







目录
示例1:对输入的28x28像素的手写数字灰度图像(0到9)进行分类
示例2:对输入的4x4像素的彩色图像(R/G/B)进行两次卷积
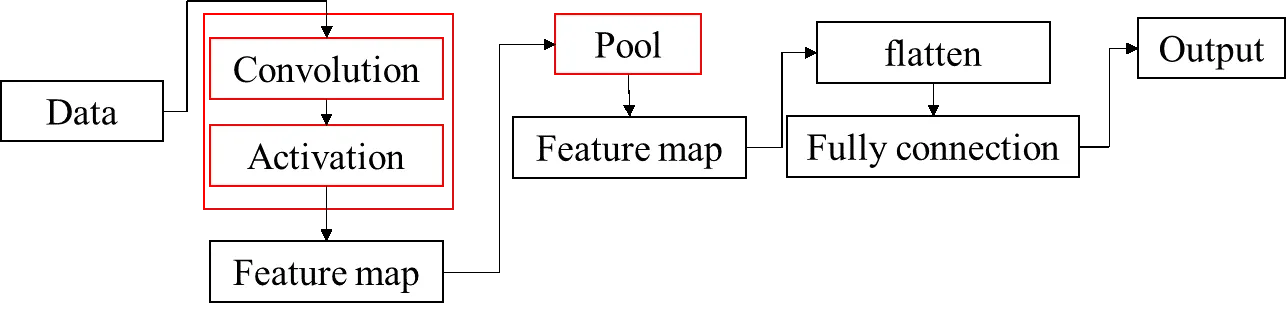
一、CNN运行过程
卷积神经网络一般是由卷积层、汇聚层和全连接层交叉堆叠而成的前馈神经网络。
卷積神經網路(Convolutional neural network, CNN) — CNN運算流程
为了详细说明CNN运行的具体细节部分,文中使用了一个8*8矩阵,在过程中只做一次卷积(2个kernel maps)、一次池化(pooling)、一层全连接(fully connection)、一层隐藏层(hidden layer)、两类output(所以有两个output nodes)。
下图中第二层出现的Map1和Map2为kernel Maps,用来做卷积运算。
其中激活函数是用来引入非线性,使机器学习能够学习和模拟更加复杂的函数映射关系。
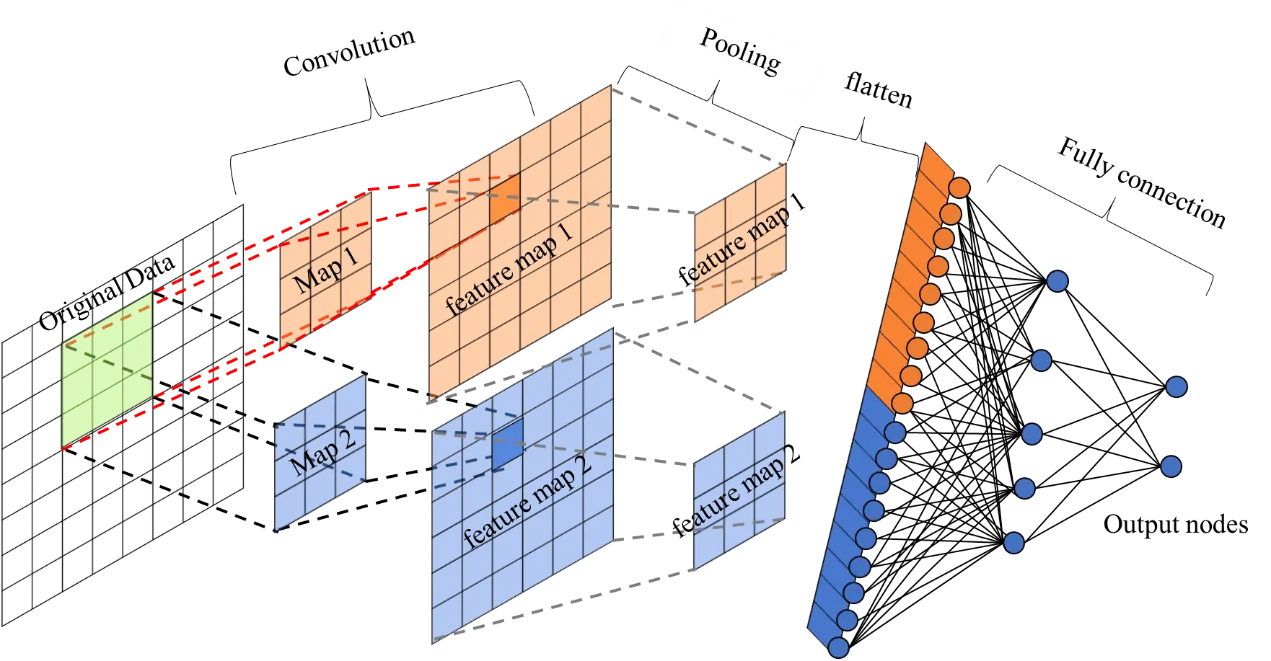
1、卷积(Convolution)
卷积运算中的mask(指卷积核,也称为滤波器或者kernel)一般称为kernel map,数量可以调整。
- 卷积核是一个小型的矩阵,它在输入数据(如图像)上滑动,通过与输入数据的局部区域进行元素乘法和求和操作来提取特征。这个过程称为卷积运算。
- 当提到"kernel maps"时,通常指的是一组卷积核,每个卷积核负责提取输入数据中的不同特征。在深度学习中,这些特征可能包括边缘、纹理、角点等不同类型的视觉模式。
- 例如上述运算中两个3*3的卷积核,其中一个可以专注于检测图像中的水平边缘,即权重在水平方向上变化,垂直方向上保持不变;另一个可以专注于检测图像中的垂直边缘,即权重在垂直方向上变化,水平方向上保持不变。
- 通过使用多个卷积核,可以并行地从输入数据中提取多种特征,然后将这些特征组合起来以识别更复杂的模式。
卷积运算的结果是一个矩阵,矩阵的大小取决于4个因素:
-
输入数据的大小:如果输入数据(如图像)是 𝑊×𝐻 的,那么在卷积操作之后,输出(称为特征图或激活图)的大小也会是 𝑊′×𝐻′,其中 𝑊′和 𝐻′取决于输入大小、卷积核大小、步长(stride)和填充(padding)。
-
步长(Stride):步长决定了卷积核在输入数据上滑动的间隔。如果步长为1,卷积核将逐个像素地移动;如果步长大于1,卷积核将跳过一些像素。
-
填充(Padding):在边缘添加填充(通常是0)可以控制输出特征图的大小。没有填充或添加较少填充可能导致输出尺寸小于输入尺寸,而添加更多的填充可以使输出尺寸保持与输入尺寸相同或更大。
-
卷积核的数量:在卷积层中,可以有多个卷积核同时工作,每个卷积核产生一个特征图。所有这些特征图堆叠在一起,形成一个三维的张量,其形状通常是 (输出高度,输出宽度,卷积核数量)。
2、激活函数(activation function)
其实这部分应该是在卷积里,只不过想单独拎出来介绍,所以额外写了一个小节。
卷积核在输入图像上进行卷积运算,产生一个特征映射(feature map)。这个特征映射是输入图像与卷积核之间点积的结果,通常是一个二维数组。
