






一、树
使用列表作为其他列表中元素的能力为编程语言提供了一种新的组合方式。这种能力称为数据类型的闭包属性(closure property)。一般来说,如果某种数据值组合得到的结果也可以用相同的方法进行组合,则该方法具有闭包属性。(「数学中,若对某个集合的成员进行一种运算,生成的仍然是这个集合的成员,则该集合被称为在这个运算下闭合。」)
闭包是所有组合方式的关键,因为它使我们可以创建层次结构——由“部分”组成的结构,部分其本身也由部分组成。
我们可以使用方框指针表示法(box-and-pointer notation) 在环境图中可视化列表。列表被描述为包含列表元素的相邻框。数字、字符串、布尔值和 None 等原始值出现在元素框内。复合值如函数值和列表等由箭头指示。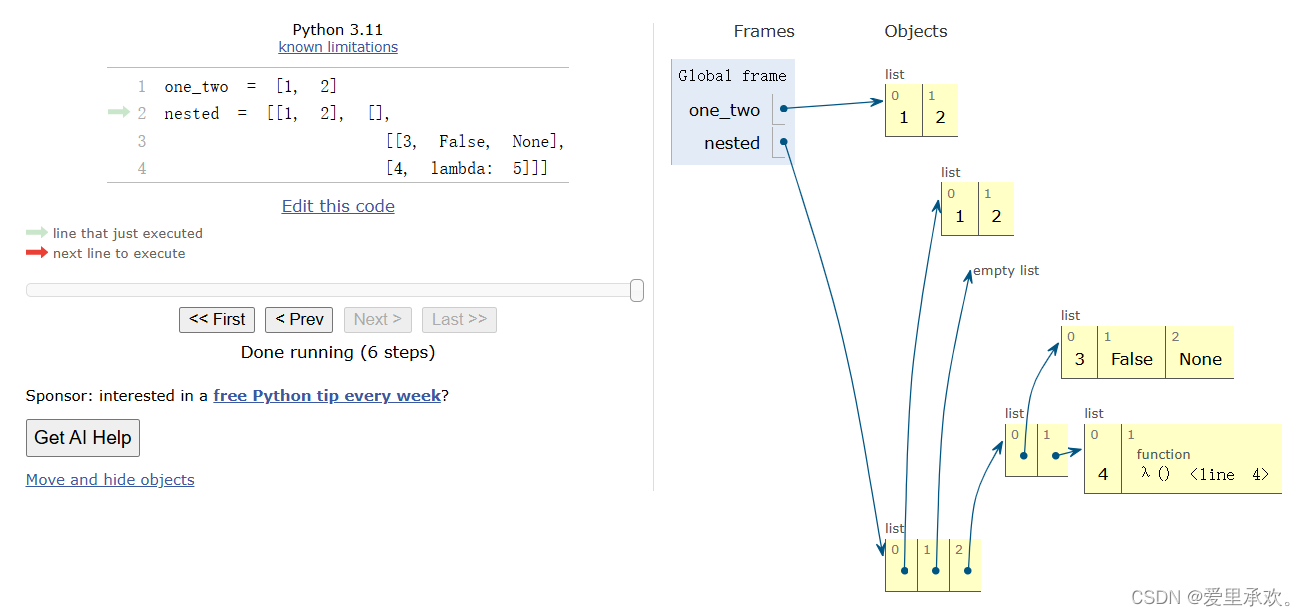

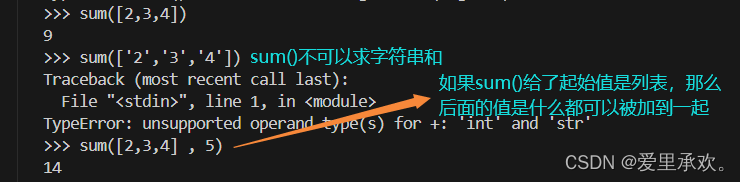
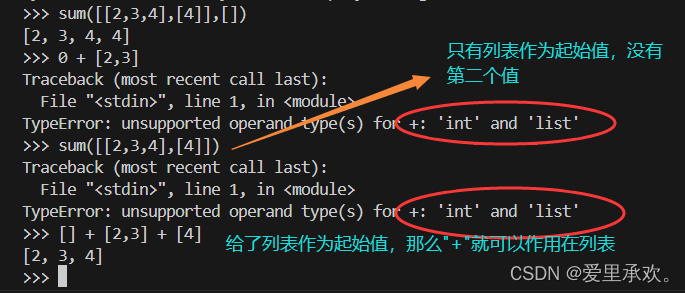

