#使得配置文件生效
source /etc/profile
#验证环境变量
echo $HIVE_HOME
echo $PATH
解决日志jar包冲突
#在系统重查找所有的 SLF4J 绑定的 JAR 文件
find / -name "*slf4j*.jar"
| [root@k8s-master lib]# find / -name "*slf4j*.jar" find: ‘/proc/13287’: 没有那个文件或目录 find: ‘/proc/13288’: 没有那个文件或目录 find: ‘/proc/13289’: 没有那个文件或目录 find: ‘/proc/13291’: 没有那个文件或目录 find: ‘/proc/13292’: 没有那个文件或目录 /home/module/hadoop/hadoop-3.3.4/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar /home/module/hadoop/hadoop-3.3.4/share/hadoop/common/lib/slf4j-api-1.7.36.jar /home/module/hadoop/hadoop-3.3.4/share/hadoop/common/lib/jul-to-slf4j-1.7.36.jar /home/module/hive/hive-4.0.0/lib/log4j-slf4j-impl-2.18.0.jar /home/module/hive/hive-4.0.0/hcatalog/share/webhcat/svr/lib/jul-to-slf4j-1.7.30.jar |
#删除
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.18.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.18.0.bak
#恢复 方法
#mv $HIVE_HOME/lib/log4j-slf4j-impl-2.18.0.bak $HIVE_HOME/lib/log4j-slf4j-impl-2.18.0.jar
3.上载mysql连接驱动
链接: https://pan.baidu.com/s/1dvCqt77D1wOKbtBUrAILkA?pwd=7kni 提取码: 7kni
#mysql8.0 的最新驱动到lib目录
cd /home/module/hive/hive-4.0.0/lib
4.在mysql中创建metastore数据库
#进入容器内容
docker exec -it mysql01 /bin/bash
#登录
mysql -u root -p
#输入密码 123456 (本地可用)
#创建 metastore 数据库:
CREATE DATABASE metastore;
#创建hiveruser 为其设置密码
CREATE USER 'hiveuser'@'%' IDENTIFIED BY '【你自己的密码】';
#授予metastore数库的所有访问权限
GRANT ALL PRIVILEGES ON metastore.* TO 'hiveuser'@'%';
#退出mysql终端
exit
#退出docker环境
exit
5.修改配置文件
1.hive-site.xml
#进入配置文件夹
cd /home/module/hive/hive-4.0.0/conf
#rm -rf hive-site.xml
#创建配置文件
vi hive-site.xml
复制下面内容到文件中用wq保存
