









目录
线程
- 进程是资源拥有的基本单位,进程切换需要保存进程状态,会造成资源的消耗。同一进程中的线程,共享进程获取的部分资源。在同一进程中,线程的切换不会引起进程切换,线程的切换需要的资源少于进程切换,可以提高效率。
- 线程是调用CPU资源的最小单位
- KLT 内核级线程(Kemel-Level Threads)
JVM实现方式- 对用户线程的大部分操作都会映射到内核线程上,引起用户态和内核态的频繁切换;
这就是JVM重量级锁系统开销大的原因了 - 多处理器环境中,内核能同时调度同一进程的多线程,将这些线程映射到不同的处理器核心上,提高进程的执行效率;
- 对用户线程的大部分操作都会映射到内核线程上,引起用户态和内核态的频繁切换;
- ULT 用户级线程(User-Level Threads )
- 不需要系统内核支持,所有操作在用户态完成。不会因为用户态和内核态之间的切换带来额外的开销;
- 不能利用多核处理器优点,OS调度进程,每个进程仅有一个ULT能执行;
- 内核对ULT无感知,进程中一个线程阻塞则进程阻塞
包括它所有的线程;
- KLT 内核级线程(Kemel-Level Threads)
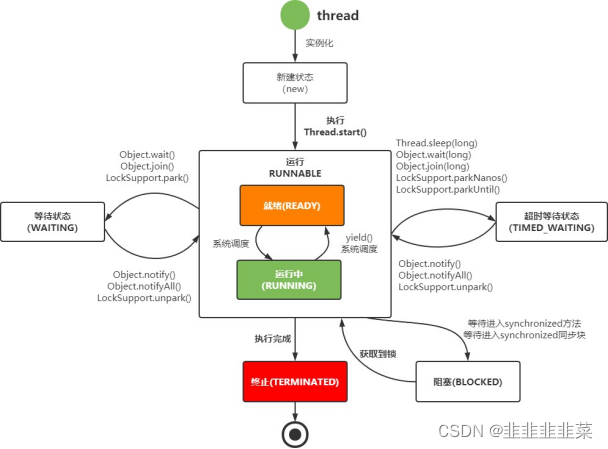
线程状态
- New: 新建状态
new Thread() 刚被创建时候的状态; - Runnable : 可执行状态
线程被创建后调用start()方法进入该状态; - Blocked : 阻塞状态
线程阻塞在进入synchronized关键字修饰的方法或代码块还未获取到锁; - Waiting : 等待状态
调用线程的wait()方法,让线程等待被唤醒; - Timed Waiting : 超时等待
通过调用线程的sleep()或join(),等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态; - Terminated : 终结状态
执行结束或异常退出;
线程池
- 可以重用存在的线程,减少线程创建和消亡的开销,提高性能
- 提高响应速度,任务可以不需要的等到线程创建成功
- 避免线程无限制的创建,对系统造成其它不可控的影响
线程池创建
new ThreadPoolExecutor
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
- corePoolSize : 核心线程数,当核心线程都被占用后,新的任务进来会优先放入workQueue参数定义的阻塞队列中,等待被执行;
- maximumPoolSize : 线程池中允许的最大线程数。如果当前阻塞队列满了,且继续提交任务,如果当前工作线程数小于 maximumPoolSize 则创建新的线程来执行任务;
- keepAliveTime : 线程允许空闲时间,超过该时间线程被销毁;
- unit : keepAliveTime的时间单位;
- workQueue : 用来保存等待被执行的任务的阻塞队列,且任务必须实现Runable接口;
- threadFactory : 用来创建新线程。默认使用Executors.defaultThreadFactory() 来创建线程;
- handler : 线程池的饱和策略,当阻塞队列满了,且当前的工作线程数 = maximumPoolSize,如果继续提交任务,就会执行该策略,有四种策略选项
- AbortPolicy : 抛出异常
默认策略; - CallerRunsPolicy : 用调用者所在的线程来执行任务,也就是由异步变成了同步执行;
- DiscardOldestPolicy : 丢弃阻塞队列中靠最前的任务,并执行当前任务;
- DiscardPolicy : 直接丢弃该任务;
- 也可以根据应用场景实现 RejectedExecutionHandler 接口,自定义饱和策略;
- AbortPolicy : 抛出异常
Executors.newFixedThreadPool
- 快速创建线程池,只需要填写一个核心线程数即可
- 最大线程数与核心线程数设置相等
- 队列采用LinkedBlockingQueue<Runnable
无界队列,但是逻辑上是有界的 不过一般也不可能放满,所以不用太担心拒绝策略的事
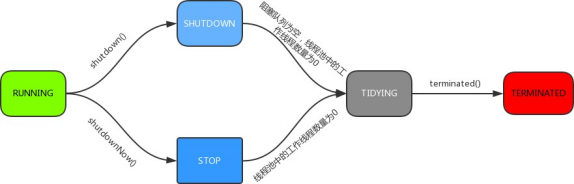
线程池状态
- RUNNING : 初始状态,能够正常接收任务、处理任务;
- SHUTDOWN : 不接收新任务,但能处理已添加的任务;
- STOP : 不接收新任务,不处理已添加的任务,并且会中断正在处理的任务;
- TIDYING : 所有的任务已终止;
- TERMINATED : 线程池彻底终止;
核心方法
- execute() : 核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行;
- submit() : 针对有返回参数的场景,实际上还是调用的execute()方法,同时会利用 Future 来获取任务执行结果;
- shutdown() : 将线程池状态修改为 SHUTDOWN;
- shutdownNow() : 将线程池状态修改为 SHUTDOWN;
- isTerminated() : 是否所有任务都执行完毕了;
- isShutdown() : 判断该线程池是否已被关闭;
监控方法
- getTaskCount() : 线程池已执行与未执行的任务总数;
- getCompletedTaskCount() : 已完成的任务数;
- getPoolSize() : 线程池当前的线程数;
- getActiveCount : 线程池中正在执行任务的线程数量;
Worker
线程池中的线程会被封装成一组 Worker 对象,Worker类继承了 AQS ,使用AQS来实现独占锁的功能。并实现了 Runnable 接口。
线程数设置
- IO密集型(I/O bound)
- 大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操 作,此时CPU Loading并不高。
例如分页查询导出Excel文件; - 线程数 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU核数;
- 大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操 作,此时CPU Loading并不高。
- CPU密集型(CPU-bound)
- 大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound;
- 线程数 = CPU核数+1 (现代CPU支持超线程);
// 获取当前可用的计算资源数
Runtime.getRuntime().availableProcessors();
ForkJoinPool
- 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数;
- 工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行
- .ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的是任务;
- 工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
- 工作线程将自己的任务处理完成后会尝试窃取其他工作线程的任务,窃取的任务使用的是 FIFO 方式,位于其他线程的工作队列的队首。
-适用于超大数据计算、排序等场景;















 5034
5034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











