






原文链接
原文内容
在爬取网页时,由于会遇到登录问题而被阻止,此时通过改变头部信息来解决此问题
以爬取京东商品页面为例
1、先登录京东账号

2、摁F12进入调试页面,然后刷新页面,在Network栏中的第一行会出现一个document文件
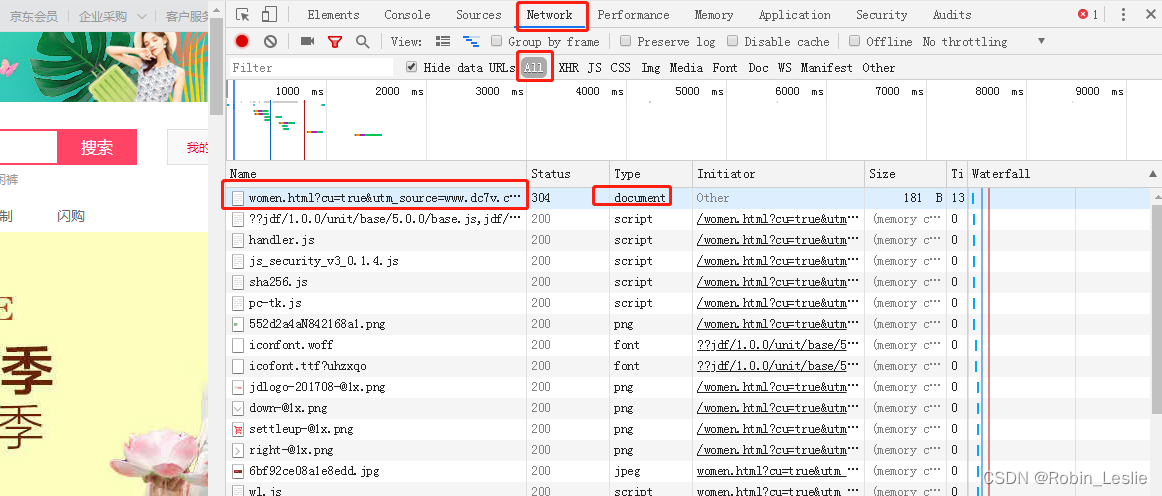
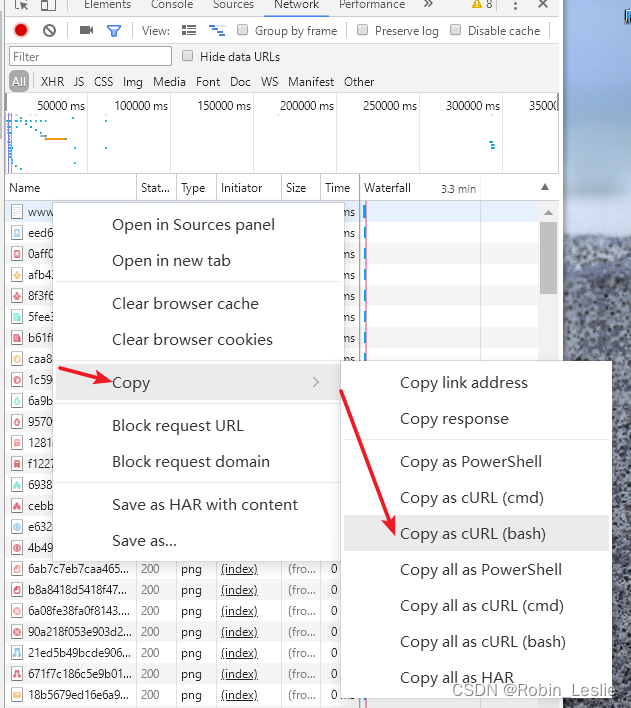
3、在那个文件上点右键,Copy→Copy as cURL(bash)
4、进入网站 https://curl.trillworks.com 将curl command转为Python requests如图
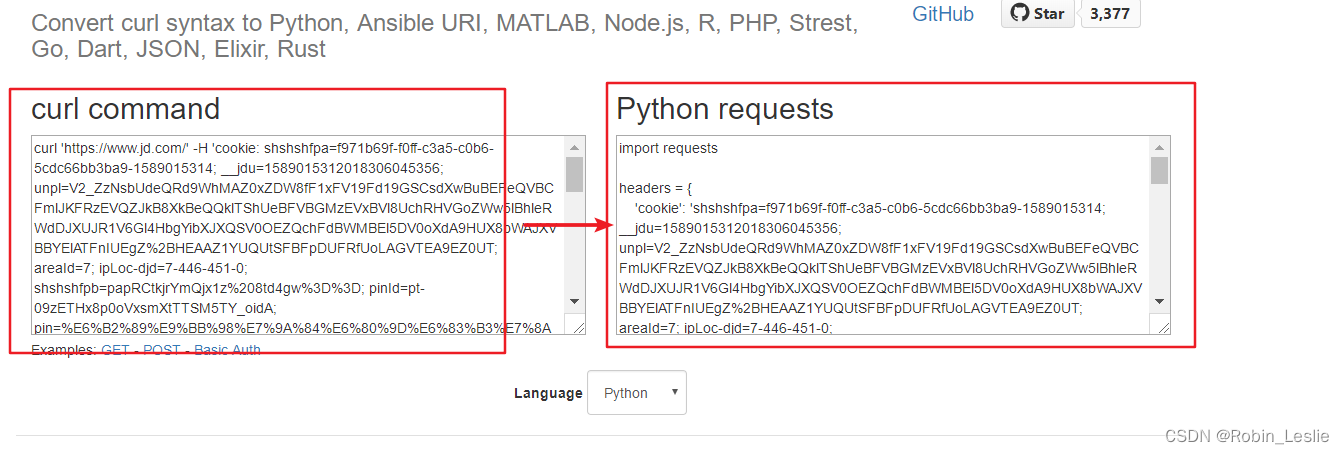
5、复制右侧的headers信息,放到代码中,并在get方法中添加headers = headers来修改
import requests
url = "https://search.jd.com/Search?keyword=%E5%B1%B1%E5%9C%B0%E8%BD%A6&qrst=1&wq=%E5%B1%B1%E5%9C%B0%E8%BD%A6&stock=1&page=1&s=1&click=1"
headers = { 'cookie': 'hf_time=1589015315632; shshshfpa=f971b69f-f0ff-c3a5-c0b6-5cdc66bb3ba9-1589015314; __jdu=1589015312018306045356; unpl=V2_ZzNsbUdeQRd9WhMAZ0xZDW8fF1xFV19Fd19GSCsdXwBuBEFeQVBCFmlJKFRzEVQZJkB8XkBeQQklTShUeBFVBGMzEVxBVl8UchRHVGoZWw5lBhleRWdDJXUJR1V6Gl4HbgYibXJXQSV0OEZQchFdBWMBEl5DV0oXdA9HUX8bWAJXVBBYElATFnIUEgZ%2BHEAAZ1YUQUtSFBFpDUFRfUoLAGVTEA9EZ0UT; __jda=122270672.1589015312018306045356.1589015312.1589015313.1591000469.2; __jdc=122270672; shshshfp=e60b23c677f56f7de454dd9e75dd9593; areaId=7; ipLoc-djd=7-446-451-0; shshshfpb=papRCtkjrYmQjx1z%208td4gw%3D%3D; wlfstk_smdl=ovi6wdn0id567r9dnz3n8eo5ja29vw5j; TrackID=1wnyJS9zQtA1Xz9kMKFtKggxuYI0d5lUrC_ySVCL0SkGlk-qsl0FskEQwaUnuLrlWw036wa1LEy5yuj8Jl48N559nTbhOrGcNPy0Y44FeMfk; pinId=pt-09zETHx8p0oVxsmXtTTSM5TY_oidA; pin=%E6%B2%89%E9%BB%98%E7%9A%84%E6%80%9D%E6%83%B3%E7%8A%AF; unick=%E6%B2%89%E9%BB%98%E7%9A%84%E6%80%9D%E6%83%B3%E7%8A%AF; ceshi3.com=000; _tp=NYrLbYIabKc8yOVdkCkHbs7ByvhIM3%2BOLTVEe3DHDIcRs2p4qg7bsDieKH4THslbeQW0ODro8nL0TU0I2temcg%3D%3D; _pst=%E6%B2%89%E9%BB%98%E7%9A%84%E6%80%9D%E6%83%B3%E7%8A%AF; __jdv=122270672|kong|t_1000023384_129805|zssc|48339cde-d499-4061-a3f1-a52486b22602-p_1999-pr_2383-at_129805|1591000496693; rkv=V0700; 