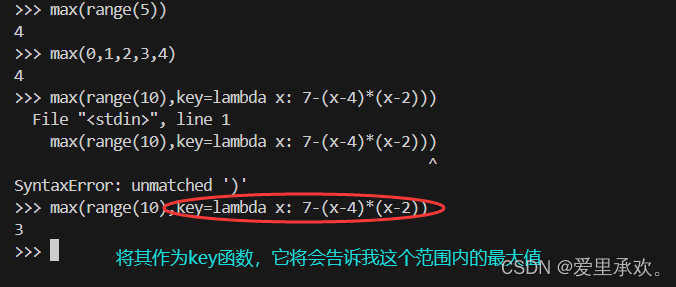
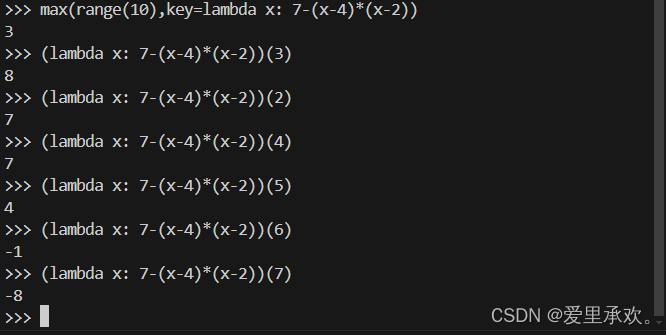

上图中的"key"函数会将这个函数应用于我们传入的每一个参数,并根据调用这些函数的返回值计算最大值。
在列表中嵌套列表可能会带来复杂性。树(tree)是一种基本的数据抽象,它将层次化的值按照一定的规律进行组织和操作。
一个树有一个根标签(root label)和一系列分支(branch)。树的每个分支都是一棵树,没有分支的树称为叶子(leaf)。树中包含的任何树都称为该树的子树(例如分支的分支)。树的每个子树的根称为该树中的一个节点(node)。
树的数据抽象由构造函数 tree、选择器 label 和 branches 组成。我们从简化版本开始讲起。
>>> def tree(root_label, branches=[]):
for branch in branches:
assert is_tree(branch), '分支必须是树'
return [root_label] + list(branches)
>>> def label(tree):
return tree[0]
>>> def branches(tree):
return tree[1:]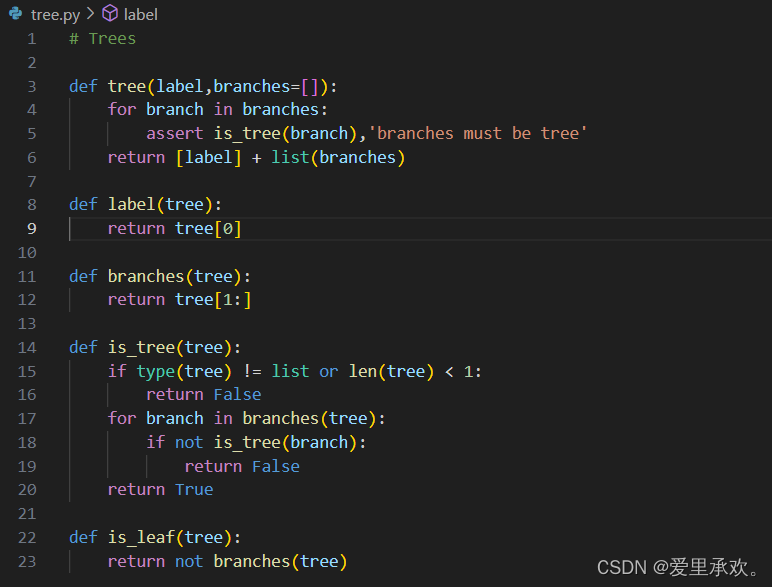
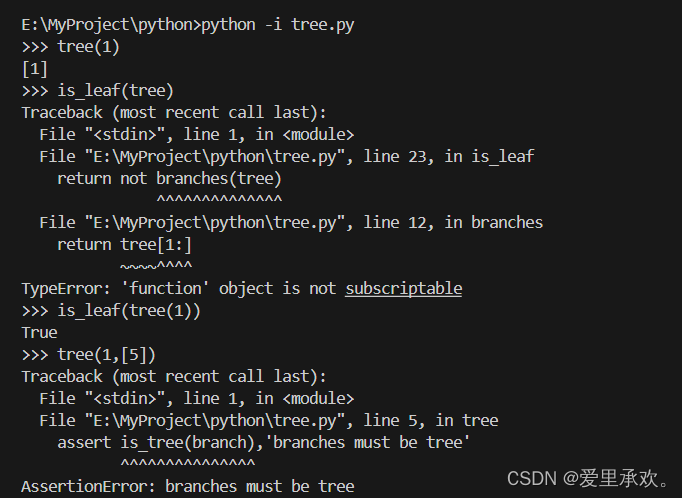