以ReLU激活函数为例,其定义为ReLU(x)=max(0,x) ,意味着任何负值将被置为0,而正值保持不变。
-
逐元素操作:ReLU激活函数是逐元素(element-wise)操作的,这意味着它将独立地应用于特征映射中的每个元素。对于一个给定的特征映射,如果其某个元素的值为-2.5,那么在应用ReLU之后,该元素的值将变为0。
-
生成新的激活映射:应用ReLU后,原始的特征映射将转换为一个新的激活映射,其中所有的负值都被转换为0。
卷积后再加上激活函数(activation function),进行非线性转换,之后得到的图片会称为特征图(feature map)。
3、池化(pooling)
池化用于降低特征图的空间维度,提取重要特征,并增加对输入变化的不变性。池化操作通常在卷积层之后应用,它可以减少模型的参数数量和计算量,同时仍然保留重要的特征信息。
以一个卷积层从输入图像中提取出来的4*4的特征图(feature map)为例:
1 3 2 4
3 5 4 6
2 5 6 7
4 7 6 83.1 池化操作
池化有助于模型对输入图像的平移、缩放和其他变化保持不变性,从而提高模型的泛化能力。
-
选择池化类型:常见的池化类型有最大池化(Max Pooling)和平均池化(Average Pooling)。这里以最大池化为例。
-
定义池化窗口:选择一个2x2的池化窗口,这是最常见的池化窗口大小。
-
滑动池化窗口:将2x2的池化窗口在整个特征图上滑动,每次滑动的步长通常与卷积层的步长相同。如果不指定步长,那么默认步长为池化窗口的大小。
-
应用池化规则:对于每个池化窗口覆盖的区域,最大池化操作会选择该区域内的最大值作为输出。
3.2 池化过程
以上面的4x4特征图为例,池化过程如下:
- 第一个窗口(左上角的2x2区域)包含的数值是:
1 3,3 5。应用最大池化操作后,选择最大的数字5作为输出。 - 将窗口向右滑动一个单位,覆盖下一个2x2区域,包含的数值是:
3 2,5 4。再次应用最大池化操作,选择最大的数字5作为输出。 - 继续这个过程,直到覆盖整个特征图。
3.3 池化后结果
最终,最大池化操作后的输出(假设步长为2,且没有重叠)将是一个2x2的特征图,如下所示:
5 6
6 8这个2x2的特征图保留了原始4x4特征图中的最大值,从而减少了特征图的尺寸,同时保留了一些重要的特征信息。
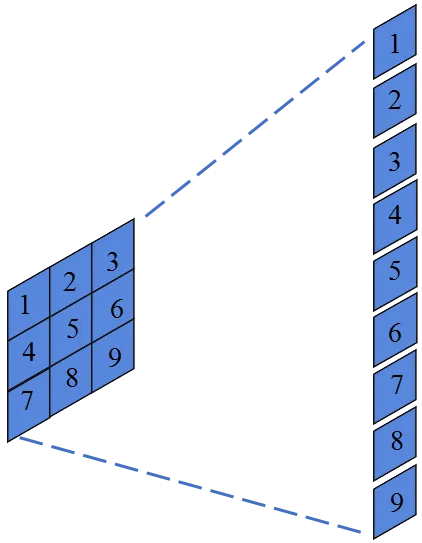
4、Flatten
Flatten层是一个用于将多维数据结构(如二维的特征图)转换为一维数据结构的操作。
这样做的目的是因为全连接层要求输入的数据是一维的,所以需要flatten将卷积层输入的2-D矩阵转为1-D阵列,方便传递给后续的全连接层。
注意:如果在做完卷积或者池化后是一个1×1的特征图(feature map),那就可以省略这个步骤。
5、全连接层
假设我们有一个简单的卷积神经网络,它包含以下层:
- 卷积层:产生一个14x14x32的特征图(例如,通过应用32个3x3的卷积核到输入图像)。
- Flatten层:将14x14x32的特征图展平成一个一维向量。
- 全连接层:接收Flatten层的输出,并进行进一步的处理。
Flatten层的操作
首先,Flatten层将卷积层的输出展平成一维向量:
14x14x32 (特征图) -> 14 * 14 * 32 = 7,168 (一维向量)意味着有一个包含7,168个元素的一维向量,每个元素对应于特征图中的一个单元格。
全连接层的配置
接下来,我们设计一个全连接层,它包含128个神经元。为了实现这一点,我们需要确保全连接层的输入维度与Flatten层的输出维度相匹配,即7168维。
权重和偏置
每个神经元在全连接层中都有7,168个权重与之相连(对应于Flatten层的7168个元素)。此外,每个神经元都有一个偏置项。因此,全连接层的权重矩阵大小为128x7168,偏置向量大小为128维。
前向传播
在前向传播过程中,全连接层的每个神经元都会对Flatten层的输出向量进行加权求和,然后加上自己的偏置项。数学上,如果将Flatten层的输出向量表示为 𝑍,全连接层的加权求和可以表示为:
Y = W * Z + b其中:
- 𝑌是全连接层的输出向量,大小为128维。
- 𝑊是权重矩阵,大小为128x7168。
- 𝑍是Flatten层的输出向量,大小为7168维。
- 𝑏是偏置向量,大小为128维。
激活函数
一旦计算出加权求和,每个神经元的输出通常会通过一个激活函数进行非线性变换。例如,如果使用ReLU激活函数,那么每个神经元的输出将是:
A = ReLU(Y)其中 𝐴是应用ReLU激活函数后的输出向量。
训练过程
在训练过程中,通过反向传播算法计算损失相对于权重 𝑊和偏置 𝑏的梯度,并使用优化算法(如梯度下降)更新它们,以减少预测和真实值之间的差异。
全连接层的特点
-
特征分类:全连接层通常位于CNN的末端,负责对卷积层和池化层提取的特征进行分类。这些特征被用来进行最终的决策,比如图像识别中的分类任务。
-
信息整合:全连接层可以将来自前一层(通常是Flatten层)的高维特征进行整合,通过加权求和以及激活函数的处理,生成用于分类的决策特征。
-
参数共享的结束:与卷积层和池化层不同,全连接层中的神经元与输入的所有元素都有连接,这意味着在全连接层中没有参数共享,每个连接都有自己的权重。
-
实现复杂函数映射:全连接层可以学习输入数据与输出结果之间的复杂关系,通过足够多的神经元和层数,全连接层能够逼近任意复杂的函数映射。
-
损失函数的计算:在神经网络的最后一层全连接层,通常会使用一个损失函数(如Softmax函数)来计算整个网络的预测输出与真实值之间的误差,这个误差将用于网络的反向传播和权重更新。
示例1:对输入的28x28像素的手写数字灰度图像(0到9)进行分类
-
输入层:输入图像具有28x28像素,通常为灰度图像(单通道),因此输入层尺寸为28x28x1。
-
卷积层:第一层可能是卷积层,其中包含多个不同的滤波器(比如32个3x3的滤波器)。这些滤波器可以检测图像中的边缘等基本特征。
-
激活函数:卷积层的输出通常会通过一个激活函数(如ReLU)来引入非线性。
-
池化层:紧随其后的可能是一个最大池化层,用于降低特征的空间维度,同时增加感受野【具体如何增加可看二、7】。
-
Flatten层:接下来,Flatten层会将卷积和池化层的多维输出(例如,经过若干卷积和池化层后可能变为14x14x32的特征图)展平成一维向量,为全连接层做准备。
-
全连接层:Flatten层的输出(例如,14x14x32 = 7,168维的一维向量)将作为全连接层的输入。第一个全连接层可能包含128个神经元,每个神经元都与Flatten层的输出完全连接。这一层将对特征进行进一步的整合和分类。