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://k8s-master:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hiveuser</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>【你自己的数据库密码】</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://k8s-master:9083</value>
<description>URI for client to connect to metastore server</description>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>k8s-master</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hiveserver2的高可用参数,如果不开会导致了开启tez session导致hiveserver2无法启动 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<!--解决Error initializing notification event poll问题-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
配置文件解释:
| <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://<hostname>:<port>/<database>?useSSL=false&allowPublicKeyRetrieval=true</value> </property> |
| 参数说明: jdbc:mysql://<hostname>:<port>/<database>?useSSL=false&allowPublicKeyRetrieval=true 应该设置为实际使用的数库连接字符串 |
| <property> <name>javax.jdo.option.ConnectionUserName</name> <value><username></value> </property> |
| 参数说明: <username>参数应改为实际上的数据库的用户 |
| <property> <name>javax.jdo.option.ConnectionPassword</name> <value><password></value> </property> |
| 参数说明: <password> 参数应改为实际上的数据库的密码。 |
| <property> <name>hive.metastore.uris</name> <value>thrift://<hostname>:9083</value> <description>URI for client to connect to metastore server</description> </property> |
| 参数说明: <hive.metastore.uris> 参数是连接到 Hive 元数据存储服务的必要参数。如果没有正确配置该参数,当您尝试连接到 Hive 时,会遇到类似于 "No current connection" 的错误消息。,<hostname> 应该被替换为运行 Hive Metastore Server 的主机名或 IP 地址。如果 Hive Metastore Server 运行在非默认端口上,那么您需要相应地更改端口号。 |
6.初始化 元数据 数据库命令
#执行初始化元数据
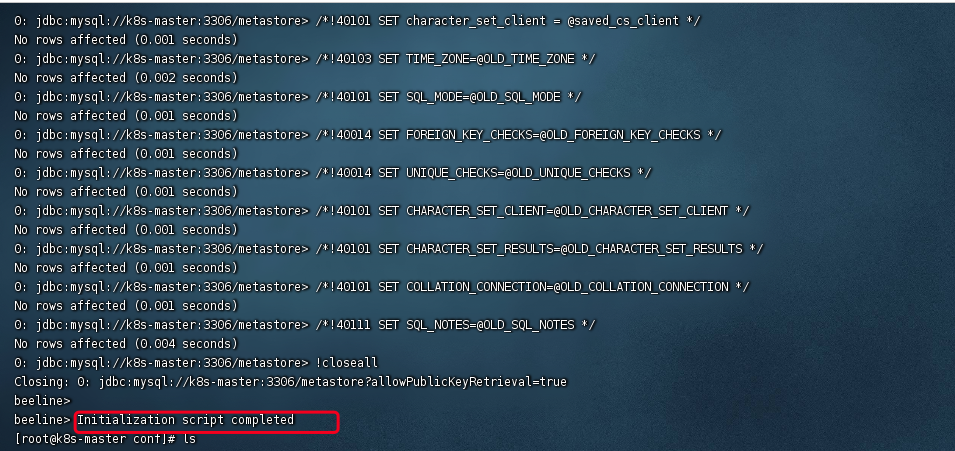
schematool -dbType mysql -initSchema -verbose
#查看日志
cat /tmp/root/hive.log