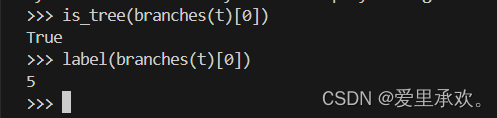
只有当树有根标签并且所有分支也是树时,树才是结构良好的。在 tree 构造函数中使用了 is_tree 函数以验证所有分支是否结构良好。
>>> def is_tree(tree):
if type(tree) != list or len(tree) < 1:
return False
for branch in branches(tree):
if not is_tree(branch):
return False
return Trueis_leaf 函数检查树是否有分支,若无分支则为叶子节点。
>>> def is_leaf(tree):
return not branches(tree)树可以通过嵌套表达式来构造。以下树 t 具有根标签 3 和两个分支。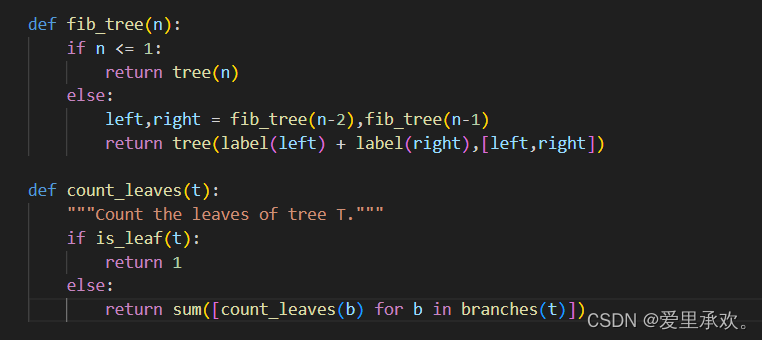
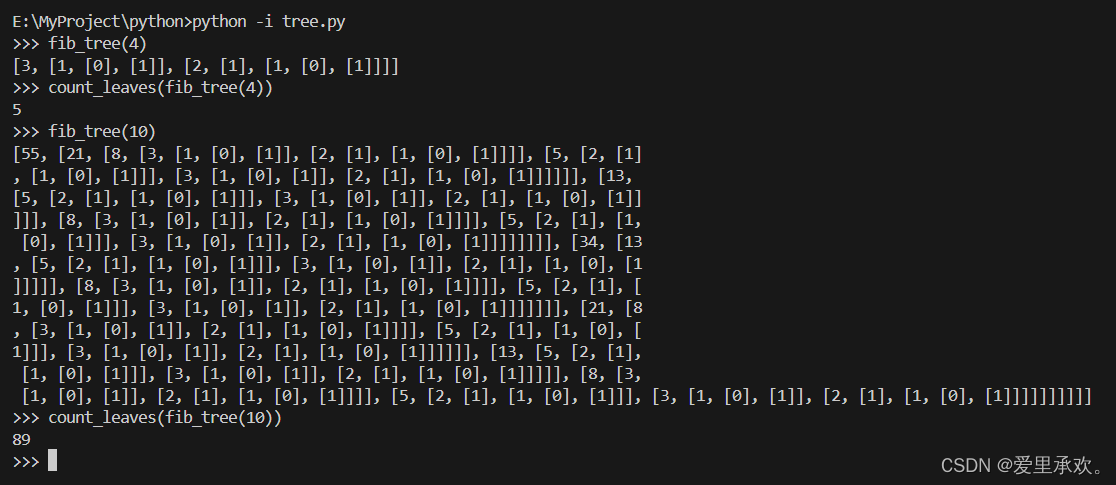
>>> t = tree(3, [tree(1), tree(2, [tree(1), tree(1)])])
>>> t
[3, [1], [2, [1], [1]]]
>>> label(t)
3
>>> branches(t)
[[1], [2, [1], [1]]]
>>> label(branches(t)[1])
2
>>> is_leaf(t)
False
>>> is_leaf(branches(t)[0])
True树递归(Tree-recursive)函数可用于构造树。例如,我们定义 The nth Fibonacci tree 是指以第 n 个斐波那契数为根标签的树。那么当 n > 1 时,它的两个分支也是 Fibonacci tree。这可用于说明斐波那契数的树递归计算。
>>> def fib_tree(n):
if n == 0 or n == 1:
return tree(n)
else:
left, right = fib_tree(n-2), fib_tree(n-1)
fib_n = label(left) + label(right)
return tree(fib_n, [left, right])
>>> fib_tree(5)
[5, [2, [1], [1, [0], [1]]], [3, [1, [0], [1]], [2, [1], [1, [0], [1]]]]]树递归函数也可用于处理树。例如,count_leaves 函数可以计算树的叶子数。
>>> def count_leaves(tree):
if is_leaf(tree):
return 1
else:
branch_counts = [count_leaves(b) for b in branches(tree)]
return sum(branch_counts)
>>> count_leaves(fib_tree(5))
8我们还可以打印出我们想要的树的形态。
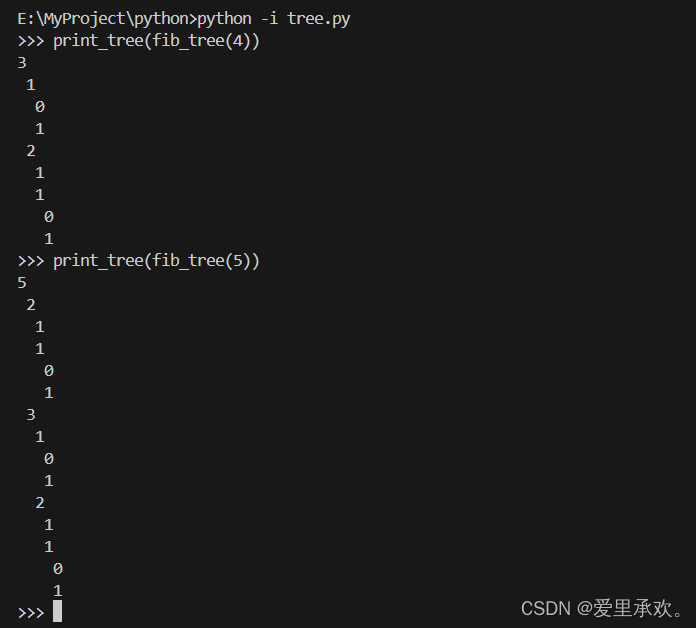
def print_tree(t,index=0):
print(' '*index + str(label(t)))
for b in branches(t):
print_tree(b,index+1)我们还可以从根到叶子来打印每一个路径上的值的和。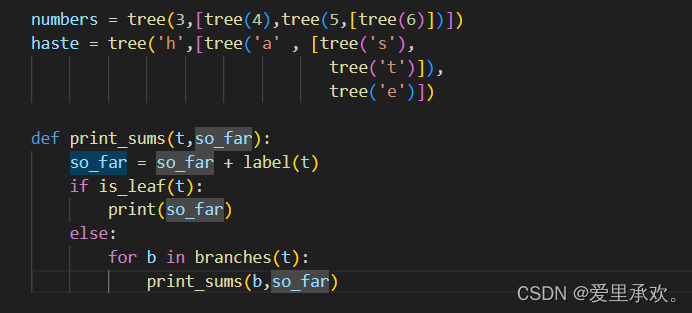
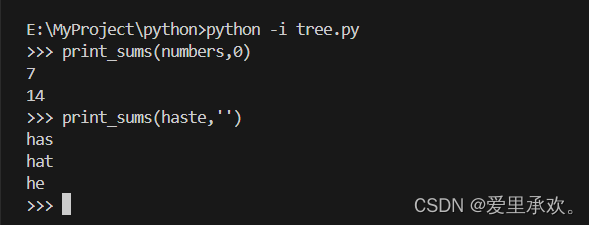
numbers = tree(3,[tree(4),tree(5,[tree(6)])])
haste = tree('h',[tree('a' , [tree('s'),
tree('t')]),
tree('e')])
def print_sums(t,so_far):
so_far = so_far + label(t)
if is_leaf(t):
print(so_far)
else:
for b in branches(t):
print_sums(b,so_far)分割树(Partition trees):树也可以用来表示将一个正整数分割为若干个正整数的过程。比如可通过一个形式为二叉树的分割树来表示将 n 分割为不超过 m 的若干正整数之和的计算过程中所做的选择。在非叶子节点的分割树节点中:
• 根标签是 m。
• 左侧(索引 0)分支包含划分 n 时至少使用一个 m 的所有方法
• 右侧(索引 1)分支包含划分 n 时使用的正整数不超过 m - 1 的所有方法
分割树叶子节点上的标签表示从树根到叶子的路径是否分割成功。
>>> def partition_tree(n, m):
"""返回将 n 分割成不超过 m 的若干正整数之和的分割树"""
if n == 0:
return tree(True)
elif n < 0 or m == 0:
return tree(False)
else:
left = partition_tree(n-m, m)
right = partition_tree(n, m-1)
return tree(m, [left, right])
>>> partition_tree(2, 2)
[2, [True], [1, [1, [True], [False]], [False]]]我们可以以 n = 6,m = 4 为例,尝试“将 6 分割为不超过 4 的若干正整数之和”。首先,所有的分割方式可以被分两类:
- 使用至少一个 4 来分割
- 使用不超过 3 的若干正整数来分割
让我们再进一步简化:
- 使用至少一个 4 来分割,即:先将 6 分割出一个 4,再将余下的(6 - 4 = 2)分割为不超过 4 的若干整数之和。
- 使用不超过 3 的若干整数来分割,即:“将 6 分割为不超过 3 的若干整数之和”。