-
激活函数:全连接层的输出同样会通过一个激活函数(如ReLU)。
-
第二个全连接层:可能还会有第二个全连接层,比如含有64个神经元的层,进一步减少输出的维度并提取更高级的特征。
-
输出层:最后一个全连接层(输出层)将包含10个神经元,对应于10个类别(0到9的数字)。这个层通常使用softmax激活函数,以生成每个类别的概率分布。
在训练过程中,模型会接收包含手写数字图像及其标签的数据集。通过正向传播,模型生成预测结果,并通过损失函数(如交叉熵损失)计算预测和真实标签之间的误差。然后,反向传播算法根据这个误差调整全连接层(以及其他层)的权重,以减少预测误差。
经过足够的训练迭代,全连接层将学习到如何将提取到的特征映射到正确的数字类别上。当新的手写数字图像输入模型时,全连接层将负责生成最终的分类决策。
在上述参考的这个网页中,作者引用了之前所写的MLP笔记,为了更深入学习,我按照作者的这个思路,也学习了一遍,写在下一篇:神经网络(多层感知机Multilayer perceptron, MLP)和反向传播(Backward propagation)。
示例2:对输入的4x4像素的彩色图像(R/G/B)进行两次卷积

(1)一层卷积
设定2个3*3的kernel map,卷积层kernel的深度和输入channel有关,所以kernel map的深度为3(即输出深度),每个kernel map实际大小为3×3×3(上一层的kernel数),因此每个channel会各自对kernel map的不同深度各自做卷积,最后三个卷积结果再做Pixel-wise sum(逐像素求和,具体看二、9),所以第一层卷积输出的结果是2张(4×4)。
此时可以用以下表达式描述:
一层卷积结果=Image(R)*kernel map(:,:,1)+ Image(G)*kernel map(:,:,2)+ Image(B)*kernel map(:,:,3)
(2)二层卷积
设定3个3×3的kernel map,卷积层kernel的深度与输入channel有关,所以kernel map的深度为2,每个kernel map实际大小为3×3×2(上一层的channel数),所以2层卷积输出的结果是3张(4×4)。
二、常见术语与问题
1、感受野机制
感受野(Receptive Field)机制,是指听觉、视觉等神经系统中一些神经元的特性,即神经元只接受其所支配的刺激区域内的信号。【在CNN中,卷积层的神经元只对输入数据的一个局部区域(即感受野)进行加权求和;同样也利用了生物视觉系统通过多个层次的处理来识别视觉信息、从简单的边缘检测到复杂的形状和对象识别,CNN利用了多个卷积层逐步提取图像的高级特征。】
2、激活函数
2.1 激活函数需要具备的性质
(1)连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
(2)激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
(3)激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
2.2 激活函数作用
-
