






- GPU通信-硬件篇
1.Nvlink/Nvswitch
Nvlink:
NVLink 是 NVIDIA 开发的一种总线及其通信协议,采用点对点结构、串列传输,用于 CPU 与 GPU 之间的连接,也可用于多个 GPU 之间的相互连接。它由强大的软件协议和计算机板上的多对导线组成,能让处理器快速收发共享内存池中的数据。
相比传统的 PCIe 5.0,NVLink 速度更快,第四代 NVLink 速度是 PCIe 5.0 带宽的 7 倍多,且能效更高,每传输 1 字节数据仅消耗 1.3 皮焦,能效是 PCIe 5.0 的 5 倍。
NVSwitch:
NVSwitch 是基于 NVLink 技术的芯片或类似交换机的设备,可连接多个 NVLink,实现单节点内和节点间以 NVLink 能够达到的最高速度进行多对多 GPU 通信。NVLink 交换机配备 144 个 NVLink 端口,无阻塞交换能力为 14.4TB/s,是首款 ASIC 芯片技术机架级交换机,能够在无阻塞计算结构中支持多达 576 个全连接 GPU,可让 GB200 NVL72 系统中的 72 个 GPU 用作单个高性能加速器.
使用nvlink/nvswitch的:
HGX(High Performance Computing GPU Accelerator)模组形态,可定制
DGX(Deep Learning GPU Accelerator)一体机形态

2.PCIE
PCIe 是用于连接计算机主板和各种扩展设备(如显卡、网卡、固态硬盘等)的接口标准。它是 PCI 和 PCI-X 总线的继任者,旨在提供更高的带宽、更好的扩展性和性能。
以我们实验室设备为例,使用PCIe版本3.0,x16通道
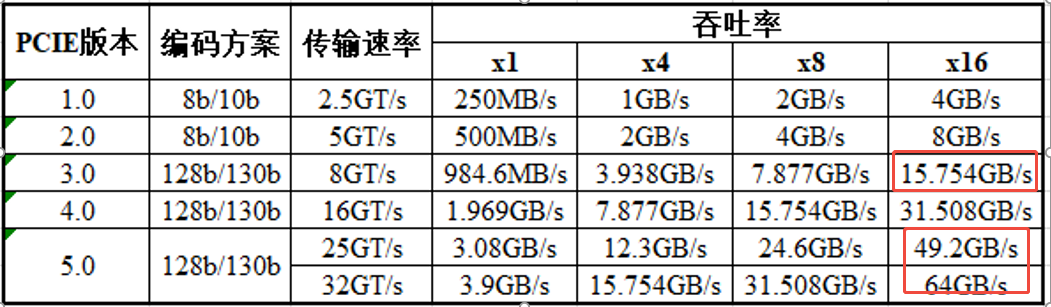
3.0版本带宽为15.7GB/s*8bit=128Gbps,若考虑跨机级联、模型并行场景同时使用RDMA时,建议使用200Gbps带宽网卡匹配PCIe带宽速率,5.0版本时PCIe带宽49GB/s*8bit=400Gbps,在预算充足的情况下甚至可配置400Gpbs网卡,以避免在极限场景下网卡成为整体环节中的通信瓶颈。
- GPU通信-软件篇
1.NCCL技术
NVIDIA Collective Communications Library是 NVIDIA 开发的一款用于多 GPU 通信的高性能库,在PCle,Nvlink,RDMA间实现较高的通信速度,
能够感知拓扑:根据集群的硬件设备信息来查找/计算每个topo算法下的带宽与时延,并结合通信数据量,选择耗时最小的路径优先。
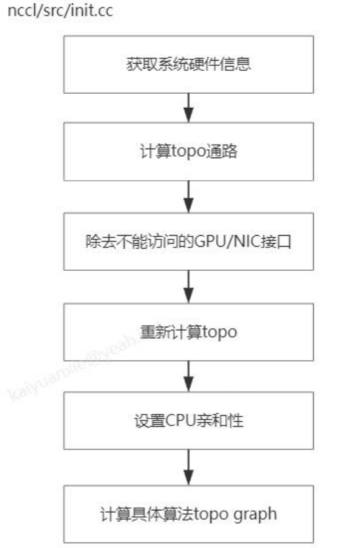
由于TP、PP需要依赖集合通信(Collective Communications),需要依赖多种通信原语,涉及点对点、多对多AllGather以及一些场景下的AllReduce、ReduceScatter等通信原语都能通过NCCL来实现。
这里是一些主流厂家的集合通信库:

2.并行技术:
在需要部署参数量较大的模型但GPU显存不足时,可以应用并行技术实现,以下是常见的并行技术:
a.数据并行 (Data Parallelism)
即将数据集分成多个子集,每个子集分配给不同的计算节点(GPU),每个节点上都有完整的模型副本,每个节点处理不同的数据子集,计算梯度后,通过集合通信(如AllReduce)同步梯度,更新模型参数。
b.张量并行(Tensor Parallelism)
张量并行将模型的张量(如权重矩阵)按维度切分到不同的计算节点上。
将大型张量按行或列切分,每个节点处理切分后的子张量。需要通过集合通信操作(如AllGather或AllReduce)来合并结果。
如我们环境验证中,可以看到大量的AllReduce,用于合并分片在各GPU上的局部计算结果:
c.流水线并行 (Pipeline Parallelism)
流水线并行将模型按层或模块顺序切分成多个阶段,每个阶段分配到不同的计算节点上,形成流水线。将模型按层或模块分成多个阶段,每个阶段在不同的节点上执行。数据在节点间依次传递,形成流水线。
PP的主要流量来自于不同stage进行中间激活值的传递,主要通信原语为:Send/Recv

d.其他如混合并行 (Hybrid Parallelism) 微批次并行 (Micro-Batch Parallelism)等等
由于DP对多卡GPU要求较高,且常用于训练场景,我们受限于硬件资源并未测试,我们分别测试了TP以及PP模式,
e.理论计算:
TP:

以我们TP=8时,通信量约为:(2*2*H*S*B+2*2*H*S*B)*L
以我们TP=4&PP=2时,通信量约为:2*H*S*B

我们本次测试使用的是QWQ模型,我们通过打印模型结构可以看到由64个decoder组成,即64层,L=64,结合上述公式去除相同项,可以看到TP=8是TP=4&PP=2的4L倍,由于我们模型L=64,即两者流量理论上相差256倍(粗估)
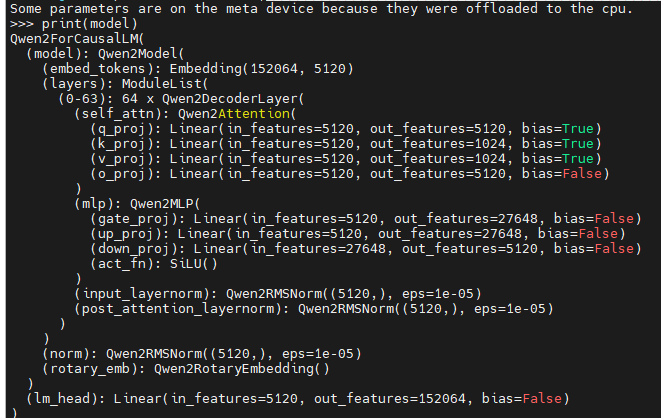
结合我们测试数据如下:
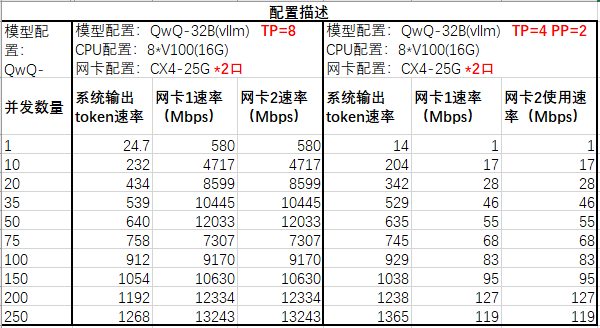
可以看到在并发10-50间,基本符合这个规律(17*256=4352对比4717、46*256=11776对比10445),但并发超过75以后,速率发生下降,这里没有找到太多线索解释,初步推测可能为显卡瓶颈,欢迎讨论。
优劣势:
TP:
优点:适用于单个张量过大的情况,可以显著减少单个节点的内存占用。
缺点:通信开销较大,特别是在切分维度较多时。
PP:
优点:可以减少单个节点的内存占用,适用于深度模型。
缺点:实现复杂,存在流水线填充和空闲时间,可能导致效率降低.
当并发数不多时,PP可能存在气泡空窗,利用率不如TP,如我们测试并发在50以内时PP略高于TP,当并发数较多时,气泡空窗占满,PP token速率接近或略多于TP模式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