我们发现,它们都可以抽象出同样的形式,只是参数不同。那么就可以用递归的方法来处理,直接将再次调用
partition_tree得到的结果作为自己的左右分支。除此之外,我们还需明确递归的出口,即什么情况记为分割成功(True),什么情况记为分割失败(False),包括:
- 成功分割:一旦分割后的 n = 0,说明已经完成分割,返回
True- 不成功分割:分割后的 n < 0,说明正整数之和已经超过最初被分割的 n,不符合要求;m 递减至 0,不符合需要分割为正整数的要求,这两种情况都应返回
False
另一个遍历树的树递归过程是将分割树的所有分割方案打印。每个分区都构造为一个列表,当到达叶子节点且节点标签为 True 时就会打印分区。
>>> def print_parts(tree, partition=[]):
if is_leaf(tree):
if label(tree):
print(' + '.join(partition))
else:
left, right = branches(tree)
m = str(label(tree))
print_parts(left, partition + [m])
print_parts(right, partition)
>>> print_parts(partition_tree(6, 4))
4 + 2
4 + 1 + 1
3 + 3
3 + 2 + 1
3 + 1 + 1 + 1
2 + 2 + 2
2 + 2 + 1 + 1
2 + 1 + 1 + 1 + 1
1 + 1 + 1 + 1 + 1 + 1切片操作同样适用于树的分支。例如我们可能想限制树的分支数量。二叉树就是这样有分支数量限制的树,二叉树可以是单个叶子节点,也可以是一个最多包含两个二叉树分支的节点。二叉树化(binarization)是一种常见的树转换方法,通过将相邻的分支组合在一起来从原始树计算出二叉树。
>>> def right_binarize(tree):
"""根据 tree 构造一个右分叉的二叉树"""
if is_leaf(tree):
return tree
if len(tree) > 2:
tree = [tree[0], tree[1:]]
return [right_binarize(b) for b in tree]
>>> right_binarize([1, 2, 3, 4, 5, 6, 7])
[1, [2, [3, [4, [5, [6, 7]]]]]]二、可变数据
2.1、对象隐喻
对象 (objects) 将数据的值和行为结合到了一起。对象可以直接表示某些信息,也可以用自身的表现行为来表达想表达的东西。一个对象具体应该怎么和其它对象进行交互,都被封装并绑定到了该对象自身的某些值上。当我们试图打印某个对象时,它自己知道应该如何以文字的形式表示自己。如果一个对象由多个部分组成,它知道应该怎么根据实际情况对外展示那些不同的部分。对象既是数据信息又是操作流程,它把二者结合到一起,从而表达复杂事物的属性、交互和行为。
在 Python 中,对象的行为是通过特定的语法和术语实现的,以日期为例:
>>> from datetime import datedate 这个名称是一个 class 类,正如我们所见,一个类代表了一种值。具体的日期被称为这个日期类的实例对象。要想构建一个实例对象,可以用特定的参数去调用该类得到:
>>> tues = date(2014, 5, 13)尽管 tues 是用基础数字构建出来的,但它具有日期的能力。举个例子,用另一个日期减掉它,我们可以得到一个时间间隔。我们可以打印一下这个间隔:
>>> print(date(2014, 5, 19) - tues)
6 days, 0:00:00对象有属性(attributes)的概念,可以理解为该对象中某个值的名字。和其它许多编程语言一样,我们在 Python 中使用点语法来访问一个对象中的某个属性。
>>> <expression> . <name>在上面的代码中,<expression> 表示一个对象,<name> 表示该对象中对某个属性的名称。
与之前介绍的其它变量名称不同,这些属性名称无法在运行环境中直接访问。属性名称是对象实例所独有的,只能通过点语法来访问。
>>> tues.year
2014对象还有方法(methods)的概念,其实也是属性,只不过该属性的值是函数。对象知道如何执行这些方法。具体实现起来,方法就是根据其自身的输入参数以及它所在的对象来计算特定结果的函数。举例来说,strftime (string format of time) 方法接受一个参数,该参数描述了具体的时间展示格式(e.g., %A 表示以完整格式返回星期)。
>>> tues.strftime('%A, %B %d')
'Tuesday, May 13'要计算 strftime 的返回值需要两个输入:期望展示的时间格式,以及 tues 中包含的日期信息。这个方法内部已经有了处理日期相关的逻辑,并且能够返回我们期望的结果。我们从来没有说过 2014 年 5 月 13 日是星期二,但是日期这个类本身就有这种能力,它能够知道一个特定的日期应该是星期几。通过把数据和行为绑定到一起, Python 为我们提供了一个已经完全抽象好的、可靠的 date 对象。
不仅 date 是对象,我们之前提到的数字、字符串、列表、区间等都是对象。它们本身表示数据,同时还拥有它们所代表的数据的行为。它们还有属性和方法。举例来说,字符串有一系列帮助我们处理文本的方法。
>>> '1234'.isnumeric()
True
>>> 'rOBERT dE nIRO'.swapcase()
'Robert De Niro'
>>> 'eyes'.upper().endswith('YES')
True实际上,Python 中所有的值都是对象。也就是说,所有的值都有行为和属性,它们拥有它们所代表的数据的行为。