引入非线性:大多数初等数学函数,如线性函数,不具备表达复杂函数的能力。激活函数引入非线性,使得神经网络能够学习和模拟更加复杂的函数映射关系。
-
缓解梯度消失问题:在深度神经网络中,如果使用线性激活函数,可能会遇到梯度消失的问题,即反向传播时梯度值变得非常小,导致网络难以学习。激活函数如ReLU(Rectified Linear Unit)有助于缓解这个问题。
-
稀疏激活:某些激活函数,如ReLU,可以产生稀疏激活,即在给定的输入下,大部分神经元的输出为零。这有助于减少网络的计算负担,并可能提高模型的泛化能力。
-
正则化作用:激活函数可以作为一种正则化手段,防止网络中的某些神经元过度拟合数据。
-
提高训练速度:某些激活函数,如ReLU,由于其简单的数学形式,可以加快网络训练的速度。
2.3 常见激活函数
- ReLU (Rectified Linear Unit):
f(x) = max(0, x),是目前最常用的激活函数之一,因其计算简单和训练效率高而被广泛使用。 - Sigmoid:
f(x) = 1 / (1 + e^(-x)),将输入压缩到(0, 1)区间内,常用于二分类问题的最后一层。 - Tanh (双曲正切):
f(x) = (e^x - e^(-x)) / (e^x + e^(-x)),将输入压缩到(-1, 1)区间内,常用于需要输出在-1到1之间的情况。 - Softmax:在多分类问题的最后一层使用,将输出转换为概率分布。
- Leaky ReLU:
f(x) = max(ax, x),其中a是一个很小的正数,用于解决ReLU的死亡ReLU问题。 - Parametric ReLU (PReLU):
f(x) = max(ax, x),其中a是一个可学习的参数。 - Exponential Linear Unit (ELU):
f(x) = x if x > 0 else a(e^x - 1),旨在为负输入值提供更好的表达能力。
3、步长(Stride)
步长决定了卷积核在输入数据上滑动的间隔。如果步长为1,卷积核将逐个像素地移动;如果步长大于1,卷积核将跳过一些像素。
默认情况下,步长与池化窗口大小相同,例如2x2池化窗口的步长为2。减小步长可以使池化后的图像尺寸减小得不那么剧烈。
相同图片尺寸和卷积核,步长越大,图片越小。
4、零填充(Zero Padding)
在边缘添加填充(通常是0)可以控制输出特征图的大小。没有填充或添加较少填充可能导致输出尺寸小于输入尺寸,而添加更多的填充可以使输出尺寸保持与输入尺寸相同或更大。
举例来说,如果原始图像尺寸为7x7,使用3x3的池化窗口而不进行零填充,可能无法在整个图像上应用池化操作,因为窗口不能完全覆盖边界像素。通过添加一圈零填充,可以使得池化窗口能够覆盖更多的区域,从而在池化后得到一个更大的特征图。
5、池化(Pooling)
用于降低特征维度和参数数量的技术,同时能够使特征检测变得更加鲁棒。池化层通常位于卷积层之后,全连接层之前。它的主要目的是减少网络的计算量,提高计算效率,并使网络对输入图像的位移、缩放和其他变化更加不敏感。
(1)常见池化类型
-
最大池化(Max Pooling):
- 最大池化通过在一定大小的窗口(例如2x2或3x3)中选取最大值来操作。
- 这有助于保留最重要的特征(例如图像的边缘),同时丢弃不是很重要的信息。
- 最大池化能够增加对小的位置变化的不变性。
