







一. 环境
1. Hadoop
下载地址: http://hadoop.apache.org/common/releases.html
版本:hadoop-2.4.1.tar.gz
2.Jdk
下载地址:http://hadoop.apache.org/common/releases.html
版本: jdk-8u11-linux-i586.tar.gz
二、安装前提
SSH无密码登陆设置完成
参见我的这篇博客:http://blog.csdn.net/zheyejs/article/details/38639435
三、Hadoop安装配置
1、Hosts配置
vim /etc/hosts将主机,从机的ip以及主机名写入(注意别让172.0.1.1 的名和本机主机名一样,可以删除该行),hosts文件内容如下:
127.0.0.1 localhost
# 127.0.1.1 master-hadoop
192.168.1.120 master-hadoop
192.168.1.121 slave1-hadoop
192.168.1.122 slave2-hadoop
192.168.1.123 slave3-hadoop
192.168.1.124 slave4-hadoop
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
四、安装JKD
tarzxvf jdk-8u11-linux-i586.tar.gz
mvjdk1.7.0_17/ /usr/local/jdk
vi/etc/profileJAVA_HOME=/usr/local/jdk
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export JAVA_HOME CLASSPATHPATH
source /etc/profile
java –version #查看版本信息五、Hadoop安装配置
1、Hadoop安装
方法同JDK,这里我是装在了/home/hadoop下
环境变量如下
HADOOP_HOME=/home/hadoop/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME PATH
2、hadoop-env.sh设置jdk路径
cd hadoop/etc/hadoop/
vi hadoop-env.sh在文件末尾加上:export JAVA_HOME=/usr/local/jdk/
3、slaves设置从节点
vi slaves在此加上从节点主机名,跟上面的/etc/hosts对应:
slave1-hadoop
slave2-hadoop
4、添加相关文件夹
在/home/hadoop/hadoop中添加tmp文件夹
在/home/hadoop/hadoop/share/hadoop中添加data和name文件夹
5、core-site.xml
<configuration>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master-hadoop:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
</configuration>
6、hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/share/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/home/hadoop/hadoop/share/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name> <!--数据副本数量,默认3,我们是两台设置2-->
<value>1</value>
</property>
</configuration>
7、yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master-hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master-hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master-hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master-hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master-hadoop:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
8、mapred-site.xml
注意:这里没有该文件,只有mapred-site.xml.example,将这个example文件复制并改名为mapred-site.xml即可
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master-hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master-hadoop:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>nistest.master:9001</value>
</property>
</configuration>
8、至此,已经设置完成,现在将整个hadoop文件夹复制到所有slave从机上,注意目录应该相同。
scp –r /home/hadoop/hadooproot@slave2-hadoop:/home/hadoop六、格式化文件系统并启动。
1、格式化
hdfs namenode –format注意:所有的slave也得进行该操作
2、启动
start-dfs.sh然后查看主机和从机分别启动了哪些进程
jps主机:NameNode/Jps/SecondaryNameNode
从机:DataNode/Jps
Start-yarn.ships
主机:NameNode/Jps/SecondaryNameNode/ResourceManger
从机:DataNode/Jps/NodeManger
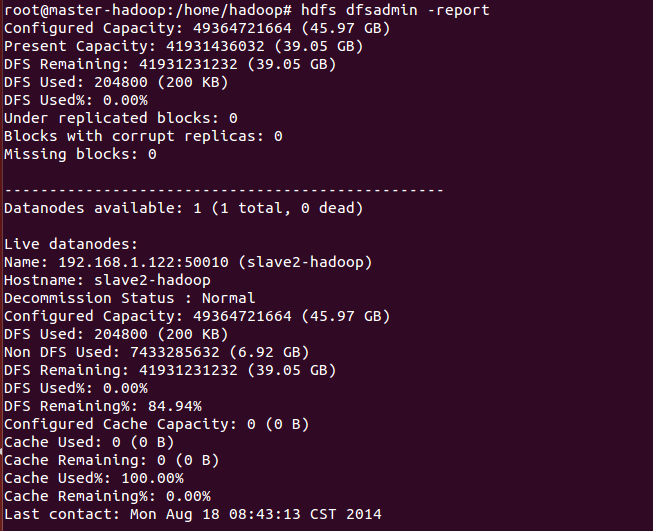
3、查看集群状态
hdfs dfsadmin –report
4、浏览器访问 http://192.168.1.120:8088

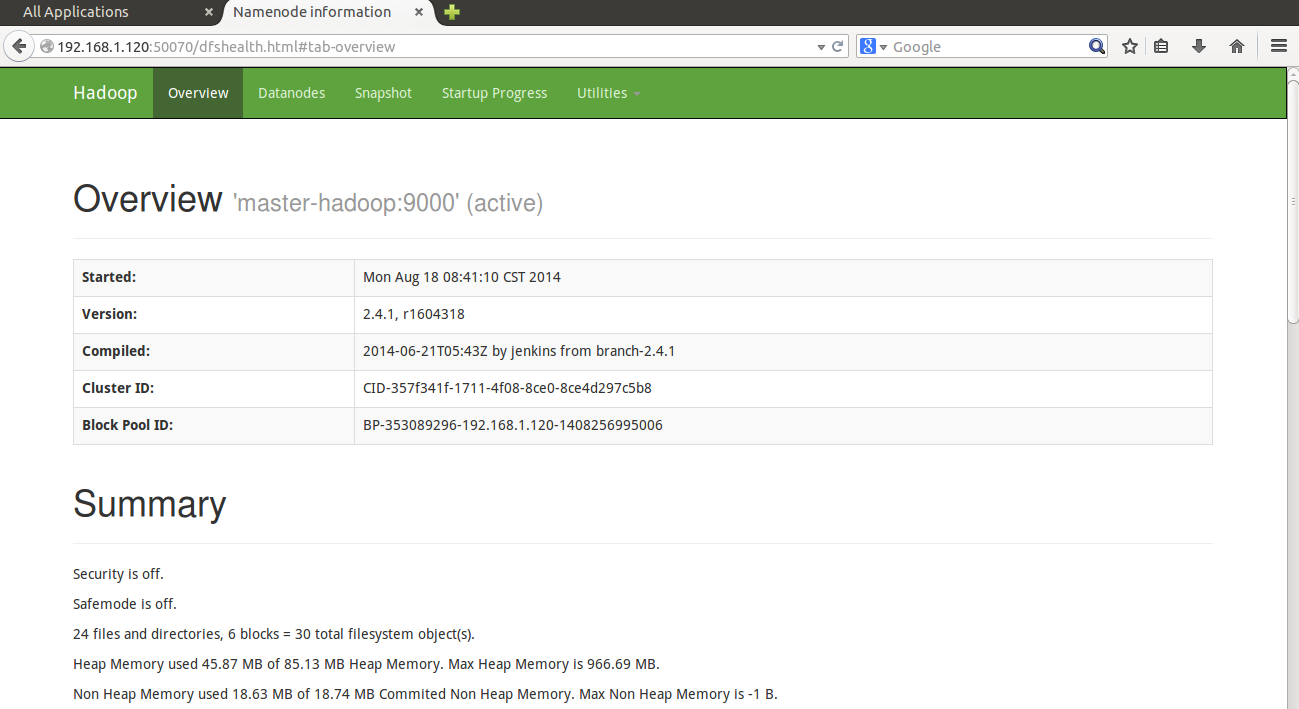
5、浏览器访问 http://192.168.1.120:50070















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