上面的encode()命令可以通过以字节为单位查看编码,输出的是代表婴儿所需的四个字节。
2.2、序列对象
像数字这样的基本数据类型的实例是不可变(immutable)的。它们所代表的值,在程序运行期间是不可以更改的。 另一方面,列表就是可变的(mutable)。
可变数据用来表示那些会在程序运行期间发生变化的数据。时间每天都在流逝,虽然一个人在一天天地长大、变老,或者有一些其它什么变化,但是这个人还是这个人,这一点是没有发生变化的。类似地,一个对象也可能通过某些操作更改自身的属性。举例来说,一个列表中的数据是可能会发生变化的。大部分变化的发生,都是通过调用列表实例的方法来触发的。
我们可以通过一个简单的扑克牌游戏来介绍一些操作列表的方法。下面代码中的注释解释了每次变更后带来的影响。
大约在公元 9 世纪前后,中国发明了扑克牌。在最早的扑克牌中,只有三种花色,分别代表了当时货币的面额:
>>> chinese = ['coin', 'string', 'myriad'] # 一组字符串列表
>>> suits = chinese # 为同一个列表指定了两个不同的变量名当扑克牌(可能是经由埃及)传到欧洲后,西班牙的纸牌中只剩下 coin 这一种花色:
>>> suits.pop() # 从列表中移除并返回最后一个元素
'myriad'
>>> suits.remove('string') # 从列表中移除第一个与参数相同的元素随着时间推移,又额外演变出了另外三种花色:
>>> suits.append('cup') # 在列表最后插入一个元素
>>> suits.extend(['sword', 'club']) # 将另外一个列表中的所有元素添加到当前列表最后同时,意大利人给花色 swords 叫 spades:
>>> suits[2] = 'spade' # 替换某个元素这样我们就得到了一副传统意大利扑克牌的所有花色:
>>> suits
['coin', 'cup', 'spade', 'club']现在美国使用的扑克牌实际上是法国的变种,修改了前两种花色:
>>> suits[0:2] = ['heart', 'diamond'] # 替换一组数据
>>> suits
['heart', 'diamond', 'spade', 'club']除此之外,还有插入、排序、反转列表的方法。所有这些方法都是直接改变了目标列表的值,而不是创建了一个新的列表对象。
尽管两个列表的元素值相同,但他们仍然可能是完全不同的两个列表对象,所以我们需要一个机制来验证两个对象是否相同。Python 提供了 is 和 is not 两种比较操作符来验证两个变量是否指向同一个对象。如果两个对象的值完全相等,则说明它们两个是同一个对象,对其中任意一个对象的改动都将影响到另外一个。身份验证比简单的相等验证更准确。
>>> suits is nest[0]
True
>>> suits is ['heart', 'diamond', 'spade', 'club']
False
>>> suits == ['heart', 'diamond', 'spade', 'club']
True最后两个比较说明了 is 和 == 的区别。前者是检验的是对象的内存地址,而后者只是判断内容是否相同。