-
平均池化(Average Pooling):
- 平均池化则是计算窗口内所有值的平均数。
- 它提供了一种更为平滑的特征表示,通常不如最大池化常见,但在某些情况下仍然有用。
-
重叠池化(Overlapping Pooling):
- 传统的池化操作中,池化窗口是滑动进行的,不重叠。但在重叠池化中,池化窗口之间存在重叠,这样可以捕获更多的特征信息。
-
空间金字塔池化(Spatial Pyramid Pooling, SPP):
- 允许网络处理任意尺寸的输入图像,通过对不同尺度的特征进行池化,然后将它们合并。
- SPP通过使用不同大小的池化窗口来捕获多尺度的特征。
-
随机池化(Stochastic Pooling):
- 随机池化在训练过程中随机选择窗口中的一个值作为输出,这增加了网络的表达能力。
-
全局平均池化(Global Average Pooling):
- 将整个特征图的每个通道中的所有像素值求平均,减少全连接层的参数数量,常用于网络的最后一层,以生成类别得分。
(2)池化层的关键参数
- 窗口大小(Window Size):池化操作的窗口尺寸,如2x2或3x3。
- 步长(Stride):池化窗口滑动的间隔,步长为1表示每次滑动一个像素,步长为2表示每次滑动两个像素。
- 填充(Padding):在输入数据边缘添加额外的零值,以允许更多的池化操作。
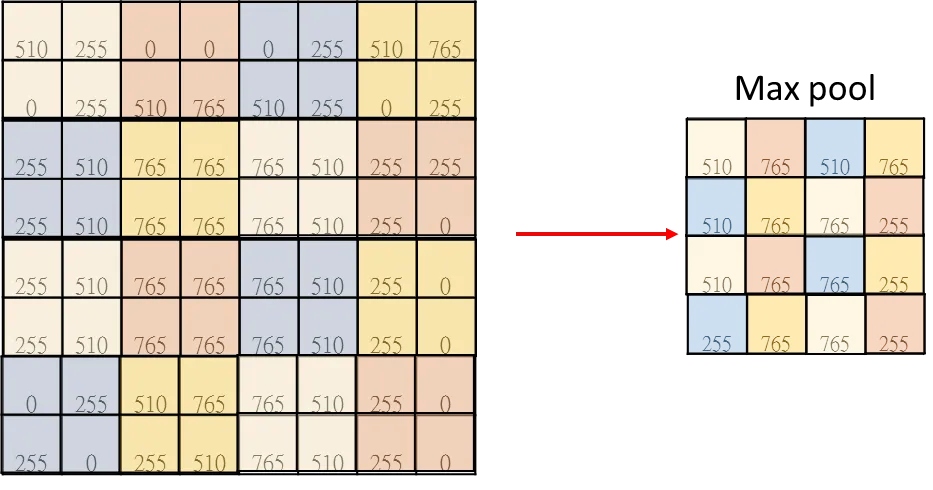

池化操作通常会减小图像的特征图尺寸,但过度的尺寸减小可能导致有用的信息丢失,因此需要适当控制池化的步长(Stride)和边界填充(Zero Padding)。
6、滤波器(Filter)
CNN中的滤波器(Filter)和卷积核(Convolutional Kernel)指的是同一个概念。它们都是用于卷积操作的小矩阵,用于从输入数据(如图像)中提取特征。
关于滤波器/卷积核的一些关键点:
-
大小:滤波器通常是一个小型的矩阵,如1x1、3x3或5x5。最常见的是3x3滤波器,因为它们在提取特征和保持图像分辨率之间取得了良好的平衡。
-
权重:滤波器的每个元素都是一个权重,这些权重在训练过程中通过反向传播算法进行学习和更新。
-
卷积操作:在卷积操作中,滤波器在输入图像上滑动(或卷积),在每个位置计算滤波器和图像的元素乘积之和,生成特征映射(Feature Map)。
-
特征提取:不同的滤波器可以检测不同的特征,如边缘、角点、纹理等。一个卷积层中可以包含多个滤波器,每个滤波器负责提取输入数据中的不同特征。
-
参数共享:在卷积操作中,同一个滤波器在整个输入图像上重复使用,这意味着相同的权重被用来提取不同位置的特征。这种参数共享减少了模型的复杂度,并提高了模型的泛化能力。
-
感受野:滤波器的感受野(Receptive Field)是指它能够覆盖的输入图像的区域。随着网络的深入,滤波器的感受野增大,能够捕捉更复杂的特征。
-
深度:在多层卷积网络中,每个卷积层的输出(即特征映射)会作为下一个卷积层的输入。因此,每个卷积层的滤波器的深度(或通道数)与前一层的输出通道数相匹配。
在不同的文献和上下文中,滤波器和卷积核可以互换使用。它们是CNN中的核心组件,负责从输入数据中提取有用的特征,为后续的分类或其他任务提供支持。
7、最大池化层如何增加感受野?