PS:元数据库初始化日志的目录路径取决于我们配置的 Hive 元数据库日志目录位置。默认情况下,Hive 元数据库日志存储在 ${java.io.tmpdir}/${user.name}/hive.log 中,其中 ${java.io.tmpdir} 是 Java 系统属性中的临时目录路径,${user.name} 是当前用户的名称。如果您使用的是默认值,则可以在 /tmp/your-username/ 目录下找到日志文件
|
|
7. 配置hive启动所需服务
在Hive 4.0.0中,Hive CLI已经被弃用,取而代之的是Beeline。所以,当你启动Hive 4.0.0时,你会默认进入Beeline命令行界面,而不是Hive CLI。如果你想使用Hive CLI,你可以考虑降低Hive的版本,或者在Hive 4.0.0中使用Beeline命令行。
使用Beeline命令行连接Hive服务之前,需要确保以下服务已经启动和配置:
| 服务 | 说明 | 执行命令 |
| Hadoop | Hive需要依赖Hadoop服务来运行,因此需要确保Hadoop服务已经启动,并且配置文件中的相关参数正确。 | start-all.sh |
| Hive Metastore | Hive Metastore是Hive的元数据存储服务,需要确保Metastore服务已经启动,并且在Beeline的配置文件中正确配置了Metastore的地址。 | hive --service metastore |
| HiveServer2 | HiveServer2是Hive的查询服务,需要确保HiveServer2服务已经启动,并且在Beeline的配置文件中正确配置了HiveServer2的地址。 | hive --service hiveserver2 |
查看日志文件位置(可用于后续排除错误)
#在 Hive 的 conf/ 目录下 有一个hive-log4j2.properties 指定了日志的位置
#默认是记录在 hive.log中的 可以找下这个文件的位置
find / -name "*hive*.*log*"
#找到日志后可以使用下面的方法查看日志 排除错误
#持续查看日志
tail -f /tmp/root/hive.log
#查看100行
tail -n 100 /tmp/root/hive.log
按顺序启动各基础服务
# 为演示效果 打开一个新的shell窗口 启动后窗口不再操作
start-all.sh
# 为演示效果 打开一个新的shell窗口 启动后窗口不再操作
hive --service metastore -n hive -p hivis250ha
netstat -anp | grep 9083
# 为演示效果 打开一个新的shell窗口 启动后窗口不再操作
hive --service hiveserver2
netstat -anp | grep 10000
#为演示效果 打开一个新的shell窗口 用jps -m 查看
jps -m
下面是这些语句分别的执行结果:
|
|
|
|
|
|



进行Hive的连接测试
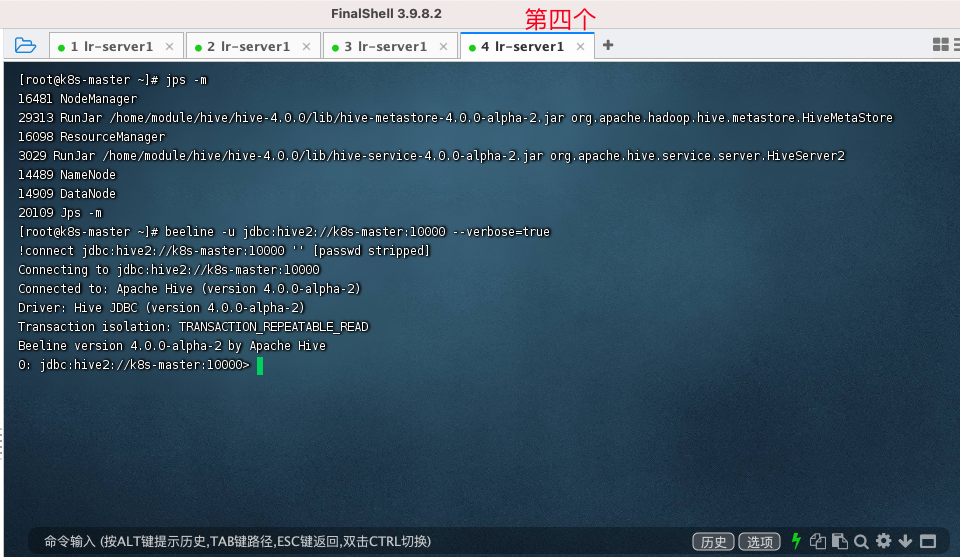
方式1: 执行beeline 命令
#最后尝试连接
beeline -u jdbc:hive2://k8s-master:10000 --verbose=true
结果如下:
|
|
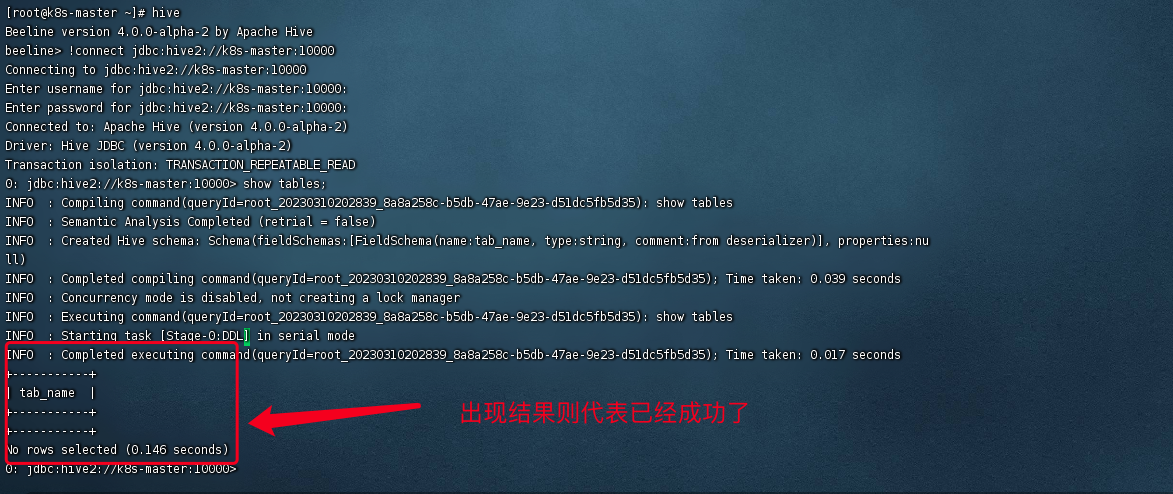
方式2: 执行hive命令
#1.执行hive
hive
#2.输入建立连接的命令
!connect jdbc:hive2://k8s-master:10000
#3.输入用户名 root 密码 随意例如:chenjia
#4.执行SQL命令
show tables;
|
|
到此已经完成 hive+hadoop的安装。

















 3361
3361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