我们可以发现上图中的t列表其实是递归的,因为它包含了它自己。同样,输出的列表函数也是递归的,[...]代表了一个基本情况,也就是和前面一样的递归元素。但是从打印出的东西来看它理应是递归的,但是在环境图(内存)中并没有,因为最后一个元素t仅仅是一个指向自己的指针。
接下来我们探讨一个关于切片的小注意事项:
上图的s[0:0]所代表的元素是什么?其实它是一个长度为0的元素切片,因为s中并没有从0 ~ 0的元素,所以它仅仅是代表了一个空列表。
"s[0:0] = t"表示我们要把t中的所有元素插入到s中去。如果我们把"s[0:0]"替换成"s[1:1]"呢?
如果我们使用切片分配,是不可以将整数赋值进列表的,我们可以用正常的方式改变列表。
切片分配的工作原理是从s中提取多个元素,并用t中的元素代替它们。整数8中没有任何元素,这就是我们遇到错误的原因。
我们可以对比一下"s[0]"和"s[0:0]"的区别:

切片分配是把源列表的元素放入目标列表中,而s[0]则是代替,将"[0]"的位置元素替换成了t。元素赋值不会改变原列表的长度,它只是改变了列表里的内容。切片分配改变了列表的长度,用一些新元素替换原来现有的片。
2.3、元组
元组。 元组是指 Python 内置类型 tuple 的实例对象,其是不可变序列。我们可以将不同数据用逗号分隔,用这种字面量的方式即可以创建一个元组。括号并不是必须的,但是一般都会加上。元组中可以放置任意对象。
>>> 1, 2 + 3
(1, 5)
>>> ("the", 1, ("and", "only"))
('the', 1, ('and', 'only'))
>>> type( (10, 20) )
<class 'tuple'>空元组或者只有一个元素的元组,有特定的字面量语法:
>>> () # 0 elements
()
>>> (10,) # 1 element
(10,)和列表相同,元组有确定的长度,并支持元素索引。元组还有一些与列表相同的方法,比如 count 和 index。
>>> code = ("up", "up", "down", "down") + ("left", "right") * 2
>>> len(code)
8
>>> code[3]
'down'
>>> code.count("down")
2
>>> code.index("left")
4但是,列表中那些用于操作列表元素的方法并不适用于元组,因为元组是不可变的。但这意味着可以将它们作为字典中的键。在字典中不允许使用列表作为键,甚至不可以存在一个带有列表的元组。
尽管无法修改元组的元素,但是如果元组中的元素本身是可变数据,那我们也是可以对该元素进行操作的。
我们还应该注意一下如果定义的函数里的参数是可变参数类型(如列表)有什么变化?
上图我们看到,如果函数内部参数是可变的,那么每次调用它都会保留上一次的变化,这是需要注意的!