"感受野"(Receptive Field)指的是网络中某一层的神经元所能观测到的输入数据的空间范围。换句话说,它描述了网络中一个神经元对原始输入图像中的区域有多大的“视野”。
随着池化操作的进行,网络中后续层的神经元能够覆盖更大的输入图像区域。这是因为池化层的输出特征图的每个元素都是原始输入图像中更大区域的最大值(对于最大池化)。因此,当网络进一步加深时,每一层都会增加其感受野,从而能够检测到更广阔的视觉模式。
再通俗一些的理解:感受野描述了网络中某一层的神经元所“看到”的输入图像的区域大小。在第一层卷积层中,由于直接应用在原始输入图像上,感受野就是卷积核的尺寸。随着网络层次的加深,每一层的神经元实际上是在前一层所有感受野的基础上进行组合,从而形成了更大的感受野。
举个例子:
有一个如下的输入特征图,尺寸为4x4,并且使用2x2的最大池化:
A1 A2 A3 A4
B1 B2 B3 B4
C1 C2 C3 C4
D1 D2 D3 D4经过2x2的最大池化后,输出特征图可能如下所示:
P1 P2
Q1 Q2其中,P1是A1, A2, B1, B2中的最大值,P2是A3, A4, B3, B4中的最大值,依此类推。
感受野的增加
-
在卷积层:在第一层卷积层,如果使用3x3的卷积核,那么每个神经元的感受野就是3x3像素区域。
-
经过池化层:当通过一个2x2的最大池化层后,每个神经元现在实际上是在4个3x3的区域中取最大值。因此,对于下一层的卷积层来说,它的输入是来自于一个更大的区域(2x2个3x3区域),这意味着感受野增加到了2x2的区域。
-
多层网络:随着网络层次的增加,每一层都会在其前一层的基础上进一步增加感受野。例如,如果再次应用一个2x2的池化层,那么下一层的卷积神经元的感受野将会覆盖一个更大的区域。
感受野增加的影响
-
特征抽象:感受野的增加允许网络检测到更高层次的特征,如从边缘到形状,再到复杂的模式。
-
不变性:更大的感受野意味着网络对输入图像的局部变化(如平移、旋转)更加不敏感,从而提高了模型的泛化能力。
-
计算效率:尽管感受野增加,池化层通过减少特征图的空间尺寸降低了计算量。
也就是说,增加感受野,就是增加了网络中某一层的神经元所“看到”的输入图像的区域大小。
8、卷积层kernel的深度和图像的颜色通道数的关系
在卷积神经网络(CNN)中,卷积层中每个卷积核(kernel)的深度确实通常与输入图像的颜色通道数相匹配。
具体来说:
-
输入图像的颜色通道数:对于彩色图像,如RGB图像,颜色通道数通常是3。这意味着输入数据将是一个形状为 𝐻×𝑊×3的三维张量,其中 𝐻和 𝑊分别是图像的高度和宽度。
-
卷积核的深度:在卷积层中,每个卷积核都是一个具有相同深度的滤波器,这个深度与输入图像的通道数一致。对于RGB图像,卷积核也将具有深度为3,这意味着每个卷积核都是一个 𝐷×𝐷×3的张量,其中 𝐷是卷积核的尺寸,比如 3×3 或 5×5。
-
卷积操作:在卷积操作中,每个卷积核将跨越输入图像的所有通道进行加权求和。这意味着对于输入图像的每个通道,卷积核都会有一个对应的 𝐷×𝐷权重矩阵,并且这些矩阵将针对每个通道进行累加。
-
输出特征图的深度:尽管单个卷积核的深度与输入图像的通道数相匹配,卷积层输出的特征图(feature map)的深度则由该层中卷积核的总数决定。如果你有一个卷积层,它包含若干个卷积核,那么输出特征图的深度将等于这些卷积核的数量。
举个例子,如果输入图像是RGB格式的,具有3个颜色通道,卷积层有32个 3×33×3 的卷积核,那么:
- 每个卷积核的深度:将为3,与输入图像的通道数相匹配。
- 卷积层的输出深度:将为32,因为该层有32个卷积核。
这样,卷积层的每个卷积核都能够在输入图像的每个通道上检测特定的特征,而卷积层的输出将是一个深度为32的特征图,其中每个通道都是由卷积核在输入图像上滑动后生成的。
9、Pixel-wise sum(逐像素求和)
在卷积神经网络中,当处理具有多个颜色通道的图像(如RGB图像)时,每个颜色通道会分别与卷积核进行卷积操作。这里的“Pixel-wise sum”(逐像素求和)指的是将每个颜色通道与卷积核卷积后得到的二维激活图(即特征图)在相同位置的像素值相加,以生成最终的二维激活图。
具体来说:
-
独立卷积:对于一个具有 𝐶个颜色通道的输入图像,卷积核也会有 𝐶个对应的深度,使得每个卷积核可以独立地在每个颜色通道上进行卷积操作。
-
逐通道卷积:卷积核会在每个颜色通道上独立地进行卷积,得到 𝐶个二维的激活图(每个通道一个)。
-
逐像素求和(Pixel-wise sum):将上述 𝐶个二维激活图在每个像素位置上对应的值进行逐个相加。也就是说,如果卷积核在某个像素位置的卷积结果是 𝑎、𝑏和 𝑐,分别对应于 𝐶个颜色通道,那么最终在该像素位置的输出将是这三个值的总和 𝑎+𝑏+𝑐。
-
生成单个特征图:通过逐像素求和,从 𝐶个激活图中得到一个单一的二维激活图,这个激活图是输入图像在该卷积核下的响应。
-
特征图形成:卷积核在整个输入图像上滑动,对每个位置进行上述操作,最终生成整个特征图。
逐像素求和是一种将多个通道的卷积结果合并为单个通道输出的简单而有效的方法。这种方法在卷积神经网络的卷积层中非常常见,它允许网络在不同颜色通道中检测相同的特征,并将这些检测结果合并,以增强特征的表达能力。
10、ReLU激活函数如何引入非线性?