3AB9D23F7A4B3C9B=NB2B47LNZTEFHGRNKWGM4PKE6H6NGEDPOHVY5GMC7TBTVHQITB7QQ2OL5ZFJMKVVY5FJMCLMSRRG2LSVEH3GV6PDRE; thor=B8CE64DE7AFCD9D5A2AD3B5D4F008F260F069EDC7DA977213C9CAF86AF2897F5DE867AE9EF30E9C96E72D36E9E743194FE1C72106AC4EDBA3BCF2DB7203C9AF2876BBDAF4FED245054B5284F459DB5A098AF8F7D3661D0B044D918AA44991B88F618EE16BB5A0ACDC14768B7EA13DC22BBCD30AD3F72A95F7D3503100973B942; qrsc=3; __jdb=122270672.9.1589015312018306045356|2.1591000469; shshshsID=b2bc0dae971b23dc87a3e49b9e2281f7_6_1591000797147',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'cache-control': 'max-age=0',
'authority': 'search.jd.com',
'referer': 'https://search.jd.com/search?keyword=%E5%B1%B1%E5%9C%B0%E8%BD%A6&qrst=1&wq=%E5%B1%B1%E5%9C%B0%E8%BD%A6&stock=1&ev=exbrand_%E7%BE%8E%E5%88%A9%E9%81%94%EF%BC%88MERIDA%EF%BC%89%5E',}
r = requests.get(url,headers = headers,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
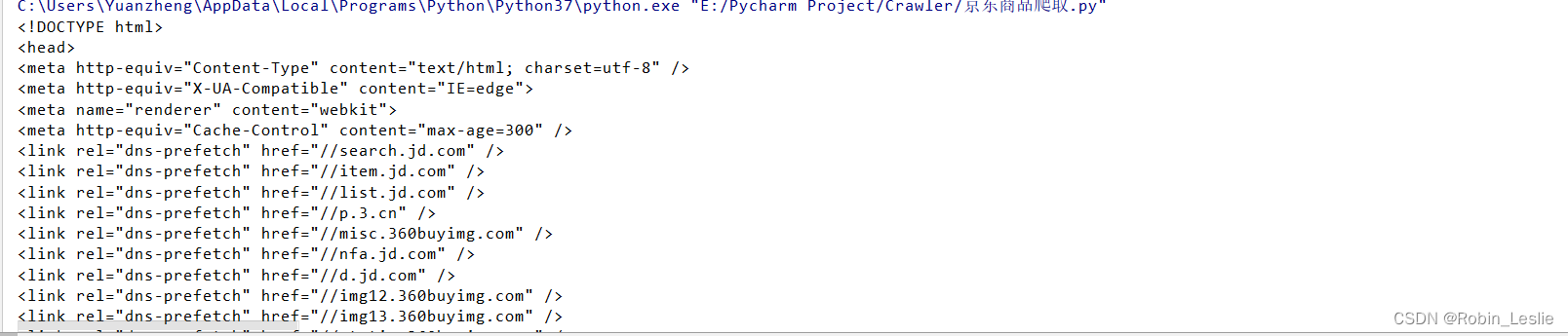
爬取结果:

















 6725
6725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