2.4、局部状态
列表和字典拥有局部状态(local state),即它们可以在程序执行过程中的某个时间点修改自身的值。状态(state)就意味着当前的值有可能发生变化。
函数也是有状态的。举例来说,我们可以定义一个函数,来抽象从银行账户中取钱的过程。我们为这个函数命名为 withdraw,它接收一个参数,代表取钱的金额。如果账户中有足够的金额,withdraw 会返回取完钱以后的余额;否则,withdraw 会返回「余额不足」。假设我们账户里有 100 美元,调用 withdraw 应该得到如下结果:
>>> withdraw(25)
75
>>> withdraw(25)
50
>>> withdraw(60)
'余额不足'
>>> withdraw(15)
35在上面的代码中,表达式 withdraw(25) 被执行了两次,但是返回了不同的结果。因此,我们定义的这个函数不是纯函数(in-pure)。执行这个函数在返回内容的同时,还产生了其它副作用(side effects),导致多次调用同一个函数得到的结果却不相同。这里的副作用之所以会出现,是因为 withdraw 函数更改了它所在的栈帧之外的变量。
>>> withdraw = make_withdraw(100)make_withdraw 的实现需要一种新的声明形式:非局部(nonlocal)声明。当我们调用 make_withdraw 的时候,我们将初始余额声明为 balance 变量,然后我们再定义并返回一个局部函数 withdraw,它会在调用时更新并返回 balance 的值。
>>> def make_withdraw(balance):
"""返回一个每次调用都会减少 balance 的 withdraw 函数"""
def withdraw(amount):
nonlocal balance # 声明 balance 是非局部的
if amount > balance:
return '余额不足'
balance = balance - amount # 重新绑定
return balance
return withdraw当 balance 属性为声明为 nonlocal 后,每当它的值发生更改时,相应的变化都会同步更新到 balance 属性第一次被声明的位置。回想一下,在没有 nonlocal 声明之前,所有对 balance 的重新赋值操作都会在当前环境的第一帧中绑定。非局部语句指示名称不会出现在第一个(局部)帧或最后一个(全局)帧,而是出现在其他地方。
以下运行环境图展示了多次调用由 make_withdraw 创建的函数的效果。