定义:ReLU(x)=max(0,x)
ReLU函数的图形是一条直线,它在x轴的正半部分是线性的,而在负半部分则是平坦的。
-
正输入保持不变:当输入值 𝑥≥0x≥0 时,ReLU函数直接输出 𝑥x,这意味着所有非负输入值保持不变,这本身就是一种非线性行为,因为线性函数会将所有输入值乘以一个常数因子。
-
负输入置零:当输入值 𝑥<0x<0 时,ReLU函数输出0。这种操作有效地在特征空间中创建了一个阈值,将所有负值置为0,这同样是一种非线性效果。
-
简化计算:ReLU函数的计算非常直接和简单,因为它只涉及比较和选择操作,这使得它在计算上非常高效,尤其是在使用现代GPU进行大规模并行计算时。
-
稀疏激活:由于负值被置为0,ReLU函数可以产生稀疏激活,这意味着在任何给定时间,网络中的许多神经元可能不会激活(即输出为0)。这种稀疏性有助于减少计算负担,并且可能提高模型的泛化能力。
-
缓解梯度消失问题:在深度神经网络中,使用传统的激活函数(如Sigmoid或Tanh)可能会导致梯度消失问题,即梯度值随着网络深度的增加而迅速减小。ReLU由于其线性部分的梯度恒定为1,可以缓解这个问题。
ReLU也有其缺点,最主要的是神经元死亡问题(即当输入为负时,ReLU的导数为零,导致权重更新停止),即在训练过程中一些神经元可能永远不会激活(输出永远为0)。为了解决这个问题,变体如Leaky ReLU和Parametric ReLU被提出,它们在负输入部分引入了非零斜率,从而允许负输入的小梯度通过。
(1)变体:Leaky ReLU
Leaky ReLU的数学表达式如下:
LeakyReLU(𝑥)=max(0,𝑥)+𝛼min(0,𝑥)
其中 𝛼是一个很小的正系数,通常设置在0到1之间。Leaky ReLU在正输入部分与ReLU相同,但在负输入部分,它会以一个较小的斜率 𝛼α 线性地增加,而不是像ReLU那样将输出置为零。
(2)变体:Parametric ReLU
Parametric ReLU(PReLU)是Leaky ReLU的一种泛化形式,其数学表达式如下:
PReLU(𝑥)=max(0,𝑥)−𝛼𝑥
或者
PReLU(𝑥)=max(0,𝑥)+𝛼min(0,𝑥)
其中 𝛼 是一个可学习的参数,它可以针对每个神经元独立调整。在训练过程中,𝛼α 会根据数据进行优化,从而为负输入提供最适合的非零斜率。
ReLU两大变体的特点
-
非零斜率:Leaky ReLU和PReLU在负输入部分有一个非零的斜率,这允许负输入的梯度可以被传播,从而缓解了神经元死亡问题。
-
参数学习:在PReLU中,斜率 𝛼α 是一个可学习的参数,这为模型提供了更大的灵活性。
-
稀疏性:尽管Leaky ReLU和PReLU减少了神经元死亡的风险,但它们仍然保留了ReLU的一些稀疏激活特性,因为正输入部分的激活仍然是稀疏的。
-
性能:Leaky ReLU和PReLU在某些情况下可以提高模型的训练性能,尤其是在面对非常深的网络结构时。
-
实现:现代深度学习框架如TensorFlow和PyTorch都提供了Leaky ReLU和PReLU的实现,使得在模型中使用这些激活函数变得非常方便。
















 5515
5515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