第一个 def 声明的表现符合我们的预期:它创建一个新的自定义函数并将该函数以 make_withdraw 为名绑定到全局帧中。随后调用 make_withdraw 创建并返回一个局部定义的函数 withdraw。参数 balance 则绑定在该函数的父帧中。最重要的是,在这个示例中,变量名 balance 只有一个绑定关系。
接下来,我们调用 make_withdraw 得到函数 wd,然后调用 wd 方法并入参 5。withdraw 函数执行在一个新的环境中,并且该环境的 parent 是定义 withdraw 函数的环境。跟踪 withdraw 的执行,我们可以发现 Python 中 nonlocal 声明的效果:当前执行帧之外的变量可以通过赋值语句更改。
非局部语句(nonlocal statement)会改变 withdraw 函数定义中剩余的所有赋值语句。在将 balance 声明为 nonlocal 后,任何尝试为 balance 赋值的语句,都不会直接在当前帧中寻找并更改 balance,而是找到定义 balance 变量的帧,并在该帧中更新该变量。如果在声明 nonlocal 之前 balance 还没有赋值,则 nonlocal 声明将会报错。
通过改变 balance 的绑定,我们也改变了 withdraw 函数。下一次调用该函数时,变量 balance 的值将会是 15,而不是 20。因此,当我们第二次调用 withdraw 时,返回值将是 12,而不是 17。第一次调用对 balance 的改变会影响到第二次调用的结果。
第二次调用 withdraw 像往常一样创建了第二个局部帧。并且,这两个 withdraw 帧都具有相同的父级帧。也就是说,它们都集成了 make_withdraw 的运行环境,而变量 balance 就是在该环境中定义和声明的。因此,它们都可以访问到 balance 变量的绑定关系。调用 withdraw 会改变当前运行环境,并且影响到下一次调用 withdraw 的结果。nonlocal 声明语句允许 withdraw 更改 make_withdraw 运行帧中的变量。
自从我们第一次遇到嵌套的 def 语句,我们就发现到嵌套定义的函数可以在访问其作用域之外的变量。访问 nonlocal 声明的变量名称并不需要使用非局部语句。相比之下,只有在非局部语句之后,函数才能更改这些帧中名称的绑定。
通过引入非局部语句,我们为赋值语句创建了双重作用。他们可以更改局部绑定 (local bindings),也可以更改非局部绑定 (nonlocal bindings)。事实上,赋值语句已经有了很多作用:它们可以创建新的变量,也可以为现有变量重新赋值。赋值也可以改变列表和字典的内容。我用列表来举个例子:

我们看到列表b被绑定在withdraw函数定义之外,且列表是可变的,这意味着所有的withdraw调用都可以引用同一个b。
Python 特质 (Python Particulars)。这种非局部赋值模式是具有高阶函数和词法作用域的编程语言的普遍特征。大多数其他语言根本不需要非局部语句。相反,非局部赋值通常是赋值语句的默认行为。
Python 在变量名称查找方面也有一个不常见的限制:在一个函数体内,多次出现的同一个变量名必须处于同一个运行帧内。因此,Python 无法在非局部帧中查找某个变量名对应的值,然后在局部帧中为同样名称的变量赋值,因为同名变量会在同一函数的两个不同帧中被访问。此限制允许 Python 在执行函数体之前预先计算哪个帧包含哪个名称。当代码违反了这个限制时,程序会产生令人困惑的错误消息。为了演示,请参考下面这个删掉了 nonlocal 语句的 make_withdraw 示例。
出现此 UnboundLocalError 是因为 balance 在第 5 行中被赋值,因此 Python 假定对 balance 的所有引用也必须出现在当前帧中。这个错误发生在第 5 行执行之前,这意味着 Python 在执行第 3 行之前,就以某种方式考虑了第 5 行的代码。在执行函数体之前预先计算有关函数体的实际情况是很常见的。此时,Python 的预处理限制了 balance 可能出现的帧,从而导致找不到对应的变量名。添加 nonlocal 声明可以修复这个问题。Python 2 中不存在 nonlocal 声明。
我们注意一下"+"和"append"的区别:

在来介绍一个python的小quirk:

对比上面两张图我们可以发现"a + b"和"a += b"在python中所做的操作结果是不一样的!!!
三、迭代器


3.1、字典迭代

①在新版python中(3.6+)字典中的数据是按照我们添加的顺序排的,而之前的旧版本是随机乱序排的。
②字典可以有多种迭代方式,可以根据键值迭代、键值对应的元素值迭代和字典中每一个代表键值对的元组迭代。
下面我们需要有几点注意:

3.2、迭代器的内置功能

def double(x):
print('**' , x, '==>' ,2*x , '**')
return 2*x


四、生成器和生成器函数

def evens(start,end):
even = start + (start % 2) # 确保输入的start从开始便为一个偶数
while even < end:
yield even
even += 2

def countdown(k):
if k > 0:
yield k
yield from countdown(k - 1)
else:
yield 'Blast off'
def prefixs(s):
if s:
yield from prefixs(s[:-1]) # s[:-1]:除去最后一个元素的其余元素,即'bot'
yield s
def substrings(s):
if s:
yield from prefixs(s)
yield from substrings(s[1:])
这里有我们需要注意的点:

我们看到当我们注释了下面内段代码时,输出变成了空列表,这是因为每次我们进入函数都需要迭代一次字串prefixs()函数,这就导致原来的'dogs'字符慢慢迭代成了'd',最后变成了空字符,而我们返回一个在空字符上调用前缀的结果,这不会yield出任何结果(等同于循环到最后是空)。这等同于"yield from []"
如果我们将上面的"countdown()"函数修改一下,yield后的from删去,返回一个针对于函数的生成器。


















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











